SQL Server 中有 3 個資料量很大的表,每個表包含大約100000行。有一個 SQL 可以從三個表中獲取行。它的性能非常糟糕。
WITH t1 AS
(
SELECT
LeadId, dbo.get_item_id(Log) AS ItemId, DateCreated AS PriceDate
FROM
(SELECT
t.ID, t.LeadID, t.Log, t.DateCreated, f.AskingPrice
FROM
t
JOIN
f ON f.PKID = t.LeadID
WHERE
t.Log LIKE '%xxx%') temp
)
SELECT COUNT(1)
FROM t1
JOIN s ON s.ItemID = t1.ItemId
在檢查其估計的執行計劃時,我發現它使用了大行的嵌套回圈連接。看看下面的截圖。圖中頂部回傳124277行,底部執行124277次!我想這就是為什么它這么慢。
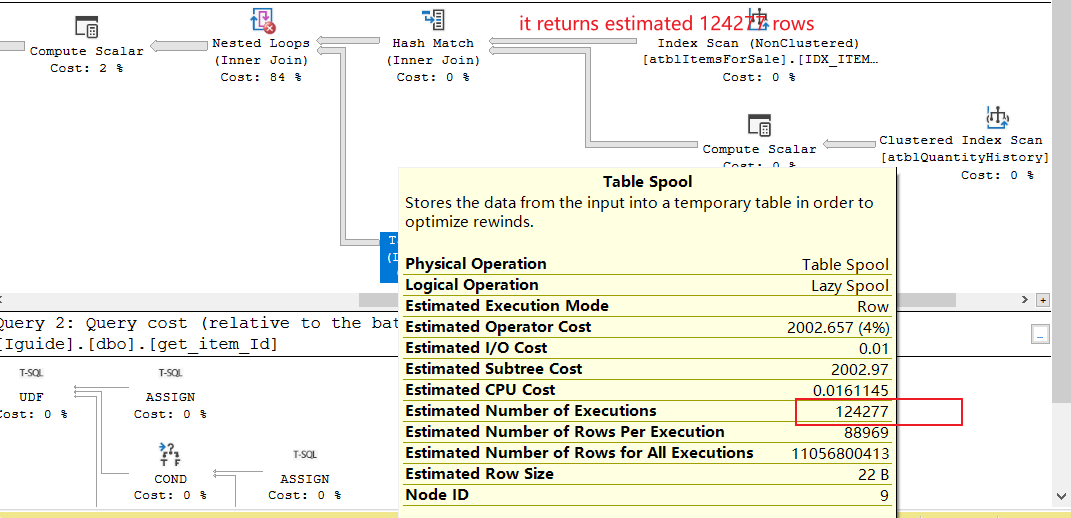
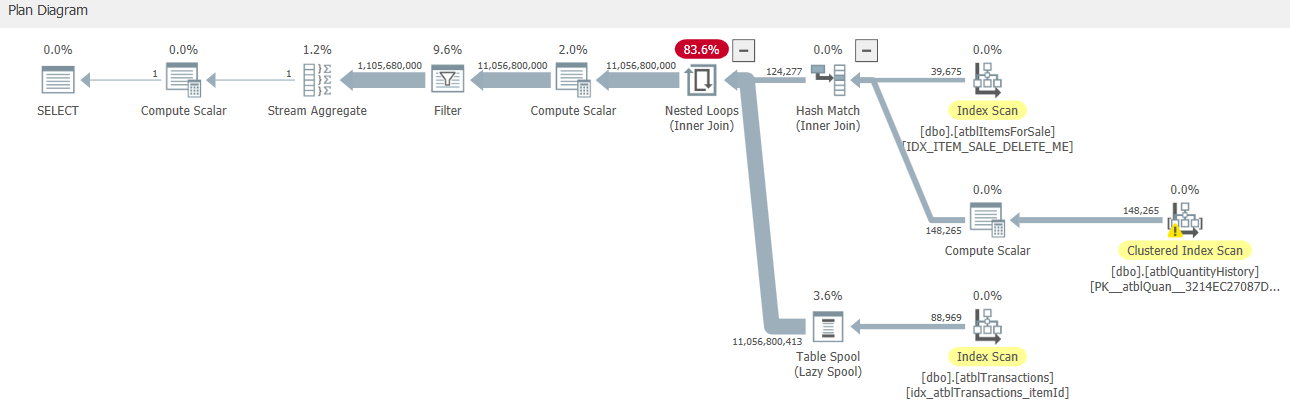
我們知道嵌套回圈在處理大資料時存在很大的性能問題。如何洗掉它,并改用哈希連接或其他連接?
編輯:以下是相關功能。
CREATE FUNCTION [dbo].[get_item_Id](@message VARCHAR(200))
RETURNS VARCHAR(200) AS
BEGIN
DECLARE @result VARCHAR(200),
@index int
--Sold in eBay (372827580038).
