我有一列包含表XX中的值,如下所示
| 檔案名 |
|---|
| my_String1_20220103_144415.csv |
| my_String2_20220106_155730.csv |
| my_String3_20220108_153930.csv |
| my_String4_20220103_144470.csv |
| my_String5_20220103_144415.csv |
我的問題是如何在最后兩個 '_' 后通過點 '.' 檢索字串。
有這樣的輸出
| 檔案名 |
|---|
| my_String1.csv |
| my_String2.csv |
| my_String3.csv |
| my_String4.csv |
| my_String5.csv |
我試過這個查詢:
select substring(file_name from '(.*)_') as file_name from tableXX
uj5u.com熱心網友回復:
您可以使用
select REGEXP_REPLACE(file_name, '^([^_]*_[^_]*).*(\.[^.]*)$', '\1\2') as file_name from tableXX
在^([^_]*_[^_]*).*(\.[^.]*)$正則運算式匹配
^- 字串的開始([^_]*_[^_]*)- 第 1 組(\1指替換模式中的該組值):除_, a之外的任何零個或多個字符_,再次零個或多個非_s.*- 盡可能多的零個或多個字符(\.[^.]*)- 第 2 組(\2指替換模式中的該組值):一個.字符,然后是零個或多個除.char之外的字符$- 字串結束
這是一個測驗:
CREATE TABLE tableXX
(file_name character varying)
;
INSERT INTO tableXX
(file_name)
VALUES
('my_String1_20220103_144415.csv'),
('my_String2_20220106_155730.csv'),
('my_String3_20220108_153930.csv'),
('my_String4_20220103_144470.csv'),
('my_String5_20220103_144415.csv')
;
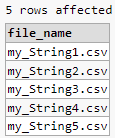
select REGEXP_REPLACE(file_name, '^([^_]*_[^_]*).*(\.[^.]*)$', '\1\2') as file_name from tableXX
輸出:
uj5u.com熱心網友回復:
您要替換的字串部分顯然是日期時間。您不需要可能很慢的 RegEx。
使用基本字串函式(2 個解決方案):
SELECT
OVERLAY(file_name placing '' from (LENGTH(file_name) - 19) for 17)
, REVERSE(OVERLAY(REVERSE(file_name) PLACING '' FROM 4 FOR 16))
FROM tableXX;
OVERLAY不接受負整數,這就是我也使用的原因LENGTH。
但鑒于您想用其特定格式替換此日期時間值,如果您仍想使用RegEx來執行此操作,我建議這樣做:
SELECT REGEXP_REPLACE(file_name, '_[\d_] .', '.')
FROM tableXX;
將以下劃線開頭、后跟整數或下劃線、以點結尾的部分替換為單個點。
uj5u.com熱心網友回復:
還有一個沒有正則運算式的選項:
select concat(split_part(file_name, '_', 1),
'_',
split_part(file_name, '_', 2),
'.',
split_part(file_name, '.', 2))
from the_table
不確定哪個會更快。正則運算式通常很慢,但重復呼叫 withsplit_part()也可能不快。
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/403725.html
標籤: