我正在嘗試通過在熊貓中聚合來找到一種更高級的組的方法。例如:
d = {'name': ['a', 'a', 'b', 'b', 'b', 'c', 'd', 'e'], 'amount': [2, 5, 2, 3, 7, 2, 4, 1]}
df = pd.DataFrame(data=d)
df_per_category = df.groupby(['name']) \
.agg({'amount': ['count', 'sum']}) \
.sort_values(by=[('amount', 'count')], ascending=False)
df_per_category[('amount', 'sum')].plot.barh()
df_per_category
產生:
| 數量 | ||
|---|---|---|
| 數數 | 和 | |
| 名稱 | ||
| 乙 | 3 | 12 |
| 一個 | 2 | 7 |
| C | 1 | 2 |
| d | 1 | 4 |
| 電子 | 1 | 1 |
如果您有一個資料集,其中 70% 的專案只有一個計數,而 30% 有多個計數,那么如果您可以將 70% 分組,那就太好了。首先,簡單起見,只需將所有只有一個計數的記錄分組,并將它們放在一個名稱下,例如other. 所以結果看起來像:
| 數量 | ||
|---|---|---|
| 數數 | 和 | |
| 名稱 | ||
| 乙 | 3 | 12 |
| 一個 | 2 | 7 |
| 其他 | 3 | 7 |
有熊貓的方法來做到這一點嗎?現在我正在考慮回圈遍歷我的聚合結果并手動創建一個新的資料框。
當前解決方案:
name = []
count = []
amount = []
aggregates = {
5: [0, 0],
10: [0, 0],
25: [0, 0],
50: [0, 0],
}
l = list(aggregates)
first_aggregates = l
last_aggregate = l[-1] 1
aggregates.update({last_aggregate: [0, 0]})
def aggregate_small_values(c):
n = c.name
s = c[('amount', 'sum')]
c = c[('amount', 'count')]
if c <= 2:
if s < last_aggregate:
for a in first_aggregates:
if s <= a:
aggregates[a][0] = c
aggregates[a][1] = s
break
else:
aggregates[last_aggregate][0] = c
aggregates[last_aggregate][1] = s
else:
name.append(n)
count.append(c)
amount.append(s)
df_per_category.apply(aggregate_small_values, axis=1)
for a in first_aggregates:
name.append(f'{a} and smaller')
count.append(aggregates[a][0])
amount.append(aggregates[a][1])
name.append(f'{last_aggregate} and bigger')
count.append(aggregates[last_aggregate][0])
amount.append(aggregates[last_aggregate][1])
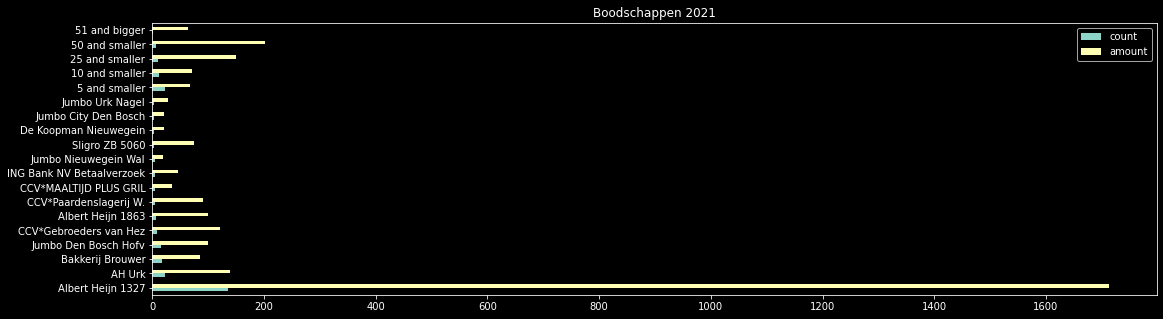
df_agg = pd.DataFrame(index=name, data={'count': count, 'amount': amount})
df_agg.plot.barh(title='Boodschappen 2021')
df_agg
產生類似的東西:
uj5u.com熱心網友回復:
如果需要更換name的other,如果罪名是1使用Series.duplicated具有keep=False:
df.loc[~df['name'].duplicated(keep=False), 'name'] = 'other'
print (df)
name amount
0 a 2
1 a 5
2 b 2
3 b 3
4 b 7
5 other 2
6 other 4
7 other 1
如果需要按百分比替換,這里20%設定otheruse Series.value_countswithnormalize=True然后Series.map用于與原始大小相同的掩碼df:
s = df['name'].value_counts(normalize=True)
print (s)
b 0.375
a 0.250
d 0.125
e 0.125
c 0.125
Name: name, dtype: float64
df.loc[df['name'].map(s).lt(0.2), 'name'] = 'other'
print (df)
name amount
0 a 2
1 a 5
2 b 2
3 b 3
4 b 7
5 other 2
6 other 4
7 other 1
對于按計數過濾,如下所示3:
s = df['name'].value_counts()
print (s)
b 3
a 2
d 1
e 1
c 1
Name: name, dtype: int64
df.loc[df['name'].map(s).lt(3), 'name'] = 'other'
print (df)
name amount
0 other 2
1 other 5
2 b 2
3 b 3
4 b 7
5 other 2
6 other 4
7 other 1
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/392017.html