我需要使用分類變數和條件知道在特定時間段內下雨了多少。與我提供的示例資料框相比,我的真實資料框有 150 多行,“分箱”或日期時間列的可變性要大得多。我正在尋找一個 for 回圈或函式來獲取基于特定和可變間隔或時間段的降水總和(例如“TotalRain”),這些間隔或時間段基于“位置”列的某些條件。此列“位置”具有空白行、具有“開始”的行或具有“結束”的行。我的想法是在“組”列中創建間隔/組以更好地識別這些間隔/組,然后使用這些組或另一個 for 回圈求和,然后將該間隔期間的降水總和粘貼到“GroupRain”列中。
這是一個示例資料集,可與為填寫提供的“Groups”和“GroupRain”列一起使用:
dat<-data.frame(binned=as.POSIXct(c("2020-08-01 06:26:00", "2020-08-01 19:26:00", "2020-08-02 06:26:00", "2020-08-02 19:26:00", "2020-08-03 06:26:00","2020-08-03 19:26:00", "2020-08-04 06:26:00", "2020-08-04 19:26:00", "2020-08-05 06:26:00", "2020-08-05 19:26:00", "2020-08-06 06:26:00", "2020-08-06 19:26:00", "2020-08-07 06:26:00", "2020-08-07 19:26:00", "2020-08-08 06:26:00", "2020-08-08 19:26:00", "2020-08-09 06:26:00", "2020-08-09 19:26:00", "2020-08-10 06:26:00"), tz="America/Chicago"), position=c("","", "", "", "", "Start", "", "", "", "End", "", "", "", "Start", "End", "", "" ,"", "" ), TotalRain= as.numeric(c("0.0", "0.0", "0.1", "0.0", "0.0", "0.0", "0.2", "0.3", "0.0", "0.1", "0.0", "0.3", "0.0", "0.1", "0.0", "0.0", "0.4", "0.0", "0.0")), Groups=as.character(""), GroupRain=as.numeric(""))
這是上述代碼中提供的資料幀的影像:
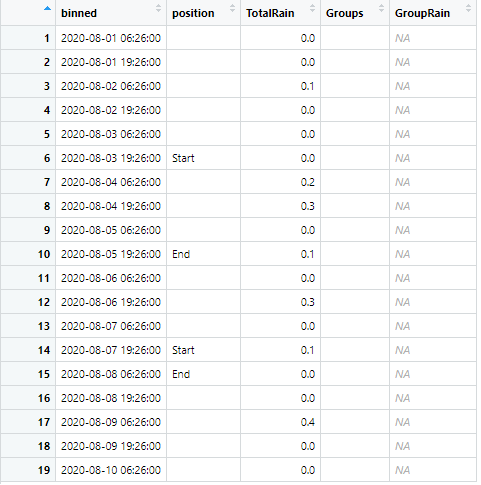
我遇到的問題是創建一個 for 回圈或函式,它開始對“TotalRain”行求和,直到條件發生或條件發生時。例如,我的資料框的前 5 行將是我的第一個間隔/組,我希望“總雨”的總和在“位置”列等于“開始”時停止求和,然后將此總和粘貼到“ GroupRain”第一個間隔結束的列(例如第 5 行)。此資料框中的第一個“開始”將是我的第二個間隔/組的開始,也是 5 行長。對于第二個間隔/組,我想再次獲取“總降雨量”的總和,但在“位置”等于“結束”時停止并將總和粘貼到這一行。第三個間隔從 position 停止等于“End”并且為空白(例如第 11 行到第 13 行)開始,一直持續到 position 再次等于“Start”(例如第 14 行),并將其總和粘貼在第 13 行。第 4 個間隔/組為 2 行長,或第 14 和 15 行,并將其總和粘貼在第 15 行。第 5 個也是最后一個間隔/組為 4 行長,或第 16 到 19 行,并將其總和粘貼到第 19 行。下面我有一個輸出資料框的示例,其中我使用字母表手動創建了 5 個間隔/組,并手動求和并將每個間隔的“總降雨量”粘貼到“群雨”欄目。我可以使用 R 中的“LETTERS”包來提供我的間隔/組名稱(A、B、C 等)。下面提供了我想要結束的資料框:下面我有一個輸出資料框的示例,其中我使用字母表手動創建了 5 個間隔/組,并手動將每個間隔的“總降雨量”相加并粘貼到“GroupRain”列中。我可以使用 R 中的“LETTERS”包來提供我的間隔/組名稱(A、B、C 等)。下面提供了我想要結束的資料框:下面我有一個輸出資料框的示例,其中我使用字母表手動創建了 5 個間隔/組,并手動將每個間隔的“總降雨量”相加并粘貼到“GroupRain”列中。我可以使用 R 中的“LETTERS”包來提供我的間隔/組名稱(A、B、C 等)。下面提供了我想要結束的資料框:
dat2<-data.frame(binned=as.POSIXct(c("2020-08-01 06:26:00", "2020-08-01 19:26:00", "2020-08-02 06:26:00", "2020-08-02 19:26:00", "2020-08-03 06:26:00","2020-08-03 19:26:00", "2020-08-04 06:26:00", "2020-08-04 19:26:00", "2020-08-05 06:26:00", "2020-08-05 19:26:00", "2020-08-06 06:26:00", "2020-08-06 19:26:00", "2020-08-07 06:26:00", "2020-08-07 19:26:00", "2020-08-08 06:26:00", "2020-08-08 19:26:00", "2020-08-09 06:26:00", "2020-08-09 19:26:00", "2020-08-10 06:26:00"), tz="America/Chicago"), position=c("","", "", "", "", "Start", "", "", "", "End", "", "", "", "Start", "End", "", "" ,"", "" ), TotalRain= as.numeric(c("0.0", "0.0", "0.1", "0.0", "0.0", "0.0", "0.2", "0.3", "0.0", "0.1", "0.0", "0.3", "0.0", "0.1", "0.0", "0.0", "0.4", "0.0", "0.0")), Groups=c("A", "A", "A", "A", "A", "B", "B", "B", "B", "B", "C", "C", "C", "D", "D", "E", "E", "E", "E"), GroupRain=as.numeric(c("", "", "", "", "0.1", "", "", "", "", "0.6", "0.0", "", "0.3", "", "0.1", "", "", "", "0.4")))
