我有一列,其中每一行都包含一個不同長度的字串串列。我需要創建一個新列,該列包含一個布林值串列(相當于原始串列),用于說明是否在另一個(更大的)串列中找到了每個元素。
這就是我正在做的事情,它顯然不起作用。我基于這個問題:
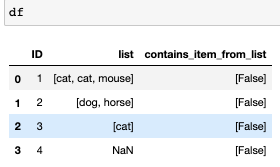
所需的輸出:
ID list contains_item_from_list
1 [cat,cat,mouse] [True, True, True]
2 [dog,horse] [True, False]
3 [cat] [True]
4 NaN [False]
uj5u.com熱心網友回復:
explode展平系列中的所有串列,但同一串列中的專案都共享與它們來自的串列相同的索引,因此在您使用isin檢查main_list系列中的哪些專案后,您可以使用groupbywithlevel=0進行分組索引的第 0(第一)級,然后將它們轉換回串列:
df['contains_item_from_list'] = df['list'].explode().isin(main_list).groupby(level=0).apply(list)
輸出:
>>> df
0 [True, True, True]
1 [True, False]
2 [True]
3 [False]
Name: list, dtype: object
uj5u.com熱心網友回復:
你可以做explode,然后isin
df['new'] = df['list'].explode().isin(main_list).groupby(level=0).any()
df
Out[130]:
ID list new
0 1 [cat, cat, mouse] True
1 2 [dog, horse] True
2 3 [cat] True
3 4 NaN False
更新
df['new'] = df['list'].explode().isin(main_list).groupby(level=0).agg(list)
df
Out[132]:
ID list new
0 1 [cat, cat, mouse] [True, True, True]
1 2 [dog, horse] [True, False]
2 3 [cat] [True]
3 4 NaN [False]
uj5u.com熱心網友回復:
您還可以應用一個函式來遍歷list. 這應該比爆炸列更快:
main_set = set(main_list)
df["contains_item_from_list"] = df['list'].apply(lambda x: [w in main_set for w in x] if isinstance(x, list) else [x in main_set])
輸出:
ID list contains_item_from_list
0 1 [cat, cat, mouse] [True, True, True]
1 2 [dog, horse] [True, False]
2 3 [cat] [True]
3 4 NaN [False]
uj5u.com熱心網友回復:
使用串列理解,簡單快捷
df["contains_item_from_list"]= df['list'].fillna('xx').apply(lambda x: [val in main_list for val in x])
ID list contains_item_from_list
0 1 [cat, cat, mouse] [True, True, True]
1 2 [dog, horse] [True, False]
2 3 [cat] [True]
3 4 NaN [False]
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/392027.html