我有一個具有以下結構的表:
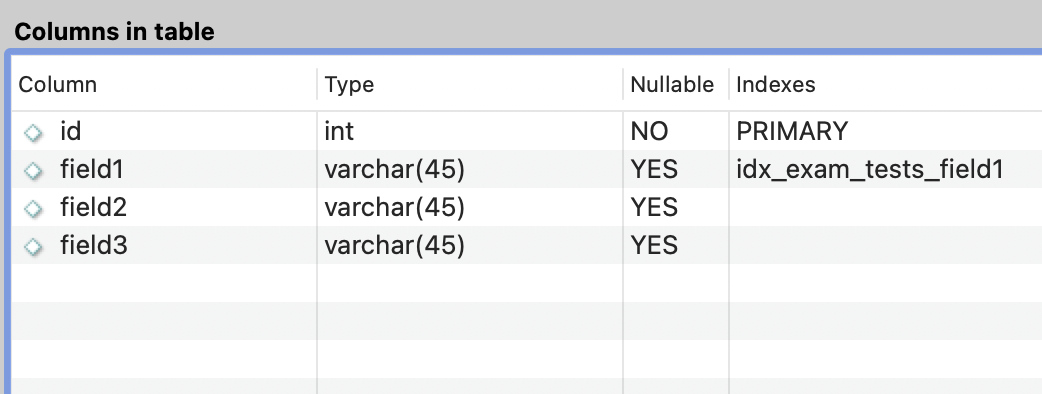
該表有大約 25000 行。由于我在列上有一個索引,因此field1在運行explain查詢時我看到的掃描行數較少。但是,我的問題是在使用limit(沒有偏移量)之后,為什么在使用索引列而不是限制(在下面的示例中,即 10)過濾的情況下它會掃描每個匹配的行?
以下是我運行的查詢及其相應的結果:
- 查詢一:
explain SELECT id, field1 from exam_tests where field1 = 'val9' limit 10; - 結果:

- 查詢 2:`explain SELECT id, field1 from Exam_tests where field2 = 'val9' limit 10;
- 結果:

- 查詢 3:
explain SELECT id, field1 from exam_tests where field2 = 'val9' order by field1 limit 10; - 結果:

- 問題 4:
explain SELECT id, field1 from exam_tests where field1 = 'val9' order by field1 limit 10; - 結果:

以下是我的問題:
- 在Query1上,即使有一個索引列(在其上進行過濾)并應用了一個限制,為什么優化器會考慮掃描每個匹配的結果?確實有 1287 行 field1 = 'val9'。此外,我還注意到,如果我嘗試將 field1 過濾為不存在的值,則說明回傳 rows=1!例如:
在這里,對于列
explain SELECT id, field1 from exam_tests where field1 = 'val11' order by field1 limit 10;,沒有具有值的行。在這種情況下,我得到以下結果:val11field1
- 在Query3 上,僅僅因為我們按索引列添加順序,查詢優化器如何能夠在不掃描整個表的情況下獲得所需的結果(過濾后的列,
field2沒有索引)?
uj5u.com熱心網友回復:
Rows在_EXPLAIN
- 是一個估計,通常是一個非常粗略的估計;和
- 通常不考慮
LIMIT。
查詢 1 - 僅使用索引的 BTree 執行查詢。(線索:“使用索引”)。它可能只觸及了 10 行。(在解釋中沒有可用的線索)
查詢 2——全表掃描(線索:All和Nulls)。它讀取了所有行,但可能只傳遞了一小部分行(線索:過濾 10.00%——再次粗略估計)
查詢 3——嗯……它選擇了錯誤的 [我的意見] 方式來執行查詢;它決定使用索引,卻沒有意識到它可能必須遍歷整個表才能找到 10 行。 INDEX(field2, field1),按此順序將是最佳的。
查詢 4——(也許你打錯了?這ORDER BY是不必要的,因為輸出的所有行都具有相同的值。)
其他幫手:
如果您想確切知道觸摸了多少行,請執行以下操作:
FLUSH STATUS; SELECT ... ; SHOW SESSION STATUS LIKE 'Handler%';EXPLAIN FORMAT=JSON SELECT ...“優化器跟蹤”。
慢日志記錄“檢查的行”。
Index Cookbook(它包括“處理程式”和優化器跟蹤提示。)
也許以下內容解決了您的最后一個問題。如果表中沒有匹配的行,則仍然需要進行探測才能發現該事實。這會將一些實際行數增加 1,包括 0 到 1。類似地,如果只有 6 行匹配WHERE(并且小于LIMIT),它將“檢查”7 行以意識到是時候停止了。
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/419730.html
標籤:
上一篇:SQL查詢以明智地獲取凈利潤股票