我想根據 30 分鐘的資料創建市場概況。而不是字母,我想要一個價格的字母總和(例如:價格 2500.00 = 'abcdefg' 將改為 2500.00 = 7)
市場概況是在縱軸上顯示價格,在橫軸上顯示時間的概念,每個字母表示 30 分鐘的交易活動
例如 :
9:30 到 9:59 = 'a'
10:00 到 10:29 = 'b'
10:30 到 10:59 = 'c'
以此類推,直到交易日結束,每 30 分鐘收到一封新信
假設在 9:30 到 9:59,最高價是 2505,最低價是 2502,那么它將顯示為
2505 = 一個
2504 = 一個
2503 = 一個
2502 = 一個
2501 =
2500 =
假設在 10:00 到 10:29,最高價是 2503,最低價是 2500,那么它將顯示為
2505 = 一個
2504 = 一個
第2503章
2502 = ab
2501 = 乙
2500 = 乙
假設在 10:30 到 10:59,最高價是 2502,最低價是 2500,那么它將顯示為
2505 = 一個
2504 = 一個
第2503章
2502 = abc
2501 = 公元前
2500 = 公元前
現在我想要的是每天每個價格的字母總和。為此,我創建了一個包含 data.table 的串列,其中包含一天的 30m 條資料,因此每個 data.table 大約有 40 多行。我已經創建了一個相應的串列,其中包含對應日期的 0.25 的低價到高價序列。
代碼正在做的是查看每個 30m 條資料(在“es.d”中)的低點和高點是否低于和高于從低到高的每個價格(在“es.mp”中),如果是,則意味著在這 30m 內,價格確實在那里交易,因此在“es.mp”中價格旁邊的 tpo 列 1
所以上面字母中的例子看起來像
2505 = 1
2504 = 1
2503 = 2
2502 = 3
2501 = 2
2500 = 2
'es.d' is the list containing 30m data for a day
str(es.d)
List of 1291
$ 2016/7/18 :Classes ‘data.table’ and 'data.frame': 47 obs. of 12 variables:
..$ Date : chr [1:47] "2016-07-18 00:00:00" "2016-07-18 00:30:00" "2016-07-18 01:00:00" "2016-07-18 01:30:00" ...
..$ Open : num [1:47] 2156 2156 2156 2158 2156 ...
..$ High : num [1:47] 2157 2157 2158 2158 2158 ...
..$ Low : num [1:47] 2156 2156 2156 2156 2156 ...
..$ Last : num [1:47] 2156 2156 2158 2156 2158 ...
..$ Volume : num [1:47] 1827 1921 2856 3096 2883 ...
..$ # of Trades: num [1:47] 1017 834 1525 1759 1593 ...
..$ OHLC Avg : num [1:47] 2156 2156 2157 2157 2157 ...
..$ HLC Avg : num [1:47] 2156 2156 2157 2157 2157 ...
..$ HL Avg : num [1:47] 2156 2156 2157 2157 2157 ...
..$ Bid Volume : num [1:47] 1000 826 1083 1709 1508 ...
..$ Ask Volume : num [1:47] 827 1095 1773 1387 1375 ...
..- attr(*, ".internal.selfref")<externalptr>
'es.mp' is the corresponding list containing Low to High price for that day in .25 increment
str(es.mp)
List of 1291
$ 2016/7/18 :Classes ‘data.table’ and 'data.frame': 43 obs. of 2 variables:
..$ price: num [1:43] 2153 2153 2153 2154 2154 ...
..$ tpo : num [1:43] 0 0 0 0 0 0 0 0 0 0 ...
..- attr(*, ".internal.selfref")=<externalptr>
And just to add for both the list, data.table in each element don't necessarily have the same amount of rows
Here is the code and it has 3 for loops and its taking way too long or forever if you will
for(i in 1:length(es.d)){
for(j in 1:nrow(es.d[[i]])){
for(k in 1:nrow(es.mp[[i]])){
es.mp[[i]] = es.mp[[i]][k,tpo := nrow(es.d[[i]][Low<=es.mp[[i]][k,price] & High>=es.mp[[i]][k,price]])]}}}
uj5u.com熱心網友回復:
聽起來您正在尋找一個頻率表,顯示有多少 30m 周期跨越了不同的價格點。這是一個快速的dplyr/tidyr方法。這里的關鍵是您設定回圈的方式是高度嵌套的,它沒有利用 R 的“矢量化”計算速度優勢:
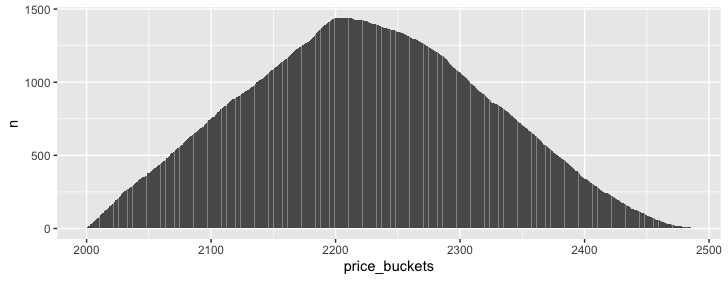
每個 0.25 價格水平被突破的頻率是多少?在這里,我制作了一個價格水平向量,然后將其與假資料交叉,并計算每個價格桶被交叉的次數。在這種情況下,30 天的 3000 萬個周期 = 1440 個周期,乘以大約 2000 個價格桶 = 280 萬行,這是一個非常易于管理的大小,可以在 <1 秒內計算。
price_bucket = seq(from = floor(min(fake_data$Low)/0.25)*0.25,
to = ceiling(max(fake_data$High)/0.25)*0.25,
by = 0.25)
crossing(fake_data, price_buckets) %>%
filter(Low <= price_buckets, High >= price_buckets) %>%
count(price_buckets) %>%
ggplot(aes(price_buckets, n))
geom_col()
幾天后它會變慢,在我的情況下,大約 10 秒 1000 天。我認為轉換為 data.table 語法會更快,但我對如何做到最好還不夠了解。
uj5u.com熱心網友回復:
從 Jon Spring 的建議中,我完全避免了 for 回圈。我仍然認為它可以更快,但現在這作業得很好。
這是代碼
library(data.table); library(dplyr); library(tidyr)
mp = function(x,y){
tpo = data.table(crossing(x, y) %>%
filter(Low <= y, High >= y) %>%
count(y))
setnames(tpo,c('y','n'),c('price','tpo'))}
es.mp = lapply(es.d,function(x) mp(x[,.(Low,High)],seq(min(x[,Low],na.rm=T),max(x[,High],na.rm=T),.25)))
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/408637.html
標籤: