我有一個看起來像這樣的 DataFrame(最后生成的代碼):
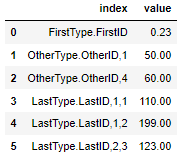
...而且我想基本上拆分index列,以達到此目的:
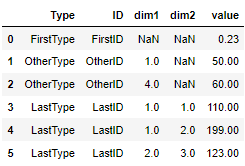
每個Type.ID. 我撰寫了一個函式來拆分單個字串,但我不知道如何將它應用于列(我查看了apply)。
謝謝您的幫助!設定輸入資料幀的代碼:
pd.DataFrame({
'index': pd.Series(['FirstType.FirstID', 'OtherType.OtherID,1','OtherType.OtherID,4','LastType.LastID,1,1', 'LastType.LastID,1,2', 'LastType.LastID,2,3'],dtype='object',index=pd.RangeIndex(start=0, stop=6, step=1)),
'value': pd.Series([0.23, 50, 60, 110.0, 199.0, 123.0],dtype='float64',index=pd.RangeIndex(start=0, stop=6, step=1)),
}, index=pd.RangeIndex(start=0, stop=6, step=1))
拆分索引值的代碼:
import re
def get_header_properties(header):
pf_type = re.match(".*?(?=\.)", header).group()
pf_id = re.search(f"(?<={pf_type}\.).*?(?=(,|$))", header).group()
pf_coords = re.search(f"(?<={pf_id}).*", header).group()
return pf_type, pf_id, pf_coords.split(",")[1:]
get_header_properties("Type.ID,0.625,0.08333")
#-> ('Type', 'ID', ['0.625', '0.08333'])
uj5u.com熱心網友回復:
您可以稍微更改函式并在串列理解中使用它;然后將嵌套串列分配給列:
def get_header_properties(header):
pf_type = re.match(".*?(?=\.)", header).group()
pf_id = re.search(f"(?<={pf_type}\.).*?(?=(,|$))", header).group()
pf_coords = re.search(f"(?<={pf_id}).*", header).group()
coords = pf_coords.split(",")[1:]
return [pf_type, pf_id] coords ([np.nan]*(2-len(coords)) if len(coords)<2 else [])
df[['Type','ID','dim1','dim2']] = [get_header_properties(i) for i in df['index']]
out = df.drop(columns='index')[['Type','ID','dim1','dim2','value']]
也就是說,str.split在“索引”列上使用一次似乎更簡單,更有效,而不是函式,join它df:
df = (df['index'].str.split('[.,]', expand=True)
.fillna(np.nan)
.rename(columns={i: col for i,col in enumerate(['Type','ID','dim1','dim2'])})
.join(df[['value']]))
輸出:
Type ID dim1 dim2 value
0 FirstType FirstID NaN NaN 0.23
1 OtherType OtherID 1 NaN 50.00
2 OtherType OtherID 4 NaN 60.00
3 LastType LastID 1 1 110.00
4 LastType LastID 1 2 199.00
5 LastType LastID 2 3 123.00
uj5u.com熱心網友回復:
您可以直接在有問題的列上展開正則運算式!
>>> df["index"].str.extract(r"([^\.] )\.([^,] )(?:,(\d ))?(?:,(\d ))?")
0 1 2 3
0 FirstType FirstID NaN NaN
1 OtherType OtherID 1 NaN
2 OtherType OtherID 4 NaN
3 LastType LastID 1 1
4 LastType LastID 1 2
5 LastType LastID 2 3
將專欄加入value到最后(這里也有其他專欄的機會)
df_idx = df["index"].str.extract(r"([^\.] )\.([^,] )(?:,(\d ))?(?:,(\d ))?")
df = df_idx.join(df[["value"]])
df = df.rename({0: "Type", 1: "ID", 2: "dim1", 3: "dim2"}, axis=1)
>>> df
Type ID dim1 dim2 value
0 FirstType FirstID NaN NaN 0.23
1 OtherType OtherID 1 NaN 50.00
2 OtherType OtherID 4 NaN 60.00
3 LastType LastID 1 1 110.00
4 LastType LastID 1 2 199.00
5 LastType LastID 2 3 123.00
uj5u.com熱心網友回復:
IMO,最簡單的就是split:
df2 = df['index'].str.split('[,.]', expand=True)
df2.columns = ['Type', 'ID', 'dim1', 'dim2']
df2 = df2.join(df['value'])
注意。正則運算式在這里依賴點/逗號分隔符,但您可以根據需要進行調整
輸出:
Type ID dim1 dim2 value
0 FirstType FirstID None None 0.23
1 OtherType OtherID 1 None 50.00
2 OtherType OtherID 4 None 60.00
3 LastType LastID 1 1 110.00
4 LastType LastID 1 2 199.00
5 LastType LastID 2 3 123.00
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/427004.html