我有一個看起來像這樣的表:
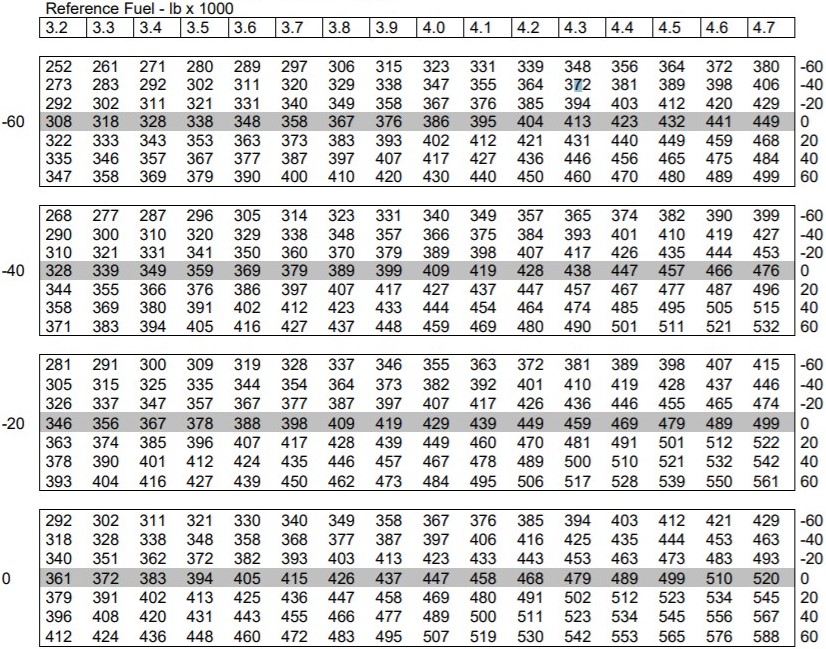
在表格中,左側標簽-60 -40 -20 0是direction_1風分量,是您通常進入表格的位置。標題是reference_fuel和是3.2 3.3 3.4等等。在右側,列出的數字是direction_2風分量。
左邊的風分量是針對某個方向飛行的飛機direction_1。右邊的風分量是針對不同方向的同一架飛機direction_2。
所述reference_fuel頂部和所述兩個風分量是來該表之前已知。
舉個例子:我有一個reference_fuel的4.7,一個direction_1風-20和direction_2風40。我的答案是542。
我想弄清楚的是是否可以將這種樣式的表格與 Pandas 一起使用。我需要把桌子分成不同的桌子嗎?是否有可能進行插值,如果我有direction_1風-50和direction_2風30?
我希望能夠明顯地保持表格完整,而不必將其拆分為不同的檔案。我是這種作業的新手,所以只是想了解一下。謝謝你。
如果有人愿意,這是表格的復制文本:
3.2 3.3 3.4 3.5 3.6 3.7 3.8 3.9 4.0 4.1 4.2 4.3 4.4 4.5 4.6 4.7
-60
252 261 271 280 289 297 306 315 323 331 339 348 356 364 372 380 -60
273 283 292 302 311 320 329 338 347 355 364 372 381 389 398 406 -40
292 302 311 321 331 340 349 358 367 376 385 394 403 412 420 429 -20
308 318 328 338 348 358 367 376 386 395 404 413 423 432 441 449 0
322 333 343 353 363 373 383 393 402 412 421 431 440 449 459 468 20
335 346 357 367 377 387 397 407 417 427 436 446 456 465 475 484 40
347 358 369 379 390 400 410 420 430 440 450 460 470 480 489 499 60
-40
268 277 287 296 305 314 323 331 340 349 357 365 374 382 390 399 -60
290 300 310 320 329 338 348 357 366 375 384 393 401 410 419 427 -40
310 321 331 341 350 360 370 379 389 398 407 417 426 435 444 453 -20
328 339 349 359 369 379 389 399 409 419 428 438 447 457 466 476 0
344 355 366 376 386 397 407 417 427 437 447 457 467 477 487 496 20
358 369 380 391 402 412 423 433 444 454 464 474 485 495 505 515 40
371 383 394 405 416 427 437 448 459 469 480 490 501 511 521 532 60
-20
281 291 300 309 319 328 337 346 355 363 372 381 389 398 407 415 -60
305 315 325 335 344 354 364 373 382 392 401 410 419 428 437 446 -40
326 337 347 357 367 377 387 397 407 417 426 436 446 455 465 474 -20
346 356 367 378 388 398 409 419 429 439 449 459 469 479 489 499 0
363 374 385 396 407 417 428 439 449 460 470 481 491 501 512 522 20
378 390 401 412 424 435 446 457 467 478 489 500 510 521 532 542 40
393 404 416 427 439 450 462 473 484 495 506 517 528 539 550 561 60
0
292 302 311 321 330 340 349 358 367 376 385 394 403 412 421 429 -60
318 328 338 348 358 368 377 387 397 406 416 425 435 444 453 463 -40
340 351 362 372 382 393 403 413 423 433 443 453 463 473 483 493 -20
361 372 383 394 405 415 426 437 447 458 468 479 489 499 510 520 0
379 391 402 413 425 436 447 458 469 480 491 502 512 523 534 545 20
396 408 420 431 443 455 466 477 489 500 511 523 534 545 556 567 40
412 424 436 448 460 472 483 495 507 519 530 542 553 565 576 588 60
uj5u.com熱心網友回復:
您可以使用MultiIndexofdir_1和將資料保存在熊貓資料框中dir_2。
要進行插值,您需要將此 2D 結構重新組織為 3D 陣列,然后您可以使用 scipy's inpterpn:
import pandas as pd
import numpy as np
from scipy.interpolate import interpn
data = {'dir_1': [-60, -60, -60, -60, -60, -60, -60, -40, -40, -40, -40, -40, -40, -40, -20, -20, -20, -20, -20, -20, -20, 0, 0, 0, 0, 0, 0, 0],
'3.2': [252, 273, 292, 308, 322, 335, 347, 268, 290, 310, 328, 344, 358, 371, 281, 305, 326, 346, 363, 378, 393, 292, 318, 340, 361, 379, 396, 412],
'3.3': [261, 283, 302, 318, 333, 346, 358, 277, 300, 321, 339, 355, 369, 383, 291, 315, 337, 356, 374, 390, 404, 302, 328, 351, 372, 391, 408, 424],
'3.4': [271, 292, 311, 328, 343, 357, 369, 287, 310, 331, 349, 366, 380, 394, 300, 325, 347, 367, 385, 401, 416, 311, 338, 362, 383, 402, 420, 436],
'3.5': [280, 302, 321, 338, 353, 367, 379, 296, 320, 341, 359, 376, 391, 405, 309, 335, 357, 378, 396, 412, 427, 321, 348, 372, 394, 413, 431, 448],
'3.6': [289, 311, 331, 348, 363, 377, 390, 305, 329, 350, 369, 386, 402, 416, 319, 344, 367, 388, 407, 424, 439, 330, 358, 382, 405, 425, 443, 460],
'3.7': [297, 320, 340, 358, 373, 387, 400, 314, 338, 360, 379, 397, 412, 427, 328, 354, 377, 398, 417, 435, 450, 340, 368, 393, 415, 436, 455, 472],
'3.8': [306, 329, 349, 367, 383, 397, 410, 323, 348, 370, 389, 407, 423, 437, 337, 364, 387, 409, 428, 446, 462, 349, 377, 403, 426, 447, 466, 483],
'3.9': [315, 338, 358, 376, 393, 407, 420, 331, 357, 379, 399, 417, 433, 448, 346, 373, 397, 419, 439, 457, 473, 358, 387, 413, 437, 458, 477, 495],
'4.0': [323, 347, 367, 386, 402, 417, 430, 340, 366, 389, 409, 427, 444, 459, 355, 382, 407, 429, 449, 467, 484, 367, 397, 423, 447, 469, 489, 507],
'4.1': [331, 355, 376, 395, 412, 427, 440, 349, 375, 398, 419, 437, 454, 469, 363, 392, 417, 439, 460, 478, 495, 376, 406, 433, 458, 480, 500, 519],
'4.2': [339, 364, 385, 404, 421, 436, 450, 357, 384, 407, 428, 447, 464, 480, 372, 401, 426, 449, 470, 489, 506, 385, 416, 443, 468, 491, 511, 530],
'4.3': [348, 372, 394, 413, 431, 446, 460, 365, 393, 417, 438, 457, 474, 490, 381, 410, 436, 459, 481, 500, 517, 394, 425, 453, 479, 502, 523, 542],
'4.4': [356, 381, 403, 423, 440, 456, 470, 374, 401, 426, 447, 467, 485, 501, 389, 419, 446, 469, 491, 510, 528, 403, 435, 463, 489, 512, 534, 553],
'4.5': [364, 389, 412, 432, 449, 465, 480, 382, 410, 435, 457, 477, 495, 511, 398, 428, 455, 479, 501, 521, 539, 412, 444, 473, 499, 523, 545, 565],
'4.6': [372, 398, 420, 441, 459, 475, 489, 390, 419, 444, 466, 487, 505, 521, 407, 437, 465, 489, 512, 532, 550, 421, 453, 483, 510, 534, 556, 576],
'4.7': [380, 406, 429, 449, 468, 484, 499, 399, 427, 453, 476, 496, 515, 532, 415, 446, 474, 499, 522, 542, 561, 429, 463, 493, 520, 545, 567, 588],
'dir_2': [-60, -40, -20, 0, 20, 40, 60, -60, -40, -20, 0, 20, 40, 60, -60, -40, -20, 0, 20, 40, 60, -60, -40, -20, 0, 20, 40, 60]}
