這是我的問題:
假設這個圖:
import networkx as nx
import pandas as pd
user_network_G = user_trust_cardinality_network.subgraph([30,40,71,145,638,783,893])
nan_edge = [(u, v) for (u, v, d) in user_network_G.edges(data=True) if math.isnan(d["Trust"])]
real_edge = [(u, v) for (u, v, d) in user_network_G.edges(data=True) if math.isnan(d["Trust"]) == False]
pos = nx.kamada_kawai_layout(user_network_G)
# nodes
nx.draw_networkx_nodes(user_network_G, pos, node_size=700)
# edges
nx.draw_networkx_edges(user_network_G, pos, edgelist = real_edge, width=2)
nx.draw_networkx_edges(user_network_G, pos, edgelist = nan_edge, width=2, style="dashed")
# labels
nx.draw_networkx_labels(user_network_G, pos, font_size=12, font_family="sans-serif")
nx.draw_networkx_edge_labels(user_network_G, pos, edge_labels = nx.get_edge_attributes(user_network_G,'Trust') , font_size=10, font_family='sans-serif', label_pos = 0.6)
nx.draw_networkx_edge_labels(user_network_G, pos, edge_labels = nx.get_edge_attributes(user_network_G,'Intersection') , font_size=10, font_family='sans-serif', label_pos = 0.4)
plt.axis("off")
plt.show()
給予:
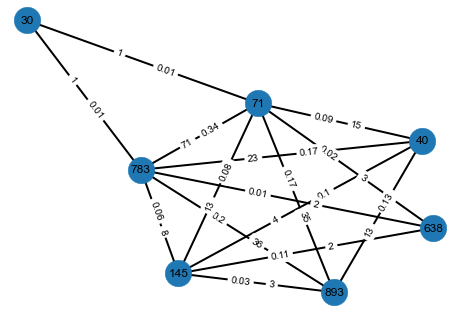
在哪里 :
- 邊上的整數是兩個用戶(節點)之間共有的產品的基數
- 邊上的小數是兩個節點(即兩個用戶)之間的真值分數
現在我想計算兩個節點之間(例如節點 30 和節點 40 之間)不存在邊的邊值。
為了實作這一點,我首先創建了我的圖表(如上圖所示):
user_trust_cardinality_network = nx.from_pandas_edgelist(user_local_trust_computation(normalized_user_rating_matrix)[1].reset_index(level = ['User_U','User_V']), 'User_U', 'User_V', ['Trust', 'Intersection', 'Pondered_Trust'])
#Creation of the graph from a table containing for each existing paire of nodes the Trust Score, the Cardinality and the Pondered_Trust_Score
user_trust_cardinality_network.remove_edges_from(nx.selfloop_edges(user_trust_cardinality_network))
#Remove selfloop edges
edges_to_predict = [(u, v) for (u, v, d) in user_trust_cardinality_network.edges(data=True) if math.isnan(d["Trust"]) == True]
#Storing the set of edges to predict (edges where trust is NaN)
edges_to_predict_sub = [(u, v) for (u, v, d) in user_trust_cardinality_network.subgraph([30,40,71,145,638,783,893]).edges(data=True) if math.isnan(d["Trust"]) == True]
#Edges to predict on my subgraph (for quick example computation)
user_trust_cardinality_network.remove_edges_from([(u, v) for (u, v, d) in user_trust_cardinality_network.edges(data=True) if math.isnan(d["Trust"]) == True])
#Remove edges to predict, to add them after with the newly computed score
然后我計算洗掉邊緣的分數:
def short_path_trust (graph, edges_to_predict,cutoff) :
short_path_trust_dict = {}
for (u,v) in edges_to_predict :
for edges_path in nx.all_simple_edge_paths(graph, u, v, cutoff):
pondered_trust = [d['Pondered_Trust'] for (x,y,d) in graph.edges.data() if (x,y) in edges_path or (y,x) in edges_path]
intersection = [d['Intersection'] for (x,y,d) in graph.edges.data() if (x,y) in edges_path or (y,x) in edges_path]
short_path_trust_dict = {'Path%s' % [u,v] : sum(pondered_trust)/sum(intersection)}
print(short_path_trust_dict)
給我這個:
short_path_trust(user_trust_cardinality_network.subgraph([30,40,71,145,638,783,893]), edges_to_predict_sub, 2)
{'Path[40, 30]': 0.08499999999999999}
{'Path[40, 30]': 0.16333333333333333}
{'Path[40, 638]': 0.07833333333333332}
{'Path[40, 638]': 0.10333333333333333}
{'Path[40, 638]': 0.1572}
{'Path[145, 30]': 0.075}
{'Path[145, 30]': 0.05444444444444444}
{'Path[30, 638]': 0.017499999999999998}
{'Path[30, 638]': 0.01}
{'Path[30, 893]': 0.16555555555555557}
{'Path[30, 893]': 0.19486486486486487}
{'Path[893, 638]': 0.1581578947368421}
{'Path[893, 638]': 0.062}
{'Path[893, 638]': 0.19}
