我有一個資料集,其中包含一組我想為每一行求和的列。有問題的列都遵循我過去可以通過 .sum() 函式進行分組的特定命名模式:
pd.DataFrame.sum(data.filter(regex=r'_name$'),axis=1)
現在,我需要完成同樣的功能,但是,當按列的值分組時:
data.groupby('group').sum(data.filter(regex=r'_name$'),axis=1)
但是,這似乎不起作用,因為 .sum() 函式現在不需要任何過濾列。有沒有另一種方法來處理這個保留我的 data.filter() 代碼?
示例玩具資料集。真實資料集包含超過 500 列,其中所有列的排序不整齊:
toy_data = ({'id':[1,2,3,4,5,6],
'group': ["a","a","b","b","c","c"],
'a_name': [1,6,7,3,7,3],
'b_name': [4,9,2,4,0,2],
'c_not': [5,7,8,4,2,5],
'q_name': [4,6,8,2,1,4]
})
df = pd.DataFrame(toy_data, columns=['id','group','a_name','b_name','c_not','q_name'])
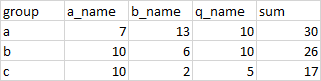
編輯:在原始帖子中錯過了這個。我的目標是獲得所有選定列的總和的變數“總和”,如下所示:
uj5u.com熱心網友回復:
您可以先過濾,然后傳遞df['group']給group,groupby最后添加sum列DataFrame.assign:
df1 = (df.filter(regex=r'_name$')
.groupby(df['group']).sum()
.assign(sum = lambda x: x.sum(axis=1)))
ALternative 是過濾列名稱并在之后傳遞groupby:
cols = df.filter(regex=r'_name$').columns
df1 = df.groupby('group')[cols].sum()
或者:
cols = df.columns[df.columns.str.contains(r'_name$')]
df1 = df.groupby('group')[cols].sum().assign(sum = lambda x: x.sum(axis=1))
print (df1)
a_name b_name q_name sum
group
a 7 13 10 30
b 10 6 10 26
c 10 2 5 17
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/425813.html