uj5u.com熱心網友回復:
在您的情況下,以下示例公式怎么樣?
示例公式:
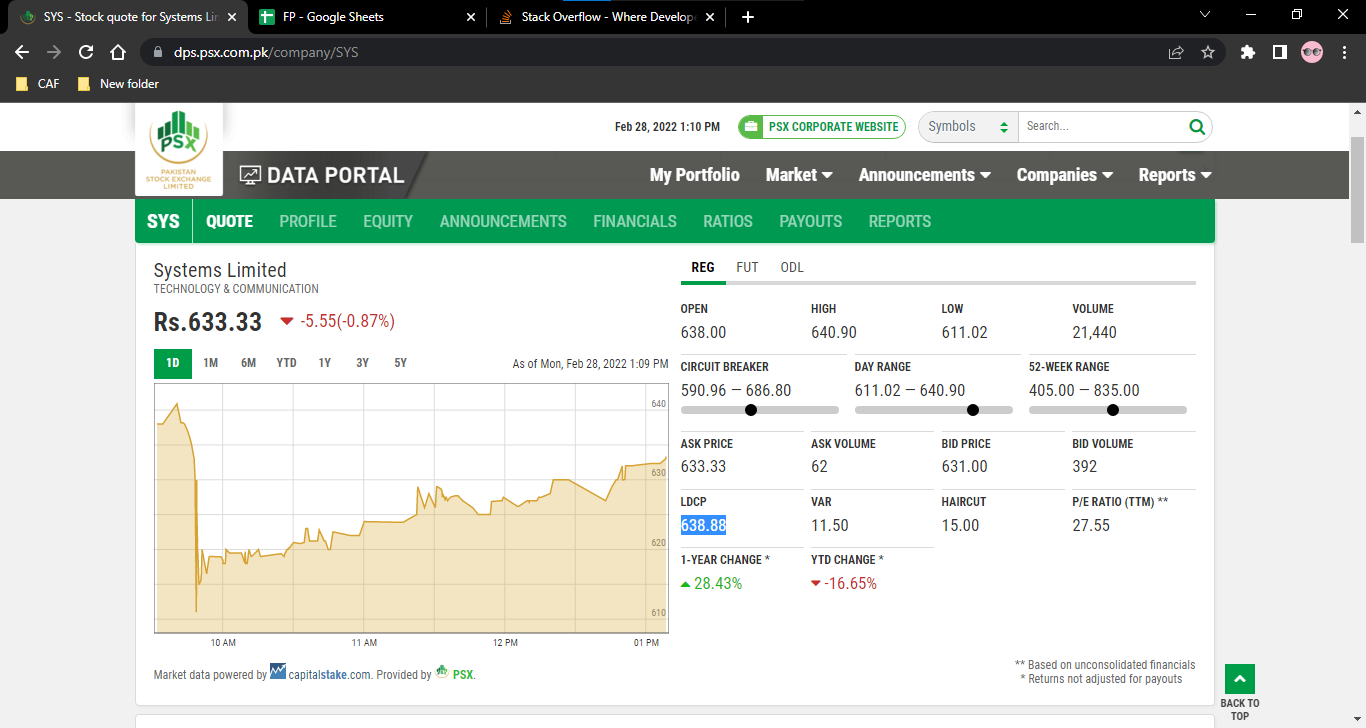
=IMPORTXML(A1,"//div[@data-name='REG']//div[div[@class='stats_label']/text()='LDCP']/div[@class='stats_value']")
在這種情況下,URL
https://dps.psx.com.pk/company/SYS被放在單元格“A1”中。當您要將值放入單元格“B2”時,請放入
=IMPORTXML("https://dps.psx.com.pk/company/SYS","//div[@data-name='REG']//div[div[@class='stats_label']/text()='LDCP']/div[@class='stats_value']")單元格“B2”。我認為在這種情況下,也可以使用以下公式。
=IMPORTXML(A1,"//div[@data-name='REG']//div[@class='stats_value'][../div[@class='stats_label']/text()='LDCP']")
結果:

筆記:
- 此示例公式的 XPath 用于您的 URL
https://dps.psx.com.pk/company/SYS。因此,當您更改 URL 時,XPath 可能無法使用。所以請注意這一點。
uj5u.com熱心網友回復:
您可以使用
=REGEXEXTRACT(INDEX(IMPORTXML(A1,"//div[@data-name='REG']"),2,4),"LDCP(\d \.\d )")

假設=TRANSPOSE(IMPORTXML(A1,"//div[@data-name='REG']"))會給你這些資訊
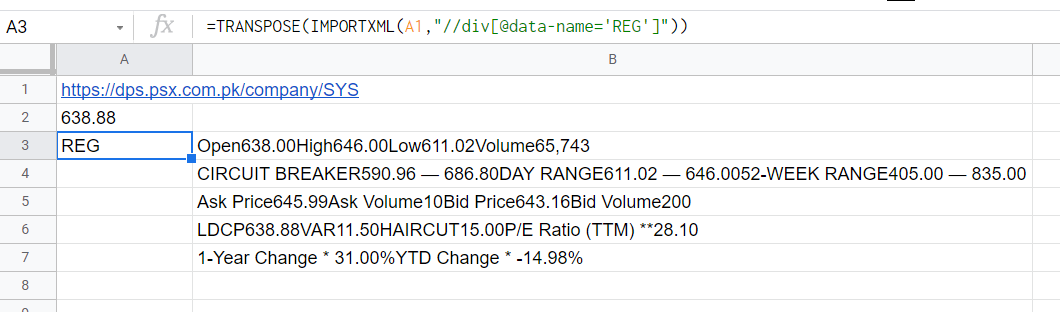
通過index我獲取我需要的單元格,然后我應用一個簡單的regexextract公式。
這樣您就可以輕松檢索其他資訊。
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/434961.html