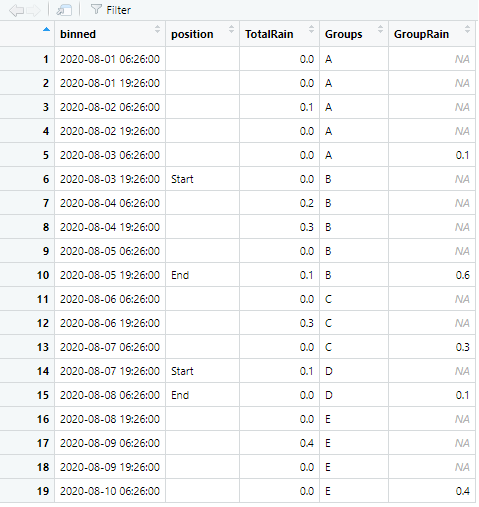
A組或我的第一個間隔總共有0.1英寸。B組或我的第二次間隔總共有0.6英寸。C組總共有0.3英寸。D組總共有0.1英寸。E組總共有0.4英寸。
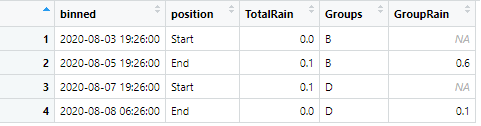
我的最終目標是能夠過濾資料幀,而不會丟失我需要保留的所有中間數字資料(如雨)。當我根據“開始”和“結束”位置進行過濾時,我希望在該時間間隔內已經將匯總的“TotalRain”列顯示為“GroupRain”。例如,我的最終代碼將是這樣,它會生成以下影像并顯示區間/B 組總共有 0.6 英寸的雨。區間/D 組總共有 0.1 英寸的降雨。
dat3<- dat2 %>%filter(position == "Start"|position == "End")
uj5u.com熱心網友回復:
堿基R
dat$ends <- rev(cumsum(rev(dat$position == "End")))
dat$withstarts <- with(dat, ave(position, ends, FUN = function(z) cumsum(z == "Start")))
dat$GroupRain <- with(dat, ave(TotalRain, list(ends, withstarts), FUN = function(z) c(rep(NA, length(z)-1), sum(z)), drop=TRUE))
with(dat, ave(position, list(ends, withstarts), FUN = function(z) !all(c("Start","End") %in% z)))
# [1] "TRUE" "TRUE" "TRUE" "TRUE" "TRUE" "FALSE" "FALSE" "FALSE" "FALSE" "FALSE" "TRUE"
# [12] "TRUE" "TRUE" "FALSE" "FALSE" "TRUE" "TRUE" "TRUE" "TRUE"
dat$GroupRain[with(dat, ave(position, list(ends, withstarts), FUN = function(z) !all(c("Start","End") %in% z))) == "TRUE"] <- NA
dat[c("ends","withstarts")] <- NULL
dat
# binned position TotalRain Groups GroupRain
# 1 2020-08-01 06:26:00 0.0 NA
# 2 2020-08-01 19:26:00 0.0 NA
# 3 2020-08-02 06:26:00 0.1 NA
# 4 2020-08-02 19:26:00 0.0 NA
# 5 2020-08-03 06:26:00 0.0 NA
# 6 2020-08-03 19:26:00 Start 0.0 NA
# 7 2020-08-04 06:26:00 0.2 NA
# 8 2020-08-04 19:26:00 0.3 NA
# 9 2020-08-05 06:26:00 0.0 NA
# 10 2020-08-05 19:26:00 End 0.1 0.6
# 11 2020-08-06 06:26:00 0.0 NA
# 12 2020-08-06 19:26:00 0.3 NA
# 13 2020-08-07 06:26:00 0.0 NA
# 14 2020-08-07 19:26:00 Start 0.1 NA
# 15 2020-08-08 06:26:00 End 0.0 0.1
# 16 2020-08-08 19:26:00 0.0 NA
# 17 2020-08-09 06:26:00 0.4 NA
# 18 2020-08-09 19:26:00 0.0 NA
# 19 2020-08-10 06:26:00 0.0 NA
或者,在添加ends和withstarts添加之后(上圖):
res <- aggregate(TotalRain ~ ends withstarts, data = dat, FUN = sum)
names(res)[3] <- "GroupRain"
dat2 <- merge(dat, res, by = c("ends", "withstarts"))
dat2$GroupRain[dat2$position != "End"] <- NA
dat2[,c("ends","withstarts")] <- NULL
dat2
# binned position TotalRain Groups GroupRain
# 1 2020-08-08 19:26:00 0.0 NA
# 2 2020-08-09 06:26:00 0.4 NA
# 3 2020-08-09 19:26:00 0.0 NA
# 4 2020-08-10 06:26:00 0.0 NA
# 5 2020-08-06 06:26:00 0.0 NA
# 6 2020-08-06 19:26:00 0.3 NA
# 7 2020-08-07 06:26:00 0.0 NA
# 8 2020-08-07 19:26:00 Start 0.1 NA
# 9 2020-08-08 06:26:00 End 0.0 0.1
# 10 2020-08-01 06:26:00 0.0 NA
# 11 2020-08-01 19:26:00 0.0 NA
# 12 2020-08-02 06:26:00 0.1 NA
# 13 2020-08-02 19:26:00 0.0 NA
# 14 2020-08-03 06:26:00 0.0 NA
# 15 2020-08-03 19:26:00 Start 0.0 NA
# 16 2020-08-04 06:26:00 0.2 NA
# 17 2020-08-04 19:26:00 0.3 NA
# 18 2020-08-05 06:26:00 0.0 NA
# 19 2020-08-05 19:26:00 End 0.1 0.6
dplyr
library(dplyr)
dat %>%
group_by(ends = rev(cumsum(rev(position == "End")))) %>%
group_by(withstarts = cumsum(position == "Start"), add = TRUE) %>%
mutate(GroupRain = if_else(all(c("Start", "End") %in% position) & row_number() == n(), sum(TotalRain), NA_real_)) %>%
ungroup() %>%
select(-ends, -withstarts)
# # A tibble: 19 x 5
# binned position TotalRain Groups GroupRain
# <dttm> <chr> <dbl> <chr> <dbl>
# 1 2020-08-01 06:26:00 "" 0 "" NA
# 2 2020-08-01 19:26:00 "" 0 "" NA
# 3 2020-08-02 06:26:00 "" 0.1 "" NA
# 4 2020-08-02 19:26:00 "" 0 "" NA
# 5 2020-08-03 06:26:00 "" 0 "" NA
# 6 2020-08-03 19:26:00 "Start" 0 "" NA
# 7 2020-08-04 06:26:00 "" 0.2 "" NA
# 8 2020-08-04 19:26:00 "" 0.3 "" NA
# 9 2020-08-05 06:26:00 "" 0 "" NA
# 10 2020-08-05 19:26:00 "End" 0.1 "" 0.6
# 11 2020-08-06 06:26:00 "" 0 "" NA
# 12 2020-08-06 19:26:00 "" 0.3 "" NA
# 13 2020-08-07 06:26:00 "" 0 "" NA
# 14 2020-08-07 19:26:00 "Start" 0.1 "" NA
# 15 2020-08-08 06:26:00 "End" 0 "" 0.1
# 16 2020-08-08 19:26:00 "" 0 "" NA
# 17 2020-08-09 06:26:00 "" 0.4 "" NA
# 18 2020-08-09 19:26:00 "" 0 "" NA
# 19 2020-08-10 06:26:00 "" 0 "" NA
資料
dat <- structure(list(binned = structure(c(1596281160, 1596327960, 1596367560, 1596414360, 1596453960, 1596500760, 1596540360, 1596587160, 1596626760, 1596673560, 1596713160, 1596759960, 1596799560, 1596846360, 1596885960, 1596932760, 1596972360, 1597019160, 1597058760), class = c("POSIXct", "POSIXt"), tzone = "America/Chicago"), position = c("", "", "", "", "", "Start", "", "", "", "End", "", "", "", "Start", "End", "", "", "", ""), TotalRain = c(0, 0, 0.1, 0, 0, 0, 0.2, 0.3, 0, 0.1, 0, 0.3, 0, 0.1, 0, 0, 0.4, 0, 0), Groups = c("", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", ""), GroupRain = c(NA_real_, NA_real_, NA_real_, NA_real_, NA_real_, NA_real_, NA_real_, NA_real_, NA_real_, NA_real_, NA_real_, NA_real_, NA_real_, NA_real_, NA_real_, NA_real_, NA_real_, NA_real_, NA_real_)), row.names = c(NA, -19L), class = "data.frame")
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/408644.html
標籤:
上一篇:使用嵌套回圈將資料附加到CSV
下一篇:for回圈和while回圈比較