我在 SQL Server 2019 上運行的 SQL 查詢存在性能問題,該查詢從地理列回傳緯度/經度。
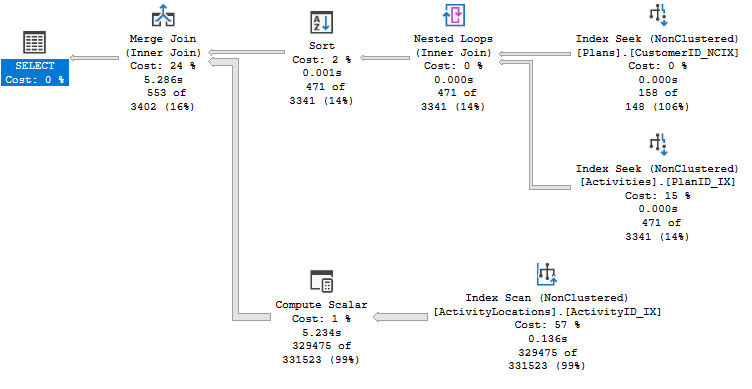
我的查詢如下,回傳 553 行大約需要 5 秒:
SELECT ActivityLocations.ID, ActivityLocations.ActivityID, ActivityLocations.Number, ActivityLocations.Location.Lat AS 'Latitude', ActivityLocations.Location.Long AS 'Longitude'
FROM Plans
INNER JOIN Activities ON Plans.ID = Activities.PlanID
INNER JOIN ActivityLocations ON Activities.ID = ActivityLocations.ActivityID
WHERE CustomerID = 35041
它生成的查詢計劃是:
但是,如果我稍微更改查詢以回傳更少的資料,則回傳 207 行需要 0 秒:
SELECT ActivityLocations.ID, ActivityLocations.ActivityID, ActivityLocations.Number, ActivityLocations.Location.Lat AS 'Latitude', ActivityLocations.Location.Long AS 'Longitude'
FROM Plans
INNER JOIN Activities ON Plans.ID = Activities.PlanID
INNER JOIN ActivityLocations ON Activities.ID = ActivityLocations.ActivityID
WHERE PlanID > 22486
查詢計劃是:
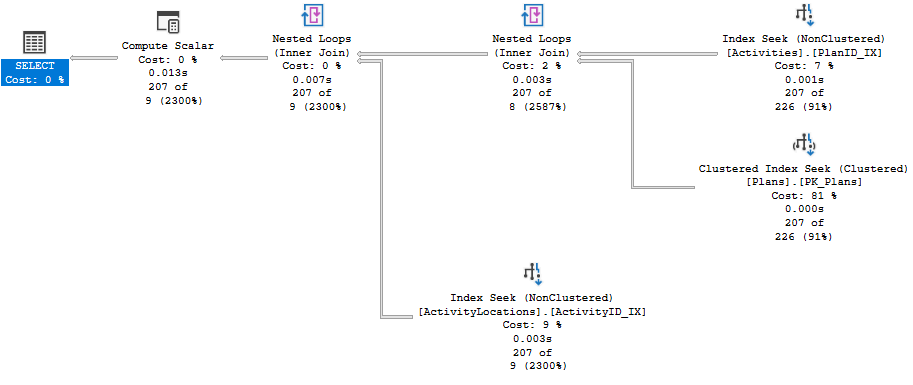
我想我的問題是,為什么計算標量操作發生在慢查詢連接之前和快速查詢連接之后?我不明白為什么當我們只需要一小部分行時,它會對活動位置表的每一行進行緯度/經度操作?
任何幫助將不勝感激。
編輯以包含表格資訊
CREATE TABLE [dbo].[Activities](
[ID] [int] NOT NULL,
[PlanID] [int] NOT NULL,
[Name] [nvarchar](255) NOT NULL,
CONSTRAINT [PK_Activity] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
CREATE TABLE [dbo].[ActivityLocations](
[ID] [int] NOT NULL,
[ActivityID] [int] NOT NULL,
[Number] [int] NOT NULL,
[Location] [geography] NOT NULL,
CONSTRAINT [PK_ActivityLocations] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
CREATE TABLE [dbo].[ActivityPlans](
[ID] [int] NOT NULL,
[CustomerID] [int] NOT NULL,
[PurchaseOrder] [nvarchar](255) NULL,
[Deleted] [bit] NOT NULL,
[Name] [nvarchar](500) NULL,
CONSTRAINT [PK_ActivityPlan] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
CREATE NONCLUSTERED INDEX [PlanID_IX] ON [dbo].[Activities]
(
[PlanID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
CREATE NONCLUSTERED INDEX [ActivityID_IX] ON [dbo].[ActivityLocations]
(
[ActivityID] ASC
)
INCLUDE([Number],[Location]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
CREATE NONCLUSTERED INDEX [CustomerID_NCIX] ON [dbo].[ActivityPlans]
(
[CustomerID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
uj5u.com熱心網友回復:
注意:OP 將表的名稱更改為Plans最初ActivityPlans發布的查詢/圖形執行計劃與他隨后提供的執行計劃(通過粘貼計劃)和 DDL 腳本之間。我將根據表格Plans(如最初發布的那樣)發言。
我將嘗試完整地解釋這一點,包括嘗試注意這兩個查詢之間不存在問題的事情,因為查看兩個查詢時的明顯差異不會導致問題(本身)。請繼續閱讀以查看我的解釋。
相似之處
首先,讓我們談談這兩個執行計劃的相似之處。重要的是要注意相似之處,因為(假設第二個查詢計劃對于 OP 是可以接受的)問題不在于兩個查詢計劃之間的相似性。
- 兩個執行計劃都從訪問表
Plans和Activities.- 首先訪問的表會根據您的
WHERE子句進行更改。哪個好。優化器做出了正確的決定,并且能夠在這兩種情況下使用索引查找。過濾器WHERE CustomerID = 35041決議為表索引上的索引查找,CustomerID_NCIX過濾Plans器決議為表WHERE PlanID > 22486索引上的索引查找。然后連接到后續表(在第一個查詢和第二個查詢中)完成。在這兩種情況下都由索引支持,對查找操作的估計并不可怕,并且兩個連接都是使用嵌套回圈完成的,輸出的數字相對接近最終結果集。因此,即使這兩個查詢中唯一的視覺差異是子句的差異,看起來PlanID_IXActivitiesActivitiesPlansWHEREWHERE每個查詢中的子句的處理方式都非常相似,似乎不是問題。
- 首先訪問的表會根據您的
- 在兩個執行計劃中以相同順序訪問第一個和第二個查詢中使用的所有 3 個表的實際順序。
- 兩個查詢都
ActivityLocations使用索引訪問表ActivityID_IX。 - 這兩個查詢都有一個運算子,用于檢索運算式和陳述句
Compute Scalar所需的值。ActivityLocations.Location.LatActivityLocations.Location.LongActivityLocations.LocationSELECT
差異
現在讓我們談談(重要的)差異,這就是問題所在。
- 第一個查詢
ActivityLocations使用 Index Seek 運算子訪問表,而第二個查詢使用 Index Scan 運算子。 - 訪問第一個查詢的表的 Index Scan 運算子
ActivityLocations的實際/估計行數為 329,475/331,523,訪問ActivityLocations第二個查詢的表的 Index Seek 運算子的實際/估計行數為 207/9。 - 第一個查詢使用合并連接來連接前兩個表 (
Plans和Activities) 的結果,第二個查詢使用嵌套回圈連接。 - 從第一個查詢的 ActivityLocations.Location 檢索所需值的計算標量運算子的實際/估計行數為 329,475/331,523,而在第二個查詢中,它的實際/估計行數為 207/9。
- 第一個查詢的最終連接輸出中的實際/估計行數從其輸入排序運算子 (471/3341->553/3402) 開始增加,而最終連接輸出中的實際/估計行數為第二個查詢與其輸入的嵌套回圈運算子 (207->9) 保持一致。
實際問題是什么?
簡而言之,當我們查看執行計劃時,第一個查詢正在讀取更多資料。在第一個查詢中從大約 300k 的表ActivityLocations中讀取的行數遠高于在第二個查詢中讀取的 207 行。此外,第一個查詢的計算標量運算子需要計算(相同的)大約 300k 行的值,而不是第二個查詢的 207 行。這顯然會導致運行時間更長的查詢。
還值得注意的是,來自表的較大行數ActivityLocations是 Merge Join(在第一個查詢計劃中看到)代替 Nested Loop Join 運算子(在第二個查詢計劃中看到)的原因。根據 optmizer 的說法,給定您的環境,Merge Join 比 Nested Loop Join 更適合將 300k 行連接到 3.3k 行。并且使用 Merge Join 要求連接的兩邊都按連接列排序,因此在第一個查詢的查詢計劃中附加了 Sort 運算子的原因。
為什么會這樣?
