我有一個包含 2 列的 csv 檔案。一列有字串有毒評論,另一列有浮動毒性值 0 到 1。(當毒性值接近 1 時,評論變得更有毒)。
我想做線性回歸以正確預測毒性值的數量。
為此,首先我將“評論”(字串)列轉換為這樣的整數:
train['comment']= pd.to_numeric(train['comment'], errors='coerce').fillna(0).astype(np.int64)
然后,我為線性回歸撰寫了該代碼:
linX = train.iloc[:, 0].values.reshape(-1,1)
linY = train.iloc[:, 1].values.reshape(-1,1)
lr = LinearRegression()
lr.fit(linX, linY)
Y_pred = lr.predict(linX)
plt.scatter(linX,linY)
plt.plot(linX,Y_pred, color='red')
那行得通,但我認為我做得不對。因為那個回歸表對我來說似乎不正確:
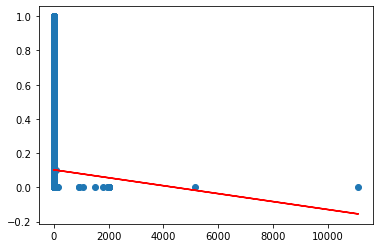
我無法解決問題。我的問題是;
我針對這個問題的線性回歸代碼對嗎?
我應該將“毒性”列與 0 值分開嗎?
uj5u.com熱心網友回復:
我不確定使用下面的代碼將字串轉換為數值是否會回傳您正在尋找的結果。
pd.to_numeric(train['comment'], errors='coerce')
此代碼僅更改字串注釋的變數型別。字串注釋無法轉換為整數。coerce 可選引數使字串轉換為 NaN 值,而 NaN 值使用 fillna 轉換為零。
要使用機器學習技術解決文本分類問題,您需要使用TF-IDF等技術預處理資料。
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/392740.html