文章目錄
- 概覽
- 劍指offer
- 1.5 重建二叉樹
- 1.6 雙堆疊實作佇列
- 1.7 斐波那契數列(動態規劃)
- 1.8 青蛙跳臺階
- Java基礎
- 2.1 Java集合
- 2.2 HashMap
- 2.3 Java反射
- 總結
概覽
劍指offer:重建二叉樹、雙堆疊實作佇列、斐波那契數列、青蛙跳臺階
Java基礎:Java集合、HashMap、Java反射
劍指offer
1.5 重建二叉樹
輸入某二叉樹的前序遍歷和中序遍歷的結果,請構建該二叉樹并回傳其根節點,
假設輸入的前序遍歷和中序遍歷的結果中都不含重復的數字
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-LoD9paD2-1642235714794)(D:\Typora\img\1629825510-roByLr-Picture1.png)]
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
int[] preorder;
HashMap<Integer,Integer> dic = new HashMap<>();
public TreeNode buildTree(int[] preorder, int[] inorder) {
this.preorder = preorder;
//將中序遍歷的值-索引存入map中,方便遞回時獲取左子樹與右子樹的數量及其根的索引
for(int i=0;i<inorder.length;i++){
dic.put(inorder[i],i);
}
//當前根的的索引,遞回樹的左邊界,遞回樹的右邊界
return recur(0,0,inorder.length-1);
}
TreeNode recur(int pre_root,int in_left,int in_right){
if(in_left > in_right) return null;
TreeNode root = new TreeNode(preorder[pre_root]);
int in_root = dic.get(preorder[pre_root]); //獲取在中序遍歷中根節點所在索引
//左子樹的根的索引為先序中的根節點索引+1
//遞回左子樹的左邊界為原來的中序in_left
//遞回左子樹的右邊界為中序中的根節點索引-1
root.left = recur(pre_root+1,in_left,in_root-1);
//右子樹的根的索引為先序中的 (當前根索引 + 左子樹的數量 + 1)
//遞回右子樹的左邊界為中序中當前根節點索引+1
//遞回右子樹的右邊界為中序中原來右子樹的邊界
root.right = recur(pre_root+(in_root-in_left)+1,in_root+1,in_right);
return root;
}
}
1.6 雙堆疊實作佇列
用兩個堆疊實作一個佇列,佇列的宣告如下,請實作它的兩個函式 appendTail 和 deleteHead ,分別完成在佇列尾部插入整數和在佇列頭部洗掉整數的功能,(若佇列中沒有元素,deleteHead 操作回傳 -1 )
//雙堆疊實作佇列,一個堆疊存盤隊尾插入元素,一個堆疊反向第一個堆疊,用于對頭洗掉操作(反向堆疊出堆疊一個元素即可)
class CQueue {
LinkedList<Integer> stack,rStack;
public CQueue() {
stack = new LinkedList<Integer>();
rStack = new LinkedList<Integer>();
}
public void appendTail(int value) {
stack.push(value);
}
public int deleteHead() {
if(!rStack.isEmpty()) return rStack.pop();
if(stack.isEmpty()) return -1;
while(!stack.isEmpty()){
rStack.push(stack.pop());
}
return rStack.pop();
}
}
1.7 斐波那契數列(動態規劃)
寫一個函式,輸入 n ,求斐波那契(Fibonacci)數列的第 n 項(即 F(N)),斐波那契數列的定義如下:
F(0) = 0, F(1) = 1
F(N) = F(N - 1) + F(N - 2), 其中 N > 1.
斐波那契數列由 0 和 1 開始,之后的斐波那契數就是由之前的兩數相加而得出,
答案需要取模 1e9+7(1000000007),如計算初始結果為:1000000008,請回傳 1
//動態規劃
class Solution {
public int fib(int n) {
int a = 0,b = 1,sum;
for(int i=0;i<n;i++){
sum = (a + b) % 1000000007;
a = b;
b = sum;
}
return a; //精華
}
}
1.8 青蛙跳臺階
一只青蛙一次可以跳上1級臺階,也可以跳上2級臺階,求該青蛙跳上一個 n 級的臺階總共有多少種跳法,
答案需要取模 1e9+7(1000000007),如計算初始結果為:1000000008,請回傳 1,
//動態規劃,就是斐波那契數列;
//跳1個臺階有1種方法,跳2個臺階有2種方法(可以看作跳兩個1級臺階),跳3個臺階有三種方法(可以看作1+2)即前兩個臺階種數相加;
class Solution {
public int numWays(int n) {
int a=1,b=1,sum;
for(int i=0;i<n;i++){
sum = (a + b) % 1000000007;
a = b;
b = sum;
}
return a;
}
}
Java基礎
2.1 Java集合
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-r5qa5c98-1642235743267)(D:\Typora\img\1155586-20191121113020194-1422948337.jpg)]
List集合
有序串列,允許存放重復的元素;
實作類:
- ArrayList:陣列實作,查詢快,增刪慢,輕量級(執行緒不安全);
- LinkedList:雙向鏈表實作,增刪快,查詢慢 (執行緒不安全);
- Vector:陣列實作,重量級 (執行緒安全、使用少);
ArrayList
底層是Object陣列,所以ArrayList具有陣列的查詢速度快的優點以及增刪速度慢的缺點,
LinkedList
LinkedList是采用雙向回圈鏈表實作的,利用LinkedList實作堆疊(stack)、佇列(queue)、雙向佇列(double-ended queue ),
查詢速度慢、增刪速度快;
Vector
與ArrayList相似,區別是Vector是重量級的組件,使用使消耗的資源比較多,
在考慮并發的情況下用Vector(保證執行緒的安全),
在不考慮并發的情況下用ArrayList(不能保證執行緒的安全),
Set集合
擴展Collection介面
無序集合,不允許存放重復的元素;允許使用null元素;對 add()、equals() 和 hashCode() 方法添加了限制
實作類 :
- HashSet:equals回傳true,hashCode回傳相同的整數;哈希表;存盤的資料是無序的,
- LinkedHashSet:此實作與HashSet的不同之外在于,后者維護著一個運行于所有條目的雙重鏈接串列,存盤的資料是有序的,
- TreeSet:該類實作了Set介面,可以實作排序等功能,
HashSet類
HashSet類直接實作了Set介面,其底層其實是包裝了一個HashMap去實作的,HashSet采用HashCode演算法來存取集合中的元素,因此具有比較好的讀取和查找性能,
HashSet的特征:
- 不僅不能保證元素插入的順序,而且在元素在以后的順序中也可能變化(這是由HashSet按HashCode存盤物件(元素)決定的,物件變化則可能導致HashCode變化)
- HashSet是執行緒非安全的
- HashSet元素值可以為NULL
LinkedHashSet的特征
LinkedHashSet是HashSet的一個子類,LinkedHashSet也根據HashCode的值來決定元素的存盤位置,但同時它還用一個鏈表來維護元素的插入順序,插入的時候即要計算hashCode又要維護鏈表,而遍歷的時候只需要按鏈表來訪問元素,
底層資料結構采用鏈表和哈希表共同實作,鏈表保證了元素的順序與存盤順序一致,哈希表保證了元素的唯一性,執行緒不安全,效率高,
TreeSet的特征
底層資料結構采用二叉樹來實作,元素唯一且已經排好序;唯一性同樣需要重寫hashCode和equals()方法,二叉樹結構保證了元素的有序性,
Map集合
Map用于保存具有映射關系的資料,Map里保存著兩組資料:key和value,它們都可以使任何參考型別的資料,但key不能重復,所以通過指定的key就可以取出對應的value,