我的問題是結果似乎是一個字典生成器,因此是一組獨立的字典。這不是字典字典(我已經在研究這種可能性),這里有證據:
def short_path_trust (graph, edges_to_predict,cutoff) :
short_path_trust_dict = {}
for (u,v) in edges_to_predict :
for edges_path in nx.all_simple_edge_paths(graph, u, v, cutoff):
pondered_trust = [d['Pondered_Trust'] for (x,y,d) in graph.edges.data() if (x,y) in edges_path or (y,x) in edges_path]
intersection = [d['Intersection'] for (x,y,d) in graph.edges.data() if (x,y) in edges_path or (y,x) in edges_path]
short_path_trust_dict = {'Path%s' % [u,v] : sum(pondered_trust)/sum(intersection)}
print(type(short_path_trust_dict))
回傳 :
short_path_trust(user_trust_cardinality_network.subgraph([30,40,71,145,638,783,893]), edges_to_predict_sub, 2)
<class 'dict'>
<class 'dict'>
<class 'dict'>
<class 'dict'>
<class 'dict'>
<class 'dict'>
<class 'dict'>
<class 'dict'>
<class 'dict'>
<class 'dict'>
<class 'dict'>
<class 'dict'>
<class 'dict'>
<class 'dict'>
如果我要求創建資料庫,這是我的主要問題:
def short_path_trust (graph, edges_to_predict,cutoff) :
short_path_trust_dict = []
for (u,v) in edges_to_predict :
for edges_path in nx.all_simple_edge_paths(graph, u, v, cutoff):
pondered_trust = [d['Pondered_Trust'] for (x,y,d) in graph.edges.data() if (x,y) in edges_path or (y,x) in edges_path]
intersection = [d['Intersection'] for (x,y,d) in graph.edges.data() if (x,y) in edges_path or (y,x) in edges_path]
short_path_trust = [((u,v), sum(pondered_trust)/sum(intersection))]
short_path_trust_df = pd.DataFrame(short_path_trust, columns= ['Nodes','Path_Trust'])
print(short_path_trust_df)
我得到:
short_path_trust(user_trust_cardinality_network.subgraph([30,40,71,145,638,783,893]), edges_to_predict_sub, 2)
Nodes Path_Trust
0 (40, 30) 0.085
Nodes Path_Trust
0 (40, 30) 0.163333
Nodes Path_Trust
0 (40, 638) 0.078333
Nodes Path_Trust
0 (40, 638) 0.103333
Nodes Path_Trust
0 (40, 638) 0.1572
Nodes Path_Trust
0 (145, 30) 0.075
Nodes Path_Trust
0 (145, 30) 0.054444
Nodes Path_Trust
0 (30, 638) 0.0175
Nodes Path_Trust
0 (30, 638) 0.01
Nodes Path_Trust
0 (30, 893) 0.165556
Nodes Path_Trust
0 (30, 893) 0.194865
Nodes Path_Trust
0 (893, 638) 0.158158
Nodes Path_Trust
0 (893, 638) 0.062
Nodes Path_Trust
0 (893, 638) 0.19
然而,我的目標是得到一個這樣的 DataFrame:
Nodes Path_Trust
0 (40, 30) 0.085
1 (40, 30) 0.163333
2 (40, 638) 0.078333
3 (40, 638) 0.103333
4 (40, 638) 0.1572
5 (145, 30) 0.075
6 (145, 30) 0.054444
7 (30, 638) 0.0175
8 (30, 638) 0.01
9 (30, 893) 0.165556
10 (30, 893) 0.194865
11 (893, 638) 0.158158
12 (893, 638) 0.062
13 (893, 638) 0.19
或更好 :
Node1 Node 2 Trust
0 40 30 0.085
1 40 30 0.163333
2 40 638 0.078333
3 40 638 0.103333
4 40 638 0.1572
5 145 30 0.075
6 145 30 0.054444
7 30 638 0.0175
8 30 638 0.01
9 30 893 0.165556
10 30 893 0.194865
11 893 638 0.158158
12 893 638 0.062
13 893 638 0.19
我希望我很好地解釋了我的問題。如果您需要更多資訊,我會盡力提供。感謝您的幫助:)
uj5u.com熱心網友回復:
在您的代碼中,您為每個節點對創建一個與舊字典同名的新字典,因此您正在覆寫資料。即使你解決了這個問題,當你比較相同的節點時,你也會遇到重復鍵的問題。
相反,我建議使用一個串列,如下所示:
def short_path_trust (graph, edges_to_predict,cutoff) :
short_path_trust_list = []
for (u,v) in edges_to_predict :
for edges_path in nx.all_simple_edge_paths(graph, u, v, cutoff):
pondered_trust = [d['Pondered_Trust'] for (x,y,d) in graph.edges.data() if (x,y) in edges_path or (y,x) in edges_path]
intersection = [d['Intersection'] for (x,y,d) in graph.edges.data() if (x,y) in edges_path or (y,x) in edges_path]
short_path_trust_list.append([u,v, sum(pondered_trust)/sum(intersection)])
return pd.DataFrame(short_path_trust_list, columns=['node1', 'node2', 'trust'])
一般來說,雖然您的帖子非常詳細,但我無法重現您的問題,因為您沒有定義從中獲取子圖的圖表。
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/432099.html
上一篇:React:根據值型別渲染物件