我已經通過 Apache Flume 流式傳輸資料,并且資料已存盤在我的 hdfs 檔案夾中的臨時檔案中:user/*****/tweets/FlumeData.1643626732852.tmp
現在我正在嘗試運行一個僅映射器的作業,它將通過 url 洗掉、#標簽洗掉、@洗掉、停用詞洗掉等方式對作業進行預處理。
但是,僅映射器作業在運行作業時停止。
映射器作業代碼:
hadoop jar mr-job-jars/SentimentAnalysisPreprocessingJob.jar com.hadoop.poc.sentimentAnalysis.phase1.SentimentAnalysisPreprocessingDriver /user/*****/tweets/ FlumeData.1643626732852.tmp /output
執行輸出:
2022-01-31 06:16:18,151 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
2022-01-31 06:16:18,611 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
2022-01-31 06:16:18,666 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/aviparna/.staging/job_1643615018627_0004
2022-01-31 06:16:18,996 INFO input.FileInputFormat: Total input files to process : 1
2022-01-31 06:16:19,108 WARN hdfs.DataStreamer: Caught exception
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at java.lang.Thread.join(Thread.java:1252)
at java.lang.Thread.join(Thread.java:1326)
at org.apache.hadoop.hdfs.DataStreamer.closeResponder(DataStreamer.java:986)
at org.apache.hadoop.hdfs.DataStreamer.endBlock(DataStreamer.java:640)
at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:810)
2022-01-31 06:16:19,168 INFO mapreduce.JobSubmitter: number of splits:1
2022-01-31 06:16:19,449 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1643615018627_0004
2022-01-31 06:16:19,451 INFO mapreduce.JobSubmitter: Executing with tokens: []
2022-01-31 06:16:19,794 INFO conf.Configuration: resource-types.xml not found
2022-01-31 06:16:19,794 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2022-01-31 06:16:19,935 INFO impl.YarnClientImpl: Submitted application application_1643615018627_0004
2022-01-31 06:16:20,035 INFO mapreduce.Job: The url to track the job: http://ubuntu:8088/proxy/application_1643615018627_0004/
2022-01-31 06:16:20,038 INFO mapreduce.Job: Running job: job_1643615018627_0004
我需要做什么來解決這個問題?請幫忙。此外,對于任何需要的附加資訊,請通知我。我會盡快提供給他們。
添加 YARN UI 的螢屏截圖:
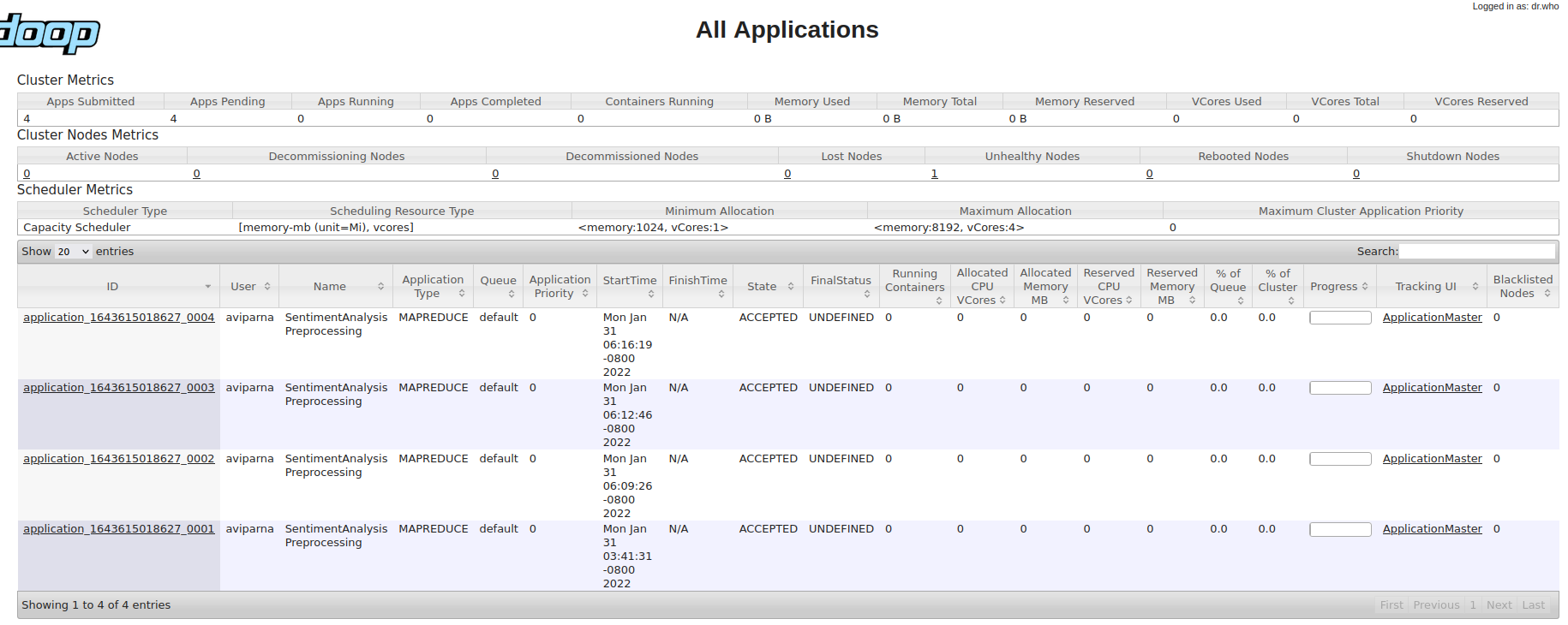
uj5u.com熱心網友回復:
通過將mapred-site.xmlmapreduce.framework.name中的從 yarn更改為 local 解決了我的問題。
由于機器中的資源緊縮,問題似乎正在發生。
同樣在更改屬性后,再次重新啟動 Hadoop 服務。
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/424062.html