(1) HashMap:它根據鍵的hashCode值存盤資料,大多數情況下可以直接定位到它的值,因而具有很快的訪問速度,但遍歷順序卻是不確定的, HashMap最多只允許一條記錄的鍵為null,允許多條記錄的值為null,HashMap非執行緒安全,即任一時刻可以有多個執行緒同時寫HashMap,可能會導致資料的不一致,如果需要滿足執行緒安全,可以用 Collections的synchronizedMap方法使HashMap具有執行緒安全的能力,或者使用ConcurrentHashMap,
(2) Hashtable:Hashtable是遺留類,很多映射的常用功能與HashMap類似,不同的是它承自Dictionary類,并且是執行緒安全的,任一時間只有一個執行緒能寫Hashtable,并發性不如ConcurrentHashMap,因為ConcurrentHashMap引入了分段鎖,Hashtable不建議在新代碼中使用,不需要執行緒安全的場合可以用HashMap替換,需要執行緒安全的場合可以用ConcurrentHashMap替換,
(3) LinkedHashMap:LinkedHashMap是HashMap的一個子類,保存了記錄的插入順序,在用Iterator遍歷LinkedHashMap時,先得到的記錄肯定是先插入的,也可以在構造時帶引數,按照訪問次序排序,
(4) TreeMap:TreeMap實作SortedMap介面,能夠把它保存的記錄根據鍵排序,默認是按鍵值的升序排序,也可以指定排序的比較器,當用Iterator遍歷TreeMap時,得到的記錄是排過序的,如果使用排序的映射,建議使用TreeMap,在使用TreeMap時,key必須實作Comparable介面或者在構造TreeMap傳入自定義的Comparator,否則會在運行時拋出java.lang.ClassCastException型別的例外
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-yi1dFAqg-1642236040738)(D:\Typora\img\20170513133210763)]
2.2 HashMap
2.2.1 問:HashMap 有用過嗎?您能給我說說他的主要用途嗎?
答:有用過,我在平常作業中經常會用到 HashMap 這種資料結構,HashMap 是基于 Map 介面實作的一種鍵-值對<key,value>的存盤結構,允許 null 值,同時非有序,非同步(即執行緒不安全),HashMap 的底層實作是陣列 + 鏈表 + 紅黑樹(JDK1.8 增加了紅黑樹部分),它存盤和查找資料時,是根據鍵 key 的 hashCode的值計算出具體的存盤位置,HashMap 最多只允許一條記錄的鍵 key 為 null,HashMap 增刪改查等常規操作都有不錯的執行效率,是 ArrayList 和 LinkedList等資料結構的一種折中實作,
2.2.2 問:您能說說 HashMap 常用操作的底層實作原理嗎?如存盤 put(K key, V value),查找get(Object key),洗掉 remove(Object key),修改 replace(K key, V value)等操作.
答:呼叫 put(K key, V value)操作添加 key-value 鍵值對時,進行了如下操作:
1.判斷哈希表 Node<K,V>[] table 是否為慷訓者 null,是則執行 resize()方法進行擴容,
2.根據插入的鍵值 key 的 hash 值, hash 值 % hash 表長度計算出存盤位置 table[i],如果存盤位置沒有元素存放,則將新增結點存盤在此位置table[i],如果存盤位置已經有鍵值對元素存在,則判斷該位置元素的 hash 值和 key值是否和當前操作元素一致,一致則證明是修改 value 操作,覆寫 value即可,
3.當前存盤位置即有元素,又不和當前操作元素一致,則證明此位置table[i]已經發生了 hash 沖突,則通過判斷頭結點是否是 treeNode,如果是 treeNode 則證明此位置的結構是紅黑樹,已紅黑樹的方式新增結點,如果不是紅黑樹,則證明是單鏈表,將新增結點插入至鏈表的最后位置,隨后判斷當前鏈表長度是否 大于等于 8,是則將當前存盤位置的鏈表轉化為紅黑樹,遍歷程序中如果發現 key 已經存在,則直接覆寫 value,
4.插入成功后,判斷當前存盤鍵值對的數量 大于 閾值 threshold 是則擴容,
2.2.3 問:HashMap 的容量為什么一定要是 2 的 n 次方?
