我有一個性能關鍵的C代碼,其中 > 90% 的時間用于執行一項基本操作:
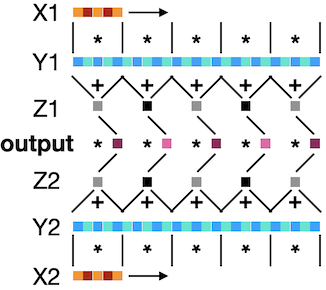
我使用的C代碼是:
static void function(double *X1, double *Y1, double *X2, double *Y2, double *output) {
double Z1, Z2;
int i, j, k;
for (i = 0, j = 0; i < 25; j ) { // sweep Y
Z1 = 0;
Z2 = 0;
for (k = 0; k < 5; k , i ) { // sweep X
Z1 = X1[k] * Y1[i];
Z2 = X2[k] * Y2[i];
}
output[j] = Z1*Z2;
}
}
長度是固定的(X 為 5;Y 為 25;輸出為 5)。我已經嘗試了我所知道的一切來加快速度。當我使用 clang with 編譯此代碼時-O3 -march=native -Rpass-analysis=loop-vectorize -Rpass=loop-vectorize -Rpass-missed=loop-vectorize,我收到以下訊息:
備注:成本模型表明矢量化沒有好處 [-Rpass-missed=loop-vectorize]
但我認為加快速度的方法是以某種方式使用 SIMD。任何建議,將不勝感激。
uj5u.com熱心網友回復:
嘗試以下版本,它需要 SSE2 和 FMA3。未經測驗。
void function_fma( const double* X1, const double* Y1, const double* X2, const double* Y2, double* output )
{
// Load X1 and X2 vectors into 6 registers; the instruction set has 16 of them available, BTW.
const __m128d x1_0 = _mm_loadu_pd( X1 );
const __m128d x1_1 = _mm_loadu_pd( X1 2 );
const __m128d x1_2 = _mm_load_sd( X1 4 );
const __m128d x2_0 = _mm_loadu_pd( X2 );
const __m128d x2_1 = _mm_loadu_pd( X2 2 );
const __m128d x2_2 = _mm_load_sd( X2 4 );
// 5 iterations of the outer loop
const double* const y1End = Y1 25;
while( Y1 < y1End )
{
// Multiply first 2 values
__m128d z1 = _mm_mul_pd( x1_0, _mm_loadu_pd( Y1 ) );
__m128d z2 = _mm_mul_pd( x2_0, _mm_loadu_pd( Y2 ) );
// Multiply accumulate next 2 values
z1 = _mm_fmadd_pd( x1_1, _mm_loadu_pd( Y1 2 ), z1 );
z2 = _mm_fmadd_pd( x2_1, _mm_loadu_pd( Y2 2 ), z2 );
// Horizontal sum both vectors
z1 = _mm_add_sd( z1, _mm_unpackhi_pd( z1, z1 ) );
z2 = _mm_add_sd( z2, _mm_unpackhi_pd( z2, z2 ) );
// Multiply accumulate the last 5-th value
z1 = _mm_fmadd_sd( x1_2, _mm_load_sd( Y1 4 ), z1 );
z2 = _mm_fmadd_sd( x2_2, _mm_load_sd( Y2 4 ), z2 );
// Advance Y pointers
Y1 = 5;
Y2 = 5;
// Compute and store z1 * z2
z1 = _mm_mul_sd( z1, z2 );
_mm_store_sd( output, z1 );
// Advance output pointer
output ;
}
}
使用 AVX 可以進一步進行微優化,但我不確定它是否會有很大幫助,因為內部回圈太短了。我認為這兩個額外的 FMA 指令比計算 32 位元組 AVX 向量的水平和的開銷要便宜。
更新:這是另一個版本,總體上需要更少的指令,但會花費一些洗牌。對于您的用例,May of 可能不會更快。需要 SSE 4.1,但我認為所有具有 FMA3 的 CPU 也都具有 SSE 4.1。
void function_fma_v2( const double* X1, const double* Y1, const double* X2, const double* Y2, double* output )
{
// Load X1 and X2 vectors into 5 registers
const __m128d x1_0 = _mm_loadu_pd( X1 );
const __m128d x1_1 = _mm_loadu_pd( X1 2 );
__m128d xLast = _mm_load_sd( X1 4 );
const __m128d x2_0 = _mm_loadu_pd( X2 );
const __m128d x2_1 = _mm_loadu_pd( X2 2 );
xLast = _mm_loadh_pd( xLast, X2 4 );
// 5 iterations of the outer loop
const double* const y1End = Y1 25;
while( Y1 < y1End )
{
// Multiply first 2 values
__m128d z1 = _mm_mul_pd( x1_0, _mm_loadu_pd( Y1 ) );
__m128d z2 = _mm_mul_pd( x2_0, _mm_loadu_pd( Y2 ) );
// Multiply accumulate next 2 values
z1 = _mm_fmadd_pd( x1_1, _mm_loadu_pd( Y1 2 ), z1 );
z2 = _mm_fmadd_pd( x2_1, _mm_loadu_pd( Y2 2 ), z2 );
// Horizontal sum both vectors while transposing
__m128d res = _mm_shuffle_pd( z1, z2, _MM_SHUFFLE2( 0, 1 ) ); // [ z1.y, z2.x ]
// On Intel CPUs that blend SSE4 instruction doesn't use shuffle port,
// throughput is 3x better than shuffle or unpack. On AMD they're equal.
