col = ['c1_1', 'c1_2', 'c1_3', 'c1$1']
d = {4:'improvement needed',5:'very bad'}
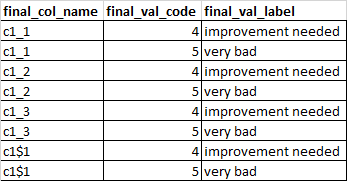
如何使用 pd.DataFrame (pandas library) 得到如上圖的輸出
uj5u.com熱心網友回復:
感謝Quang的評論。最熊貓的做法是這樣的:
pd.DataFrame(col,columns=['final_col_name']).merge(pd.DataFrame(d.items(), columns=['final_val_code','final_val_label']),how = 'cross')
uj5u.com熱心網友回復:
import pandas as pd
col = ['c1_1', 'c1_2', 'c1_3', 'c1$1']
# use list comprehension to duplicate each item in col list
col = [col[i//2] for i in range(len(col)*2)]
d = {4:'improvement needed', 5:'very bad'}
df = pd.DataFrame({'final_col_name': col})
# duplicate each item in list of d keys
final_val_code = list(d.keys()) * int(df.shape[0] / 2) * int(df.shape[0] / 2)
df['final_val_code'] = final_val_code
# map d values to final_val_code col
df['final_val_label'] = df['final_val_code'].map(d)
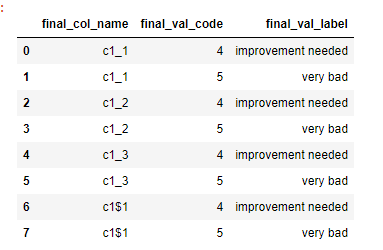
print(df)
final_col_name final_val_code final_val_label
0 c1_1 4 improvement needed
1 c1_1 5 very bad
2 c1_2 4 improvement needed
3 c1_2 5 very bad
4 c1_3 4 improvement needed
5 c1_3 5 very bad
6 c1$1 4 improvement needed
7 c1$1 5 very bad
uj5u.com熱心網友回復:
col = ['c1_1', 'c1_2', 'c1_3', 'c1$1']
d = {4:'improvement needed',5:'very bad'}
col_name = []
val_code = []
val_lable = []
for i in col:
for k,v in d.items():
col_name.append(i)
val_code.append(k)
val_lable.append(v)
detail = {
"final_col_name": col_name,
"final_val_code": val_code,
"final_val_lable": val_lable,
}
df = pd.DataFrame(detail)
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/408918.html
標籤:
上一篇:根據可用資料點計算平均值