答:因為呼叫 put(K key, V value)操作添加 key-value 鍵值對時,具體確定此元素的位置是通過 hash 值 % 模上 哈希表 Node<K,V>[] table 的長度 hash % length 計算的,但是"模"運算的消耗相對較大,通過位運算 h & (length-1)也可以得到取模后的存放位置,而位運算的運行效率高,但只有 length 的長度是2 的 n 次方時,h & (length-1) 才等價于 h % length,
而且當陣列長度為 2 的 n 次冪的時候,不同的 key 算出的 index 相同的幾率較小,那么資料在陣列上分布就比較均勻,也就是說碰撞的幾率小,相對的,查詢的時候就不用遍歷某個位置上的鏈表,這樣查詢效率也就較高了,
2.2.4 問:HashMap 的負載因子是什么,有什么作用?
答:負載因子表示哈希表空間的使用程度(或者說是哈希表空間的利用率),
底層哈希表 Node<K,V>[] table 的容量大小 capacity 為 16,負載因子load factor 為 0.75,則當存盤的元素個數 size = capacity 16 * load factor 0.75 等于 12 時,則會觸發 HashMap 的擴容機制,呼叫 resize()方法進行擴容,
當負載因子越大,則 HashMap 的裝載程度就越高,也就是能容納更多的元素,元素多了,發生 hash 碰撞的幾率就會加大,從而鏈表就會拉長,此時的查詢效率就會降低,
當負載因子越小,則鏈表中的資料量就越稀疏,此時會對空間造成浪費,但是此時查詢效率高,
我們可以在創建 HashMap 時根據實際需要適當地調整 load factor 的值;如果程式比較關心空間開銷、記憶體比較緊張,可以適當地增加負載因子;如果程式比較關心時間開銷,記憶體比較寬裕則可以適當的減少負載因子,通常情況下,默認負載因子 (0.75) 在時間和空間成本上尋求一種折中,程式員無需改變負載因子的值,
2.2.5 問:您說 HashMap 不是執行緒安全的,那如果多執行緒下,它是如何處理的?并且什么情況下會發生執行緒不安全的情況?
答:HashMap 不是執行緒安全的,如果多個執行緒同時對同一個 HashMap 更改資料的話,會導致資料不一致或者資料污染,如果出現執行緒不安全的操作時,HashMap會盡可能的拋出 ConcurrentModificationException 防止資料例外,當我們在對一個 HashMap 進行遍歷時,在遍歷期間,我們是不能對 HashMap 進行添加,洗掉等更改資料的操作的,否則也會拋出 ConcurrentModificationException 例外,此為 fail-fast(快速失敗)機制,從原始碼上分析,我們在 put,remove 等更改 HashMap資料時,都會導致 modCount 的改變,當 expectedModCount != modCount 時,則拋出 ConcurrentModificationException,
2.2.6 問:我們在使用 HashMap 時,選取什么物件作為 key 鍵比較好,為什么?
