目錄
- 垃圾回收器與記憶體分配策略
- 1.1 起源
- 1.2 物件已死?
- 1.2.1 參考計數演算法
- 1.2.2 可達性演算法
- 1.2.3 四大參考
- 1.2.4 finalize()方法
- 1.2.5 回收方法區
- 1.3 垃圾回收演算法
- 1.3.1 分代收集理論
- 1.3.2 標記-清除演算法
- 1.3.3 標記-復制演算法
- 1.3.4 標記-整理演算法
垃圾回收器與記憶體分配策略
1.1 起源
Lisp是第一門開始使用記憶體動態分配和垃圾收集技術的語言
作者John McCarthy思考過垃圾收集需要完成的哪三件事?
- 哪些記憶體需要回收?
- 什么時候回收?
- 如何回收?
程式計數器、虛擬機堆疊、本地方法區隨執行緒而生,隨執行緒而滅,堆疊中的堆疊幀隨著方法的進入和退出,有條不紊的執行著出堆疊和進堆疊的操作,這幾個記憶體分配具有確定性,不需要考慮記憶體回收的問題
堆和方法區這兩個區域則由很多的不確定性:一個介面的多個實作類記憶體需要可能不一樣…
只有處于運行期間,我們才能知道程式創建哪些物件,創建多少個物件,這部分記憶體的分配和回收是動態的,垃圾收集器關注的正是這部分記憶體該如何存盤
1.2 物件已死?
在堆中存放Java的所有物件實體,垃圾收集器在對堆進行回收前,第一件事就是要確定哪些物件是死的,哪些物件是存活的,
1.2.1 參考計數演算法
判斷物件是否存活的條件:在物件中添加一個參考計數器,每當有一個地方參考時,參考計數器+1,當參考失效時,參考計數器-1,任何時刻參考計數為零的物件就是不可能再被使用的
在其他語言中,有的使用了參考計數演算法,但在Java中,我們就沒有使用該演算法,原因是:這個看似簡單的演算法,必須要配合大量的處理才能合理的運行,比如:物件之間的回圈參考,基本無法解決
public class YinYong {
public Object instance = null;
public static void main(String[] args) {
YinYong test1 = new YinYong();
YinYong test2 = new YinYong();
test1.instance = test2;
test2.instance = test1;
test1 = null;
test2 = null;
System.gc();
}
}
關于上面這個回圈參考的演算法,《深入理解Java虛擬機》并沒有介紹特別清楚,這里詳細介紹一下
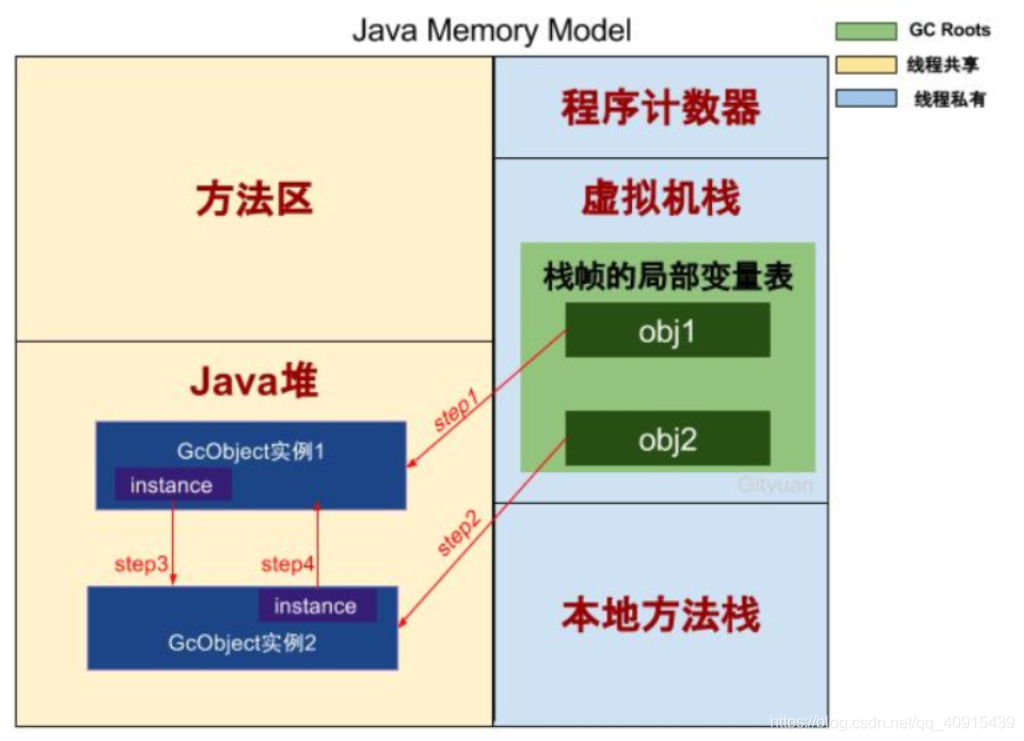
執行緒私有區
- 程式計數器:記錄正在執行的虛擬機位元組碼的地址
- 虛擬機堆疊:方法執行的記憶體區,每個方法執行時都會在虛擬機堆疊中創建堆疊幀
- 本地方法堆疊:虛擬機的Native方法執行的記憶體區
執行緒共享區
- Java堆:物件分配的區域,這是垃圾回收的主要區域
- 方法區:存放著類資訊、常量、靜態變數等資料、常量池
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-T5YaM7nX-1599899310955)(C:\Users\黃良帥\AppData\Roaming\Typora\typora-user-images\1599651456948.png)]](https://img.uj5u.com/2020/09/15/70452150831112.png)