估計。估計驅動優化器的決策。在第一個查詢中,我們看到從表中讀取的估計行數ActivityLocations(來自索引掃描)是 331,523,而在第二個查詢中(來自 Index Seek)我們看到估計為 9。說起來可能有點奇怪,但這些估計值比你想象的要接近。索引掃描(關于最新統計資訊)通常會得到與表中的行等效的行估計(過濾索引除外)。理想情況下,Index Seek 估計的行數少于表中包含的行數。理想情況下,該數字將與 Index Seek 需要觸及的實際行數相匹配,但您的 Index Seek 估計值低于整個表的事實是朝著正確方向邁出的一步。
So if the issue is not with the estimates in the Index Scan or Index Seek then where is it? The issue is in the choice to access the table ActivityLocations using an Index Scan in the first query over the choice to use an Index Seek. So why does the first query choose an Index Scan? It is quite clear by looking at the execution plan that an Index Seek would have been a better option. I believe the answer in this case is the cardinality estimation, specifically in this case, the cardinality estimation used for the join to the table ActivityLocations.
We see that the estimated number of rows in the output of the final join of the first query increases from its input Sort operator (3341->3402) while the estimated number of rows in the output of the final join of the second query remains consistent from its input Nested Loop operator (207->9). And not only did the optimzer estimate this, it was right. The actual rows counts returned from these same operators reflect the same pattern.
Why does that matter? What it means is that based on the optimizer's estimate, the join to the table ActivityLocations is going to increase the row count of the input result set. Meaning this join is going to be 1 (input row) to many (output row). Keep in mind, the optimizer needs to return your requested values ActivityLocations.Location.Lat and ActivityLocations.Location.Long from the table ActivityLocations. So when it considers this join, that it believes is going to increase the rows it plans to output from accessing the table ActivityLocations while keeping in mind that it needs to perform a Compute Scalar on columns output from that table, it would make sense to run the Compute Scalar prior to running the join because if the Compute Scalar is run before the join it can guarantee that the Compute Scalar is only running once per row of ActivityLocations, but it cannot guarantee that if the Compute Scalar is run after the join. In this case, the join is actually what ends up limiting the rows from AcitivityLocations and the number of rows returned from that table (for the purposes of this query) is much lower than the row count of the table. In the second query, the estimate says that the output number of rows will be the same, so running the Compute Scalar after the join makes no difference to the number of rows where the compute will be required, so it makes sense to perform the Index Seek in place of the Index Scan.
So to summarize, the rows returned from the first two tables of your first and second query (using your WHERE clause) are different. And it is likely that the rows returned from the first query resulted in a join estimation that estimated a different cardinality than the second query. Thus the differences in how the query plan was built and how it was subsequently run.
Cardinality estimation (with joins specifically) is made up of several factors. If you really want to get in to the internals I would recommend these two articles from the legend Paul White and SQL Shack. The things discussed there should guide you on how you can review the estimation within your system.
How to fix it?
The first goal would be to improve the estimate. If the estimated cardinality for the join was incorrect (which is actually not the case here) then updating the statistics might help. Out of date statistics could lead to a bad cardinality estimate, and thus a bad query plan.
In some cases you might be able to restructure your query to a logical equivalent to result in a better execution plan. This might be by writing it to produce better estimates or even possibly returning different rows in different orders. In this case, I would say the first query looks fine to me, and thus rewriting the query for a logical equivalent would likely not help.
在這種情況下,基數估計是正確的(并且您提到您更新了統計資訊但它沒有幫助),查詢似乎以一種很好的方式撰寫,但選擇的執行計劃仍然是次優的。所以我會推薦一個查詢提示。這個問題很容易通過查詢提示來解決,以尋找ActivityID_IX. ActivityLocations您在第一個查詢中的加入如下所示:
INNER JOIN ActivityLocations (WITH FORCESEEK,INDEX(ActivityID_IX)) ON Activities.ID = ActivityLocations.ActivityID
有很多關于為什么查詢提示可能是一個壞主意的資訊,但鑒于我在這里的資訊,我會說這是最好的選擇。我總是對其他意見持開放態度。干杯!
uj5u.com熱心網友回復:
問題在于索引本身:您的客戶 ID 可以出現在 Plans 表中的任何位置,而在第二個查詢中,PlanID 上的大于意味著您將查詢限制在表的末尾,因為聚集索引 (確定 Plan 表中行的實際排序的索引)位于 PlanID 上。
結果,查詢規劃器就如何排序查詢執行做出了不同的選擇。
您最好的選擇是添加三個額外的索引:
- 首先是帶有欄位 CustomerID、PlanID 的計劃
- 第二個關于具有 PlanID、ActivityID 的活動
- ActivityID、ID、Number、Lat、Long 的 ActivityLocations 排名第三
這允許查詢引擎:
- 使用第一個索引立即找到 Plan for a customer 中的行
- 獲取這些 PlanID 并使用第二個索引立即找到這些計劃的活動(通過 PlanID 查找活動)
- 獲取這些 ActivityID 并使用第三個索引立即回傳結果 ID、Number、Lat、Long
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/420175.html
標籤:
上一篇:根據多個變數在SQL中查找匹配值
下一篇:使用CTE更新記錄