SELECT @index = PatIndex('%([0-9]%)%', @message)
IF(@index = 0)
SELECT @result='';
ELSE
SELECT @result= REPLACE(REPLACE(REPLACE(SUBSTRING(@message, PatIndex('%([0-9]%)%', @message),8000), '.', ''),'(',''),')','')
-- Return the result of the function
RETURN @result
END;
uj5u.com熱心網友回復:
出于某種原因,它決定先s cross join t1評估函式(結果別名為 Expr1002),然后對 [s].[ItemID]=[Expr1002] 進行過濾(而不是進行 equi join)。
它估計它將有88,969和124,277行進入交叉連接(這意味著它會產生11,056,800,413)
在交叉連接估計 110 億次后執行標量 UDF,然后過濾估計的 110 億行確實看起來很瘋狂。如果在連接之前對它進行評估,它將被評估的次數少得多,并且也將是等連接,因此也可以使用HASH或MERGE內部連接,并且只需讀取一次所有表而不會增加行數。
我在本地復制了這個,并且在創建 UDF 時行為發生了變化WITH SCHEMABINDING- SQL Server 將看到它不訪問任何表,并且它的定義是確定性的。
跟蹤標志8606輸出似乎支持這是問題所在。在這兩種情況下,“簡化樹”階段將查詢表示為與 ScalarUdf 上的謂詞的交叉連接。標量 UDF 被注釋為“IsDet”或“IsNonDet”,具體取決于函式是否系結模式。在前一種情況下,“專案規范化”階段在連接之前將計算推回原位,并為其提供在連接本身中參考的別名,在非確定性情況下,這不會發生。
我強烈建議擺脫這個標量函式并用行內版本替換它,盡管非行內標量函式除此之外還有許多眾所周知的額外性能問題。
新功能將是
CREATE FUNCTION get_item_Id_inline (@message VARCHAR(200))
RETURNS TABLE
AS
RETURN
(SELECT item_Id = CASE
WHEN PatIndex('%([0-9]%)%', @message) = 0 THEN ''
ELSE REPLACE(REPLACE(REPLACE(SUBSTRING(@message, PatIndex('%([0-9]%)%', @message), 8000), '.', ''), '(', ''), ')', '')
END)
并重寫查詢
WITH t1
AS (SELECT t.LeadID,
i.item_Id AS ItemId,
t.DateCreated AS PriceDate
FROM t
CROSS apply dbo.get_item_Id_inline(t.Log) i
JOIN f
ON f.PKID = t.LeadID
WHERE t.Log LIKE '%xxx%')
SELECT COUNT(1)
FROM t1
JOIN s
ON s.ItemID = t1.ItemId
可能仍有一些額外優化的空間,但這將比您當前的執行計劃好幾個數量級(因為那是災難性的糟糕)。
uj5u.com熱心網友回復:
要優化查詢,請執行以下操作:
- 將“t.Log LIKE condition '% xxx%'”帶到更內部的選擇中。這允許連接中包含更少的記錄。
- 不要使用“喜歡”。
- 洗掉視圖中的頂部選擇。
- 優化“dbo.get_item_id”函式或使用替代解決方案,因為此函式內的比較也非常耗時。
最后,您的查詢將類似于以下代碼:
WITH t1 AS
(
SELECT
u.ID
, u.LeadID as LeadId
, dbo.get_item_id(u.Log) AS ItemId
, u.DateCreated AS PriceDate
, f.AskingPrice
FROM
(select ID, LeadID, Log, DateCreated from t WHERE Log LIKE '%xxx%')u
JOIN
f ON f.PKID = u.LeadID
)
SELECT COUNT(1)
FROM t1
JOIN s ON s.ItemID = t1.ItemId'
uj5u.com熱心網友回復:
對大結果進行“計數”從來都不是一個好主意。此外,您還有LIKE '%xxx%',這始終會導致完整掃描并且優化引擎無法預測。
它知道,這是一種昂貴的方式,但我會重新設計應用程式。也許添加一些觸發器和去規范化資料結構可能是一個很好的解決方案。
uj5u.com熱心網友回復:
如果您仍想使用 get_item_Id UDF。
這是它的高爾夫編碼確定性版本。
CREATE FUNCTION [dbo].[get_item_Id](@message VARCHAR(200))
RETURNS VARCHAR(20)
WITH SCHEMABINDING
AS
BEGIN
DECLARE @str VARCHAR(20);
SET @str = SUBSTRING(@message, PATINDEX('%([0-9]%',@message) 1, 20);
IF @str NOT LIKE '[0-9]%[0-9])%' RETURN NULL;
RETURN LEFT(@str, PATINDEX('%[0-9])%', @str));
END;
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/397726.html
標籤:sql sql-server sql-server-2012 嵌套循环 数据库性能
下一篇:使用輸入引數從包中呼叫所需的程序