給定這個資料集:
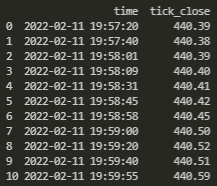
...我想創建開放的高低列,重新采樣到每行的開始分鐘。請注意,我們不能簡單地.resample()在這種情況下使用。我希望得到的是一個如下所示的資料集:
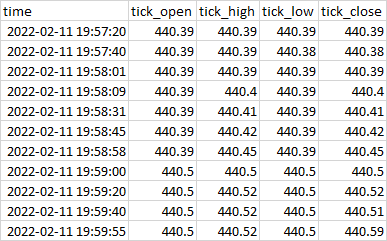
我不想為此使用 for 回圈,而是對開放、高和低列進行列計算(除非有更快的方法來執行此操作,或者.resample()在這種情況下可以以某種方式作業)。
時間列是pd.to_datetime()格式。
我試圖為 max 列做這樣的事情:
tick_df['tick_high'] = tick_df[(tick_df['time'] >= tick_df['time'].replace(second=0)) & (tick_df['time'] <= tick_df['time'])].max()
...這里的邏輯是,選擇分鐘頂部的當前日期時間時間(所以 0 秒)之間的行,并轉到當前行的日期時間。因此,如果查看第一行,示例將介于2022-02-11 19:57:00to之間。2022-02-11 19:57:20
但是,當我嘗試這個時,我得到了錯誤:
TypeError: replace() got an unexpected keyword argument 'second'
...因為從技術上講,我使用的是 pandas 的替換功能,而不是 datetime.replace 功能。所以我也嘗試在.dt之前添加.replace并得到這個:
AttributeError: 'DatetimeProperties' object has no attribute 'replace'
關于如何實作所需輸出的任何建議?作為參考,這是我的可重現代碼:
from datetime import datetime
import pandas as pd
# create a mock tick df
tick_time = ["2022-02-11 19:57:20",
"2022-02-11 19:57:40",
"2022-02-11 19:58:01",
"2022-02-11 19:58:09",
"2022-02-11 19:58:31",
"2022-02-11 19:58:45",
"2022-02-11 19:58:58",
"2022-02-11 19:59:00",
"2022-02-11 19:59:20",
"2022-02-11 19:59:40",
"2022-02-11 19:59:55"]
tick_time = pd.to_datetime(tick_time)
tick_df = pd.DataFrame(
{
"time": tick_time,
"tick_close": [440.39,440.38,440.39,440.40,440.41,440.42,440.45,440.50,440.52,440.51,440.59],
},
)
print(tick_df)
# Attempt to resample ticks ohlc from the beginning of each minute
tick_df['tick_high'] = tick_df[(tick_df['time'] >= tick_df['time'].dt.replace(second=0)) & (tick_df['time'] <= tick_df['time'])].max()
我明天會回來查看答案。謝謝!
uj5u.com熱心網友回復:
IIUC,你想要嗎?
i = pd.Index(['first','cummax','cummin'])
tick_df.join(
pd.concat([tick_df.groupby(pd.Grouper(key='time', freq='T'))['tick_close']
.transform(c)
.rename(f'tick_{c}')
for c in i], axis=1)
)
輸出:
time tick_close tick_first tick_cummax tick_cummin
0 2022-02-11 19:57:20 440.39 440.39 440.39 440.39
1 2022-02-11 19:57:40 440.38 440.39 440.39 440.38
2 2022-02-11 19:58:01 440.39 440.39 440.39 440.39
3 2022-02-11 19:58:09 440.40 440.39 440.40 440.39
4 2022-02-11 19:58:31 440.41 440.39 440.41 440.39
5 2022-02-11 19:58:45 440.42 440.39 440.42 440.39
6 2022-02-11 19:58:58 440.45 440.39 440.45 440.39
7 2022-02-11 19:59:00 440.50 440.50 440.50 440.50
8 2022-02-11 19:59:20 440.52 440.50 440.52 440.50
9 2022-02-11 19:59:40 440.51 440.50 440.52 440.50
10 2022-02-11 19:59:55 440.59 440.50 440.59 440.50
uj5u.com熱心網友回復:
基于GitHub票,我們可以使用map
tick_df['time'].map(lambda x : x.replace(second=0))
得到你的輸出
cond1 = tick_df['time'].map(lambda x : x.replace(second=0))
tick_df['tick_high'] = [tick_df.loc[(tick_df['time']>=x) & (tick_df['time']<=y) ,'tick_close'].max() for x, y in zip(cond1,tick_df['time'])]
tick_df
Out[552]:
time tick_close tick_high
0 2022-02-11 19:57:20 440.39 440.39
1 2022-02-11 19:57:40 440.38 440.39
2 2022-02-11 19:58:01 440.39 440.39
3 2022-02-11 19:58:09 440.40 440.40
4 2022-02-11 19:58:31 440.41 440.41
5 2022-02-11 19:58:45 440.42 440.42
6 2022-02-11 19:58:58 440.45 440.45
7 2022-02-11 19:59:00 440.50 440.50
8 2022-02-11 19:59:20 440.52 440.52
9 2022-02-11 19:59:40 440.51 440.52
10 2022-02-11 19:59:55 440.59 440.59
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/438191.html
標籤:python-3.x 熊猫 约会时间 OHLC