res = _mm_add_pd( res, _mm_blend_pd( z1, z2, 0b10 ) ); // [ z1.x z1.y, z2.x z2.y ]
// Load the last 5-th Y values into a single vector
__m128d yLast = _mm_load_sd( Y1 4 );
yLast = _mm_loadh_pd( yLast, Y2 4 );
// Advance Y pointers
Y1 = 5;
Y2 = 5;
// Multiply accumulate the last 5-th value
res = _mm_fmadd_pd( xLast, yLast, res );
// Compute and store z1 * z2
res = _mm_mul_sd( res, _mm_unpackhi_pd( res, res ) );
_mm_store_sd( output, res );
// Advance output pointer
output ;
}
}
uj5u.com熱心網友回復:
從注釋擴展的討論看起來大多是你有興趣在減少閱讀之間的延遲X1,X2寫作和output。您正在計算的是兩個矩陣向量產品的元素乘積。兩個 MV 產品可以準并行發生(帶有 OOO 執行),但是兩個 MV 產品都需要五個產品的總和,您可以按順序(就像您現在所做的那樣)或樹狀減少:
Z = ((X[0]*Y[0] X[1]*Y[1]) X[2]*Y[2]) ([X[3]*Y[3] [X[4]*Y[4]);
這導致關鍵路徑mulsd- fmaddsd- fmaddsd- addsd,其后是 的乘法Z1*Z2。這意味著,假設每個 FLOP 有 4 個周期的延遲,您將有 20 個周期的延遲加上讀取和寫入記憶體的延遲(除非您能夠將所有內容保存在暫存器中 - 這需要您顯示周圍的代碼)。如果你線性累積值,你將有一個關鍵路徑mulsd- fmaddsd- fmaddsd- fmaddsd- fmaddsd- mulsd(即 24 個周期 讀/寫)
現在,如果您能夠更改 的記憶體順序Y,那么轉置這些矩陣將是有益的,因為這樣您就可以輕松地output[0 ~ 3]并行計算(假設您有 AVX),方法是首先廣播加載 的每個條目X并進行打包累加。
void function_fma( const double* X1, const double* Y1, const double* X2, const double* Y2, double* output )
{
// Load X1 and X2 vectors into 10 registers.
const __m256d x1_0 = _mm256_broadcast_sd( X1 );
const __m256d x1_1 = _mm256_broadcast_sd( X1 1 );
const __m256d x1_2 = _mm256_broadcast_sd( X1 2 );
const __m256d x1_3 = _mm256_broadcast_sd( X1 3 );
const __m256d x1_4 = _mm256_broadcast_sd( X1 4 );
const __m256d x2_0 = _mm256_broadcast_sd( X2 );
const __m256d x2_1 = _mm256_broadcast_sd( X2 1 );
const __m256d x2_2 = _mm256_broadcast_sd( X2 2 );
const __m256d x2_3 = _mm256_broadcast_sd( X2 3 );
const __m256d x2_4 = _mm256_broadcast_sd( X2 4 );
// first four values:
{
// Multiply column 0
__m256d z1 = _mm256_mul_pd( x1_0, _mm256_loadu_pd( Y1 ) );
__m256d z2 = _mm256_mul_pd( x2_0, _mm256_loadu_pd( Y2 ) );
// Multiply accumulate column 1 and column 2
z1 = _mm256_fmadd_pd( x1_1, _mm256_loadu_pd( Y1 5 ), z1 );
z2 = _mm256_fmadd_pd( x2_1, _mm256_loadu_pd( Y2 5 ), z2 );
z1 = _mm256_fmadd_pd( x1_2, _mm256_loadu_pd( Y1 10 ), z1 );
z2 = _mm256_fmadd_pd( x2_2, _mm256_loadu_pd( Y2 10 ), z2 );
// Multiply column 3
__m256d z1_ = _mm256_mul_pd( x1_3, _mm256_loadu_pd( Y1 15 ) );
__m256d z2_ = _mm256_mul_pd( x2_3, _mm256_loadu_pd( Y2 15 ) );
// Multiply accumulate column 4
z1_ = _mm256_fmadd_pd( x1_4, _mm256_loadu_pd( Y1 20 ), z1_ );
