我正在研究一個時間表系統,需要所有空閑時間(學生沒有講座)。現在它列印出整個時間表。我只需要將所有空閑插槽存盤在某個地方。他們在時間表上顯示為“NaN”。這是我的代碼。
from bs4 import BeautifulSoup
import pandas as pd
import requests
import time
import natsort as ns
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.support.ui import Select
s = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=s)
driver.maximize_window() #opens up website, probably not needed.
driver.implicitly_wait(30)
driver.get('https://opentimetable.dcu.ie/')
select = Select(driver.find_element_by_tag_name("select"))
select.select_by_visible_text("Programmes of Study")
search = driver.find_element_by_id("textSearch")
search.send_keys("CASE2")
checkbox = driver.find_element_by_xpath('.//input[following-sibling::div[contains(text(), "CASE2")]]') # it works but it is harder to remeber
checkbox.click()
time.sleep(3)
html = driver.find_element_by_id("week-pdf-content").get_attribute('outerHTML')
df2 = pd.read_html(html)[0]
#trying to print free slots
x = 0
if df2[x] == "NaN":
print(df[x])
x =1
print(df2.to_string()) # to_string() to display all columns without `...`
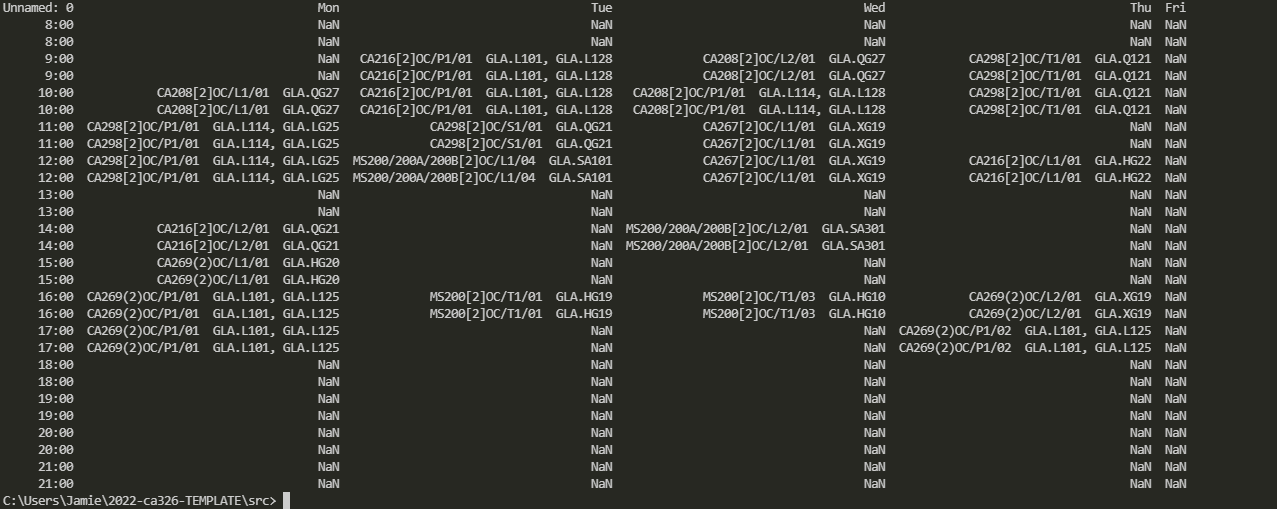
預期的輸出將是列印出來的所有空閑時間。例如星期一:11-12、13-14、16-17。對于每一天。
這是當前輸出如您所見,它只是列印出時間表。我想存盤它說 NaN 的所有時間
uj5u.com熱心網友回復:
注意: 這只是一種適應的沖動,您應該能夠自己進行微調。
根據您的更新,我現在知道輸出應該是什么。為了簡單地以類似結構輸出資訊,如果您已將保持時間的第一列設定為索引,則可以遍歷資料幀的每一列。
df = df2.set_index('Unnamed: 0') #or df = df2.set_index(list(df2.columns[[0]]))
for column in df:
print(f'{column}:{", ".join(df[df[column].isna()].index.drop_duplicates().to_list())}')
輸出
Mon:8:00, 9:00, 13:00, 18:00, 19:00, 20:00, 21:00
Tue:8:00, 13:00, 14:00, 15:00, 17:00, 18:00, 19:00, 20:00, 21:00
Wed:8:00, 13:00, 15:00, 17:00, 18:00, 19:00, 20:00, 21:00
Thu:8:00, 11:00, 13:00, 14:00, 15:00, 18:00, 19:00, 20:00, 21:00
Fri:8:00, 9:00, 10:00, 11:00, 12:00, 13:00, 14:00, 15:00, 16:00, 17:00, 18:00, 19:00, 20:00, 21:00
要將這些資訊存盤在 dict 中:
data = []
for column in df:
data.append({column:df[df[column].isna()].index.drop_duplicates().to_list()})
輸出
[{'Mon': ['8:00', '9:00', '13:00', '18:00', '19:00', '20:00', '21:00']}, {'Tue': ['8:00', '13:00', '14:00', '15:00', '17:00', '18:00', '19:00', '20:00', '21:00']}, {'Wed': ['8:00', '13:00', '15:00', '17:00', '18:00', '19:00', '20:00', '21:00']}, {'Thu': ['8:00', '11:00', '13:00', '14:00', '15:00', '18:00', '19:00', '20:00', '21:00']}, {'Fri': ['8:00', '9:00', '10:00', '11:00', '12:00', '13:00', '14:00', '15:00', '16:00', '17:00', '18:00', '19:00', '20:00', '21:00']}]
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/435274.html