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-1WOvLUaC-1599899310961)(C:\Users\黃良帥\AppData\Roaming\Typora\typora-user-images\1599651471659.png)]](https://img.uj5u.com/2020/09/15/70452150831113.png)
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-v8UhF77J-1599899310965)(C:\Users\黃良帥\AppData\Roaming\Typora\typora-user-images\1599651482026.png)]](https://img.uj5u.com/2020/09/15/70452150831114.png)
1.2.2 可達性演算法
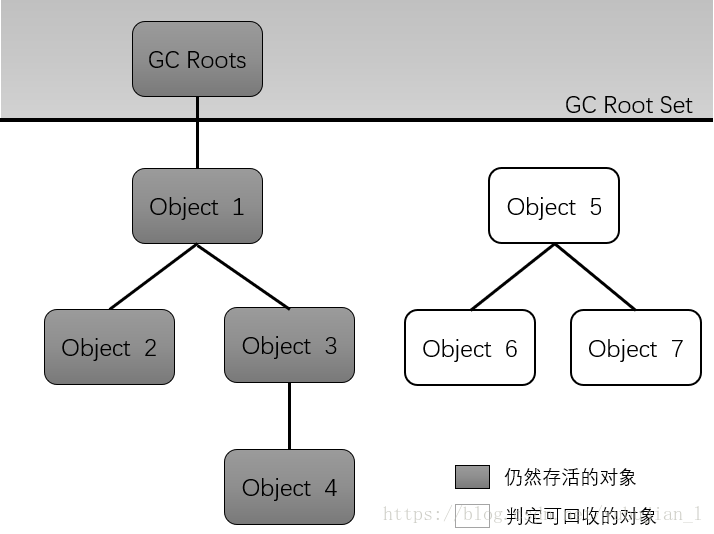
演算法思路:通過一系列成為"GC Roots"的根物件作為起始節點集,從這些節點開始,根據參考關系向下搜索,搜索程序中的路徑被稱為"參考鏈",如果某個物件到GC Roots之間沒有參考鏈連接的話或者圖論也就是不可達,那么這個物件就可以被回收了
GC Root的物件:
-
虛擬機堆疊中參考的物件
-
方法區中類靜態屬性參考的物件
-
常量池中參考的物件
-
本地方法堆疊JNI,也就是Native參考的物件
1.2.3 四大參考
無論是參考計數法還是可達性分析,都離不開參考這個詞,在Java中參考主要有強參考、軟參考、弱參考、虛參考,
-
強參考—不回收、 StrongReference
? 對于強參考來說,是我們經常使用的大部分都是強參考,如果一個物件具有強參考,那就類似于必不可少的生活用品,垃圾回收器不會回收它,當我們的空間不足時,JVM寧愿拋出OutOfMemoryError也就是記憶體溢位,讓程式終止,也不會靠隨意的回收具有強參考的物件來解決記憶體不足的問題
StringBuffer buffer = new StringBuffer(); StringBuffer buffer1 = buffer;對于一個普通的物件,如果沒有其他參考的關系,只要超過了參考的作用域或者將強參考賦值為null,就是可以當做垃圾被收集了
-
軟參考—有用但非需、記憶體不足既回收、 SoftReference
-
記憶體足夠時,不會回收軟參考的可達物件
-
當記憶體不夠時,就會進行回收可達物件,如果回收完之后,記憶體還不夠,就會報OOM
user u1 = new user( 1,"songhk"); softReference<User> userSoftRef = new SoftReference<User>(u1); ul = null;軟參考通常實作快取,比如:圖片快取和網頁快取用到軟參考
如果還有空間,就可以暫時保留快取,當記憶體不足時清理掉,這樣就保證了使用快取的同 時,不會耗盡記憶體
-
-
弱參考----發現既回收、WeakReference
