我在 PostgreSQL 中遇到了超慢查詢的問題。
DB ER圖部分集中在這個問題上:
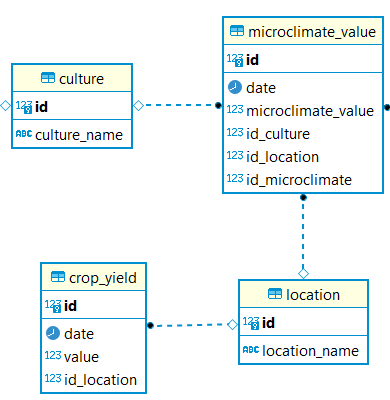
表culture有6條記錄,表microclimate_value有大約190k條記錄,表location有3條記錄,表crop_yield大約有40k條記錄。
查詢:
SELECT max(cy.value) AS yield, EXTRACT(YEAR FROM cy.date) AS year
FROM microclimate_value AS mv
JOIN culture AS c ON mv.id_culture = c.id
JOIN location AS l ON mv.id_location = l.id
JOIN crop_yield AS cy ON l.id = cy.id_location
WHERE c.id = :cultureId AND l.id = :locationId
GROUP BY year
ORDER BY year
對于給定的 :cultureId(來自文化表的主鍵)和 :locationId(來自位置表的主鍵),此查詢應從(crop_yield 表)獲得最大值。它看起來像這樣(crop_yield 表中的yield == value 列):
[
{
"year": 2014,
"yield": 0.0
},
{
"year": 2015,
"yield": 1972.6590590838807
},
{
"year": 2016,
"yield": 3254.6370785040726
},
{
"year": 2017,
"yield": 2335.5804000689095
},
{
"year": 2018,
"yield": 3345.2244602819046
},
{
"year": 2019,
"yield": 3004.7096788680583
},
{
"year": 2020,
"yield": 2920.8721807693764
},
{
"year": 2021,
"yield": 0.0
}
]
增強嘗試:
Initially, this query took around 10 minutes, so there is some big problem with optimization or with the query itself. The first thing I did was indexing foreign keys in microclimate_value and crop_yield table, which resulted in far better performance, but the query still takes 2-3 minutes to execute.
Does anyone have any tip on how to improve this? I am open for any tips, including changing the whole schema if needed, considering the fact I'm still learning SQL.
Thanks in advance!
Edit:
- Adding EXPLAIN PSQL
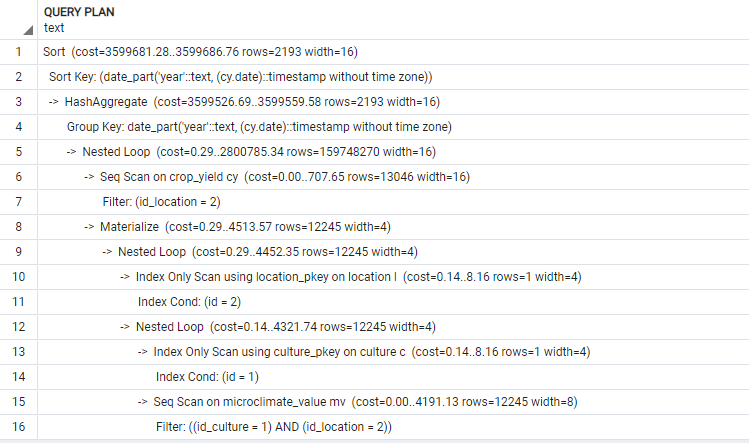
- Adding second EXPLAIN ANALYZE PSQL after adding indexes:

uj5u.com熱心網友回復:
在單個索引中進行一些列組合。我會從這個開始,在搜索資料后擺脫所有過濾:
CREATE INDEX idx_crop_yield_id_location_year_value ON crop_yield(id_location, (EXTRACT ( YEAR FROM DATE )), value);
CREATE INDEX idx_microclimate_value_id_location_id_culture ON microclimate_value(id_location, id_culture);
也許列中的不同順序效果更好,這是您必須找出的東西。
我也會把未使用的表“文化”排除在外:
SELECT MAX( cy.VALUE ) AS yield,
EXTRACT ( YEAR FROM cy.DATE ) AS YEAR
FROM
microclimate_value AS mv
JOIN LOCATION AS l ON mv.id_location = l.ID
JOIN crop_yield AS cy ON l.ID = cy.id_location
WHERE
mv.id_culture = : cultureId
AND l.ID = : locationId
GROUP BY YEAR
ORDER BY YEAR;
每次更改查詢或索引后,再次運行 EXPLAIN(ANALYZE, VERBOSE, BUFFERS)。
uj5u.com熱心網友回復:
根據您的資料explain analyze,有 10,970 行microclimate_valuefor location=2 and id_culture=1。還有 12,316 行location=2in crop_yield。
由于這兩個表的連接沒有其他條件,因此資料庫必須在記憶體中創建一個包含 10,970*12,316=135,106,520 行的表,然后對其結果進行分組。可能需要一些時間……
我認為您在查詢中缺少某些條件。您確定 microclimate_value.date 和crop_yield.date 上的日期不應該相同嗎?因為,恕我直言,沒有它,查詢沒有多大意義。
如果與這些日期沒有聯系,那么在 microclimate_value 中可能有用的唯一資訊是location_id=? and culture_id=?那里是否存在匹配:
select
max(value) as max_value,
extract(year from date) as year,
from crop_yield
where location_id=?
and exists(
select 1
from microclimate_value
where location_id=? and culture_id=?
)
group by year
如果它們在某處匹配,您要么會得到結果,要么不會得到任何結果。這種模式的設計似乎有問題。
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/388197.html
標籤:postgresql spring-data-jpa query-optimization