我正在為 matplotlib (blume) 的表格苦苦掙扎。該表適用于將生成 22 張不同地圖的自動化專案。下面的代碼生成一個有 49 行的表。有些數字只有 6 行。當行數超過 25 時,我想使用兩列。
import pandas as pd
import matplotlib.pyplot as plt
from blume.table import table
# Dataframe
df=pd.DataFrame({'nr': [ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,
18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34,
35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49],
'KnNamn': ['H?rryda', 'Partille', '?cker?', 'Stenungsund', 'Tj?rn', 'Orust',
'Soten?s', 'Munkedal', 'Tanum', 'Dals-Ed', 'F?rgelanda', 'Ale',
'Lerum', 'V?rg?rda', 'Bollebygd', 'Gr?storp', 'Essunga',
'Karlsborg', 'Gullsp?ng', 'Tranemo', 'Bengtsfors', 'Mellerud',
'Lilla Edet', 'Mark', 'Svenljunga', 'Herrljunga', 'Vara', 'G?tene',
'Tibro', 'T?reboda', 'G?teborg', 'M?lndal', 'Kung?lv', 'Lysekil',
'Uddevalla', 'Str?mstad', 'V?nersborg', 'Trollh?ttan', 'Alings?s',
'Bor?s', 'Ulricehamn', '?m?l', 'Mariestad', 'Lidk?ping', 'Skara',
'Sk?vde', 'Hjo', 'Tidaholm', 'Falk?ping'],
'rel': [0.03650425, 0.05022105, 0.03009109, 0.03966735, 0.02793296,
0.03690838, 0.04757161, 0.05607283, 0.0546372 , 0.05452821,
0.06640368, 0.04252673, 0.03677577, 0.05385784, 0.0407173 ,
0.04024881, 0.05613226, 0.04476127, 0.08543165, 0.04070175,
0.09281077, 0.08711656, 0.06111578, 0.04564958, 0.05058988,
0.04618078, 0.04640402, 0.04826498, 0.08514253, 0.07799246,
0.07829886, 0.04249149, 0.03909206, 0.06835601, 0.08027622,
0.07087295, 0.09013876, 0.1040369 , 0.05004451, 0.06584845,
0.04338739, 0.10570863, 0.0553109 , 0.05024871, 0.06531729,
0.05565605, 0.05041816, 0.04885198, 0.07954831]})
# Table
fig,ax = plt.subplots(1, figsize=(10, 7))
val =[]
ax.axis('off')
for i, j, k in zip(df.nr, df.KnNamn, df.rel):
k = k*100
k = round(k,2)
k= (str(k) ' %')
temp=str(i) '. ' str(j) ': ' str(k)
val.append(temp)
val=[[el] for el in val]
#val=val[0] val[1]
tab=table(ax,cellText=val,
#rowLabels=row_lab,
colLabels=['Relativ arbetsl?shet'], loc='left', colWidths=[0.3], cellLoc='left')
plt.show()
據我了解,如果我想要一個包含兩列的表,我的 val 物件應該以不同的方式構建。在上面的例子中,val 是一個嵌套串列,里面有 49 個串列。我想我需要合并串列。我試過這個成對的 for 回圈,但對范圍不起作用?