z2_ = _mm256_fmadd_pd( x2_4, _mm256_loadu_pd( Y2 20 ), z2_ );
// Add both partial sum
z1 = _mm256_add_pd( z1, z1_ );
z2 = _mm256_add_pd( z2, z2_ );
// Multiply and store result
_mm256_store_pd(output, _mm256_mul_pd(z1, z2));
}
// last value:
{
// Multiply column 0
__m128d z1 = _mm_mul_sd( _mm256_castpd256_pd128(x1_0), _mm_load_sd( Y1 4) );
__m128d z2 = _mm_mul_sd( _mm256_castpd256_pd128(x2_0), _mm_load_sd( Y2 4) );
// Multiply accumulate column 1 and column 2
z1 = _mm_fmadd_sd( _mm256_castpd256_pd128(x1_1), _mm_load_sd( Y1 9 ), z1 );
z2 = _mm_fmadd_sd( _mm256_castpd256_pd128(x2_1), _mm_load_sd( Y2 9 ), z2 );
z1 = _mm_fmadd_sd( _mm256_castpd256_pd128(x1_2), _mm_load_sd( Y1 14 ), z1 );
z2 = _mm_fmadd_sd( _mm256_castpd256_pd128(x2_2), _mm_load_sd( Y2 14 ), z2 );
// Multiply column 3
__m128d z1_ = _mm_mul_sd( _mm256_castpd256_pd128(x1_3), _mm_load_sd( Y1 19 ) );
__m128d z2_ = _mm_mul_sd( _mm256_castpd256_pd128(x2_3), _mm_load_sd( Y2 19 ) );
// Multiply accumulate column 4
z1_ = _mm_fmadd_sd( _mm256_castpd256_pd128(x1_4), _mm_load_sd( Y1 24 ), z1_ );
z2_ = _mm_fmadd_sd( _mm256_castpd256_pd128(x2_4), _mm_load_sd( Y2 24 ), z2_ );
// Add both partial sum
z1 = _mm_add_sd( z1, z1_ );
z2 = _mm_add_sd( z2, z2_ );
// Multiply and store result
_mm_store_sd(output 4, _mm_mul_sd(z1, z2));
}
}
如果您沒有 FMA,則可以通過乘法和加法來替換它們(這不會改變很多延遲,因為只有加法位于關鍵路徑中——當然,吞吐量可能會降低 50% 左右)。此外,如果您沒有 AVX,則可以通過兩次乘以兩個值來計算前四個值。
uj5u.com熱心網友回復:
通過分別加載下半部分和上半部分暫存器,您一次至少可以處理 2 個元素。展開i兩個可能會給你一個小優勢......
該__restrict關鍵字,如果適用,使5個常系數X1[0..4], X2[0..4]預加載。如果X1或X2部分別名輸出,最好讓編譯器知道它(通過使用相同的陣列)。這樣,在展開完整函式時,編譯器不會不必要地重新加載任何元素。
typedef double __attribute__((vector_size(16))) f2;
void function2(double *X1, double *Y1, double *X2, double *Y2, double *__restrict output) {
double Z1, Z2;
int i = 0, j, k;
for (j = 0; j < 5; j ) { // sweep Y
f2 Z12 = {0.0, 0.0};
for (k = 0; k < 5; k , i ) {
f2 Y12 = {Y1[i], Y2[i]};
f2 X12 = {X1[k], X2[k]};
Z12 = X12 * Y12;
}
output[j] = Z12[0]*Z12[1];
}
}
如果可能,請考慮交錯 Y1Y2、X1X3:
void function2(f2 const *X12, f2 const *Y12, double *output) {
int i = 0, j, k;
for (j = 0; j < 5; j ) { // sweep Y
f2 Z12 = X12[0] * Y12[0];
for (k = 1; k < 5; k , i ) {
Z12 = X12[k] * Y12[k];
}
output[j] = Z12[0]*Z12[1]; // possibly [j * 2]?
}
}
通過內在函式可能會獲得稍微更好的性能,但是,這個答案強調自動矢量化。
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/409300.html
標籤:
上一篇:單個地圖任務需要很長時間并且在hivemapreduce中失敗
下一篇:UI性能-Xamarin