答:我們在使用 HashMap 時,最好選擇不可變物件作為 key,例如 String,Integer 等不可變型別作為 key 是非常明智的,
如果 key 物件是可變的,那么 key 的哈希值就可能改變,在 HashMap 中可變物件作為 Key 會造成資料丟失,因為我們再進行 hash & (length - 1)取模運算計算位置查找對應元素時,位置可能已經發生改變,導致資料丟失,
2.3 Java反射
JAVA反射機制是在運行狀態中,對于任意一個類,都能夠知道這個類的所有屬性和方法;對于任意一個物件,都能夠呼叫它的任意一個方法和屬性;這種動態獲取的資訊以及動態呼叫物件的方法的功能稱為java語言的反射機制,
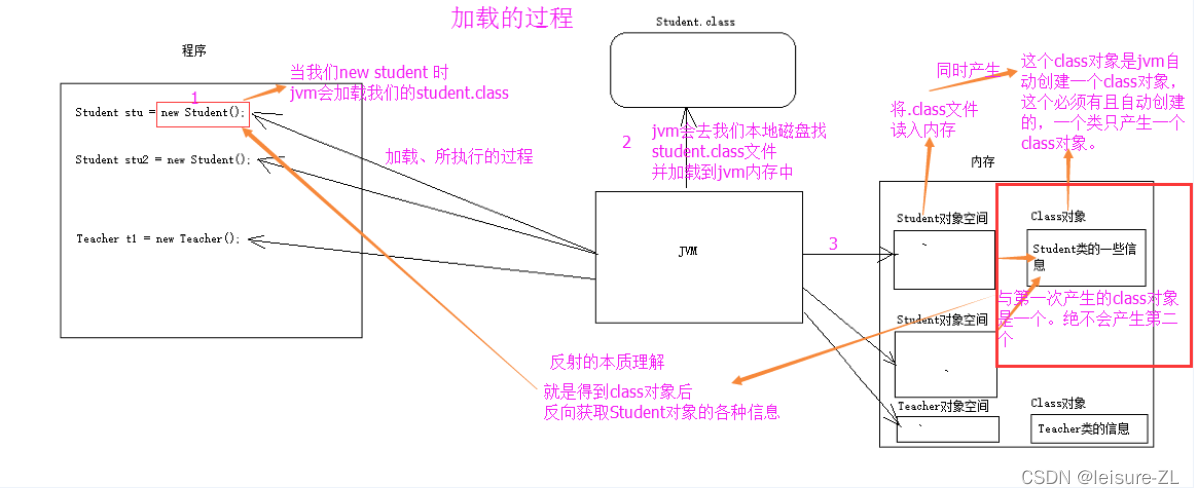
Java中編譯型別有兩種:
- 靜態編譯:在編譯時確定型別,系結物件即通過,
- 動態編譯:運行時確定型別,系結物件,動態編譯最大限度地發揮了Java的靈活性,體現了多型的應用,可以減低類之間的耦合性,
Java反射是Java被視為動態(或準動態)語言的一個關鍵性質,這個機制允許程式在運行時透過Reflection APIs取得任何一個已知名稱的class的內部資訊,包括其modifiers(諸如public、static等)、superclass(例如Object)、實作之interfaces(例如Cloneable),也包括fields和methods的所有資訊,并可于運行時改變fields內容或喚起methods,
Reflection可以在運行時加載、探知、使用編譯期間完全未知的classes,即Java程式可以加載一個運行時才得知名稱的class,獲取其完整構造,并生成其物件物體、或對其fields設值、或喚起其methods,
反射(reflection)允許靜態語言在運行時(runtime)檢查、修改程式的結構與行為,
在靜態語言中,使用一個變數時,必須知道它的型別,在Java中,變數的型別資訊在編譯時都保存到了class檔案中,這樣在運行時才能保證準確無誤;換句話說,程式在運行時的行為都是固定的,如果想在運行時改變,就需要反射這東西了,
實作Java反射機制的類都位于java.lang.reflect包中:
- Class類:代表一個類
- Field類:代表類的成員變數(類的屬性)
- Method類:代表類的方法
- Constructor類:代表類的構造方法
- Array類:提供了動態創建陣列,以及訪問陣列的元素的靜態方法
一句話概括就是使用反射可以賦予jvm動態編譯的能力,否則類的元資料資訊只能用靜態編譯的方式實作,例如熱加載,Tomcat的classloader等等都沒法支持,
總結
1.劍指四道演算法題,第一道二叉樹的遍歷與重建熟悉了二叉樹的操作,重拾記憶;斐波那契的動態規劃演算法非常巧妙;
2.學習和熟悉了Java的集合,了解HashMap底層原理和Java反射機制基礎;
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/413480.html
標籤:其他
下一篇:Java筆記-第四周