我從 Linux 服務器獲得了 window10 機器上的 xml 檔案。該檔案是 base64 編碼的。我解碼使用功能的Perl腳本的XMLdecode_base64的MIME::Base64。如果格式正確,我使用 Perl 腳本進行了測驗,但事實并非如此:
C:\test>perl test_well_formed.pl test.xml
test.xml:3: parser error : Input is not proper UTF-8, indicate encoding !
Bytes: 0xFC 0x6C 0x6C 0x65
<print>M3ller</print>
^
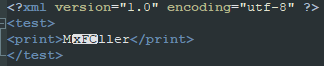
我看了看內容。Notepad 將變音符號 ü 顯示為十六進制代碼
<?xml version="1.0" encoding="utf-8" ?>
<test>
<print>MxFCller</print>
</test>
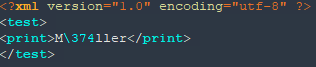
Emacs 將 ü 顯示為八進制代碼:
<?xml version="1.0" encoding="utf-8" ?>
<test>
<print>M\374ller</print>
</test>
Emacs 中的編碼是:
Its value is ‘utf-8-dos’
顯然,utf8 xml 中不允許使用十六進制和八進制代碼。
我想要的是:
<?xml version="1.0" encoding="utf-8" ?>
<test>
<print>Müller</print>
</test>
我的主要問題是:如何修復 xml 檔案?
一種解決方案是使用 Perl 腳本逐行讀取或slurp并用變音符號替換十六進制代碼(或八進制代碼?)。或者有沒有更好的修復方法?例如,轉換 base64 檔案時可以考慮變音符號嗎?
第二個問題是。為什么一個編輯器顯示八進制代碼和其他十六進制代碼?
下面是notepad 和Emacs的截圖:
uj5u.com熱心網友回復:
您沒有“十六進制代碼”或“八進制代碼”。這就是 Notepad 和 Emacs 在檔案中顯示無效位元組的方式。
問題是這與檔案不匹配:
<?xml version="1.0" encoding="utf-8"?>
如訊息所述,您需要指定正確的編碼。例如,如果檔案是使用 Windows-1252 編碼的,您應該使用
<?xml version="1.0" encoding="Windows-1252"?>
另一種使它們匹配的方法,可能也是最有意義的方法,是將檔案轉換為使用 UTF-8。
在 Perl 腳本中,可以使用以下內容:
use Encode qw( from_to );
from_to( $xml, "Windows-1252", "UTF-8" )
從命令列,這可以使用iconv.
iconv -f Windows-1252 -t UTF-8
為什么一個編輯器顯示八進制代碼和十六進制代碼?
首先,它不是一個不同的數字。
并且因為在撰寫 Notepad 時,十六進制是位元組的首選表示形式,八進制在很久以前就被拋棄了。
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/405152.html
標籤:
下一篇:使用grep捕獲組正則運算式