我是 R 新手,并且在 for 回圈中苦苦掙扎:我想根據我的 df 的條件在 df 中拆分一些字串:
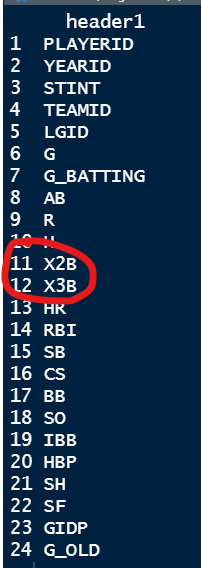
我想拆分以“X”開頭的位置以識別我正在使用 -grepl("X.",df1[,1])
拆分 -str_split_fixed(df1[,1],"X",2)[,2]
并且不確定如何將其合并到回圈中......
for (i in df1[,1]){
# if (begins with X) then split
}
所以這里的目標是從df行(11和12)中去除“X”
先感謝您!
uj5u.com熱心網友回復:
R是一個量化的語言,所以你可以代替領導"X"與""在同一行。
df1[,1] <- sub("^X", "", df1[,1])
在這種情況下使用 for 回圈將非常低效,但如果你堅持這樣做,那么
for (i in seq_along(df1[,1])) {
if (substr(df1[i,1],1,1) == "X")
df1[i,1] <- substring(df1[i,1],2)
}
資料
df1 <- structure(list(header1 = c("PLAYERID", "YEARID", "STINT", "TEAMID",
"LGID", "G", "G_BATTING", "AB", "R", "H", "X2B", "X3B", "HR",
"RBI", "SB", "CS", "BB", "SO", "IBB", "HBP", "SH", "SF", "GIDP",
"G_OLD")), class = "data.frame", row.names = c(NA, -24L))
uj5u.com熱心網友回復:
for 回圈
for(i in seq_along(df$header1)){ df$header1[i] <- sub("^X","",df$header1[i]) }
df
header1
1 DGIGACAE
2 DFGGFAEHBD
3 BIBH
4 EB
5 DHBDFC
6 2BD
7 3GDE
8 DEAEFGE
9 I
10 FFBGDBD
更好的矢量化
df$header1 <- sub("^X","",df$header1)
df
header1
1 DGIGACAE
2 DFGGFAEHBD
3 BIBH
4 EB
5 DHBDFC
6 2BD
7 3GDE
8 DEAEFGE
9 I
10 FFBGDBD
資料
df <- structure(list(header1 = c("DGIGACAE", "DFGGFAEHBD", "BIBH",
"EB", "DHBDFC", "X2BD", "X3GDE", "DEAEFGE", "I", "FFBGDBD")), row.names = c(NA,
-10L), class = "data.frame")
uj5u.com熱心網友回復:
stringr 解決方案
我意識到你想使用回圈,而其他 2 個解決方案給了你,加上一個矢量化解決方案。如果您正在使用tidyverse,您也可以使用它str_replace來執行此操作:
df1 <- structure(list(header1 = c("PLAYERID", "YEARID", "STINT", "TEAMID",
"LGID", "G", "G_BATTING", "AB", "R", "H", "X2B", "X3B", "HR",
"RBI", "SB", "CS", "BB", "SO", "IBB", "HBP", "SH", "SF", "GIDP",
"G_OLD")), class = "data.frame", row.names = c(NA, -24L))
df1
library(tidyverse)
df1 %>% mutate(header1 = str_replace(header1, "^X", ""))
輸出:
header1
1 PLAYERID
2 YEARID
3 STINT
4 TEAMID
5 LGID
6 G
7 G_BATTING
8 AB
9 R
10 H
11 2B
12 3B
13 HR
14 RBI
15 SB
16 CS
17 BB
18 SO
19 IBB
20 HBP
21 SH
22 SF
23 GIDP
24 G_OLD
所以……你有很多選擇。不過,我認為其他答案會更好地解決您的直接問題。
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/408657.html
標籤:
下一篇:根據情節選擇復制檔案