df = pd.DataFrame(data).set_index(['dir_1', 'dir_2'])
df.columns = df.columns.map(float)
df.columns.name = 'fuel'
您的資料框df:
fuel 3.2 3.3 3.4 3.5 3.6 3.7 3.8 3.9 4.0 4.1 4.2 4.3 4.4 4.5 4.6 4.7
dir_1 dir_2
-60 -60 252 261 271 280 289 297 306 315 323 331 339 348 356 364 372 380
-40 273 283 292 302 311 320 329 338 347 355 364 372 381 389 398 406
-20 292 302 311 321 331 340 349 358 367 376 385 394 403 412 420 429
0 308 318 328 338 348 358 367 376 386 395 404 413 423 432 441 449
20 322 333 343 353 363 373 383 393 402 412 421 431 440 449 459 468
40 335 346 357 367 377 387 397 407 417 427 436 446 456 465 475 484
60 347 358 369 379 390 400 410 420 430 440 450 460 470 480 489 499
-40 -60 268 277 287 296 305 314 323 331 340 349 357 365 374 382 390 399
-40 290 300 310 320 329 338 348 357 366 375 384 393 401 410 419 427
-20 310 321 331 341 350 360 370 379 389 398 407 417 426 435 444 453
0 328 339 349 359 369 379 389 399 409 419 428 438 447 457 466 476
20 344 355 366 376 386 397 407 417 427 437 447 457 467 477 487 496
40 358 369 380 391 402 412 423 433 444 454 464 474 485 495 505 515
60 371 383 394 405 416 427 437 448 459 469 480 490 501 511 521 532
-20 -60 281 291 300 309 319 328 337 346 355 363 372 381 389 398 407 415
-40 305 315 325 335 344 354 364 373 382 392 401 410 419 428 437 446
-20 326 337 347 357 367 377 387 397 407 417 426 436 446 455 465 474
0 346 356 367 378 388 398 409 419 429 439 449 459 469 479 489 499
20 363 374 385 396 407 417 428 439 449 460 470 481 491 501 512 522
40 378 390 401 412 424 435 446 457 467 478 489 500 510 521 532 542
60 393 404 416 427 439 450 462 473 484 495 506 517 528 539 550 561
0 -60 292 302 311 321 330 340 349 358 367 376 385 394 403 412 421 429
-40 318 328 338 348 358 368 377 387 397 406 416 425 435 444 453 463
-20 340 351 362 372 382 393 403 413 423 433 443 453 463 473 483 493
0 361 372 383 394 405 415 426 437 447 458 468 479 489 499 510 520
20 379 391 402 413 425 436 447 458 469 480 491 502 512 523 534 545
40 396 408 420 431 443 455 466 477 489 500 511 523 534 545 556 567
60 412 424 436 448 460 472 483 495 507 519 530 542 553 565 576 588
重組為 3D 形狀陣列(7, 16, 4):
arr = np.dstack(np.array_split(df.to_numpy(), 4)) # split into 4 arrays along first axis and stack in depth
dir_2 = df.index.get_level_values(1).unique().to_numpy() # axis 0
fuel = df.columns.to_numpy() # axis 1
dir_1 = df.index.get_level_values(0).unique().to_numpy() # axis 2
查詢或插值:
print(interpn((dir_2, fuel, dir_1), arr, [40, 4.7, -20]))
# array([542.])
print(interpn((dir_2, fuel, dir_1), arr, [30, 4.7, -50]))
# array([490.75])
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/397946.html