我確信我遇到的這個問題有一個簡單的解決方案。幫助將不勝感激。
for i, j in zip(range(len(val)), range(len(val))[1:] range(len(val))[:1]):
print(i, j)
uj5u.com熱心網友回復:
我不知道這是否是你所需要的,但你可以使用zip()更好的或itertools.zip_longest()與val[:25], val[25:]
two_columns = []
for col1, col2 in itertools.zip_longest(values[:25], values[25:], fillvalue=''):
#print(f'{col1:25} | {col2}')
two_columns.append([col1, col2])
完整的作業示例
import pandas as pd
import matplotlib.pyplot as plt
from blume.table import table
import itertools
df = pd.DataFrame({
'nr': [
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,
18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34,
35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49
],
'KnNamn': [
'H?rryda', 'Partille', '?cker?', 'Stenungsund', 'Tj?rn', 'Orust',
'Soten?s', 'Munkedal', 'Tanum', 'Dals-Ed', 'F?rgelanda', 'Ale',
'Lerum', 'V?rg?rda', 'Bollebygd', 'Gr?storp', 'Essunga',
'Karlsborg', 'Gullsp?ng', 'Tranemo', 'Bengtsfors', 'Mellerud',
'Lilla Edet', 'Mark', 'Svenljunga', 'Herrljunga', 'Vara', 'G?tene',
'Tibro', 'T?reboda', 'G?teborg', 'M?lndal', 'Kung?lv', 'Lysekil',
'Uddevalla', 'Str?mstad', 'V?nersborg', 'Trollh?ttan', 'Alings?s',
'Bor?s', 'Ulricehamn', '?m?l', 'Mariestad', 'Lidk?ping', 'Skara',
'Sk?vde', 'Hjo', 'Tidaholm', 'Falk?ping'
],
'rel': [
0.03650425, 0.05022105, 0.03009109, 0.03966735, 0.02793296,
0.03690838, 0.04757161, 0.05607283, 0.0546372 , 0.05452821,
0.06640368, 0.04252673, 0.03677577, 0.05385784, 0.0407173 ,
0.04024881, 0.05613226, 0.04476127, 0.08543165, 0.04070175,
0.09281077, 0.08711656, 0.06111578, 0.04564958, 0.05058988,
0.04618078, 0.04640402, 0.04826498, 0.08514253, 0.07799246,
0.07829886, 0.04249149, 0.03909206, 0.06835601, 0.08027622,
0.07087295, 0.09013876, 0.1040369 , 0.05004451, 0.06584845,
0.04338739, 0.10570863, 0.0553109 , 0.05024871, 0.06531729,
0.05565605, 0.05041816, 0.04885198, 0.07954831
]
})
# df = df[:25] # test for 25 rows
# ---
fig, ax = plt.subplots(1, figsize=(10, 7))
ax.axis('off')
# --- values ---
#values = []
#for number, name, rel in zip(df.nr, df.KnNamn, df.rel):
# text = f'{number}. {name}: {rel*100:.2} %'
# values.append(text)
values = df.apply(lambda row: f'{row["nr"]}. {row["KnNamn"]}: {row["rel"]*100:.2} %', axis=1).values
# --- columns ---
if len(values) > 25:
two_columns = []
for col1, col2 in itertools.zip_longest(values[:25], values[25:], fillvalue=''):
#print(f'{col1:25} | {col2}')
two_columns.append([col1, col2])
tab = table(ax, cellText=two_columns,
#rowLabels=row_lab,
colLabels=['Col1', 'Col2'], colWidths=[0.3, 0.3], loc=-100, cellLoc='left')
else:
one_column = [[item] for item in values]
tab = table(ax, cellText=one_column,
#rowLabels=row_lab,
colLabels=['Col1'], colWidths=[0.3], loc=-100, cellLoc='left')
# --- plot ---
plt.show()
結果:
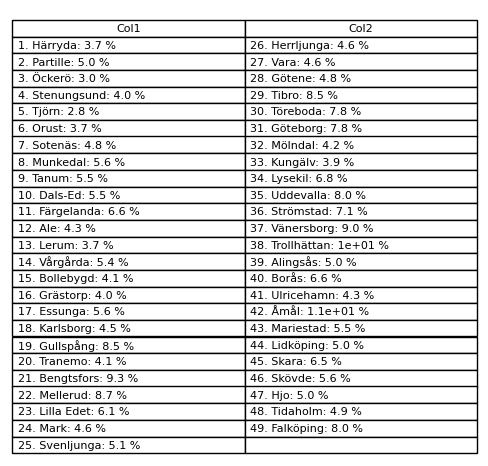
編輯:
更通用的版本,可以創建許多列。
示例自動為ROWS = 20.創建 3 列。
import pandas as pd
import matplotlib.pyplot as plt
from blume.table import table
import itertools
df = pd.DataFrame({
'nr': [
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,
18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34,
35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49
],
'KnNamn': [
'H?rryda', 'Partille', '?cker?', 'Stenungsund', 'Tj?rn', 'Orust',
'Soten?s', 'Munkedal', 'Tanum', 'Dals-Ed', 'F?rgelanda', 'Ale',
'Lerum', 'V?rg?rda', 'Bollebygd', 'Gr?storp', 'Essunga',
'Karlsborg', 'Gullsp?ng', 'Tranemo', 'Bengtsfors', 'Mellerud',
'Lilla Edet', 'Mark', 'Svenljunga', 'Herrljunga', 'Vara', 'G?tene',
'Tibro', 'T?reboda', 'G?teborg', 'M?lndal', 'Kung?lv', 'Lysekil',
'Uddevalla', 'Str?mstad', 'V?nersborg', 'Trollh?ttan', 'Alings?s',
'Bor?s', 'Ulricehamn', '?m?l', 'Mariestad', 'Lidk?ping', 'Skara',
'Sk?vde', 'Hjo', 'Tidaholm', 'Falk?ping'
],
'rel': [
0.03650425, 0.05022105, 0.03009109, 0.03966735, 0.02793296,
0.03690838, 0.04757161, 0.05607283, 0.0546372 , 0.05452821,
0.06640368, 0.04252673, 0.03677577, 0.05385784, 0.0407173 ,
0.04024881, 0.05613226, 0.04476127, 0.08543165, 0.04070175,
0.09281077, 0.08711656, 0.06111578, 0.04564958, 0.05058988,
0.04618078, 0.04640402, 0.04826498, 0.08514253, 0.07799246,
0.07829886, 0.04249149, 0.03909206, 0.06835601, 0.08027622,
0.07087295, 0.09013876, 0.1040369 , 0.05004451, 0.06584845,
0.04338739, 0.10570863, 0.0553109 , 0.05024871, 0.06531729,
0.05565605, 0.05041816, 0.04885198, 0.07954831
]
})
#df = df[:25] # test for 25 rows
# ---
fig, ax = plt.subplots(1, figsize=(10, 7))
ax.axis('off')
# --- values ---
def convert(row):
return f'{row["nr"]}. {row["KnNamn"]}: {row["rel"]*100:.2} %'
values = df.apply(convert, axis=1).values
# --- columns ---
ROWS = 20
#ROWS = 25
columns = []
for idx in range(0, len(values), ROWS):
columns.append(values[idx:idx ROWS])
columns_widths = [0.3] * len(columns)
columns_labels = [f'Col{i}' for i in range(1, len(columns) 1)]
rows = list(itertools.zip_longest(*columns, fillvalue=''))
# --- plot ---
tab = table(ax,
cellText=rows,
#rowLabels=row_lab,
colLabels=columns_labels,
colWidths=columns_widths,
loc=-100,
cellLoc='left')
plt.show()
結果:
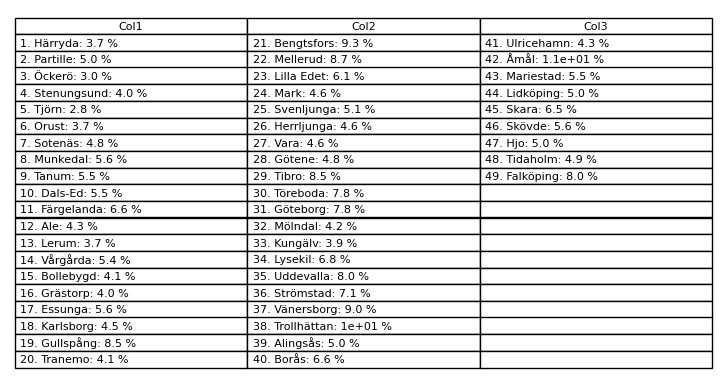
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/394388.html
標籤:Python matplotlib