弱參考也是用來描述那些非必需物件,只被弱參考關聯的物件只能生存到下一次垃圾收集發生為止,在系統GC時,只要發現弱參考,不管系統堆空間使用是否充足,都會回收掉只被弱參考關聯的物件,
例子:存盤可有可無的資料:
WeakHashMap:記憶體不足時就會被回收,內部的Entry繼承類WeakReference
-
虛參考——物件回收跟蹤、Phantom Reference
一個物件是否有虛參考的存在,完全不會決定物件的生命周期,如果一個物件僅有虛參考,那么它和沒有參考幾乎是一樣的,隨時都可能被垃圾回收器回收
它不能單獨使用,必須和參考佇列( ReferenceQueue ),當垃圾回收器準備回收物件時,如果發現他還有虛參考,就會在回收物件的回收之前,把這個虛參考加入到參考佇列中,從而可以查看當前JVM垃圾回收的情況
1.2.4 finalize()方法
如果一個物件經過我們可達性演算法的計算,判定為不可達的物件,并不是直接將其進行殺死 ,而是進入到一個緩刑的階段
真正宣告一個物件是否死亡要經歷兩次標記程序:
- 如果物件在進行可達性分析后,發現物件不可達,則將會進行第一次標記,隨后進行一次篩選,條件為:是否有必要執行finalize方法,如果物件沒有重寫finalize方法或者finalize已經被呼叫一次,JVM判定沒有必要執行,直接進行回收
- 如果JVM判定有必要執行finalize的話,會將其放在一個F-Quene的佇列中,并執行物件的finalize方法,同樣JVM對佇列中的物件進行標記,如果這時候物件的finalize方法中,將自己與參考鏈上的任何一個物件建立了聯系,那樣,JVM就會在第二次標記的時候將它移出“即將回收”的集合
建議:因為finalize方法的出現具有一定的戲劇色彩,為了使C、C++的程式猿更容易接受而做出的妥協
1.2.5 回收方法區
方法區主要回收兩部分內容:廢棄的常量和不再使用的型別
而對于一個型別是否被回收就比較困難,需要滿足三個條件:
- 所有的實體都被回收,也就是堆中不存在該類和派生子類
- 加載該類的加載器也被回收(基本不可能達成)
- 該類在java.lang.Class物件沒有在任何地方參考
1.3 垃圾回收演算法
垃圾收集演算法可以劃分為”參考計數式垃圾收集“和”追蹤式垃圾收集“
1.3.1 分代收集理論
兩個假說:
- 弱分代假說:絕大多數的物件都是朝生夕滅的
- 強分代假說:熬過越多次垃圾收集程序的物件就越難以消亡
設計原則:收集器應該將Java堆劃分不同的區域,然后將回收物件依據其年齡分配到不同的區域進行存盤
設計者將堆分為新生代和老年代兩個區域,本來這種想法挺好的,但是出現了一個問題,也就是物件之間會存在跨代參考
我們要對新生代的物件進行垃圾的收集,但某個物件參考了老年代中的資料,不得不再去遍歷老年代中的物件來確保可達性分析結果的準確性
所以,為這個理論增添了第三條經驗法則:
- 跨代參考假說:跨代參考相對于同代參考來說,僅占少數
基于這條假說,我們對于那些隔代參考的物件,不再去單獨的掃描他們,而是將他們放在一個新生代記憶集的資料結構中
部分收集—Partial GC
- 新生代收集:目標是新生代的
- 老年代收集:目標是老年代的 CMS收集器
- 混合收集:目標整個新生代和部分老年代 G1收集器
整堆收集----Full GC:收集整個Java堆和方法區的垃圾收集
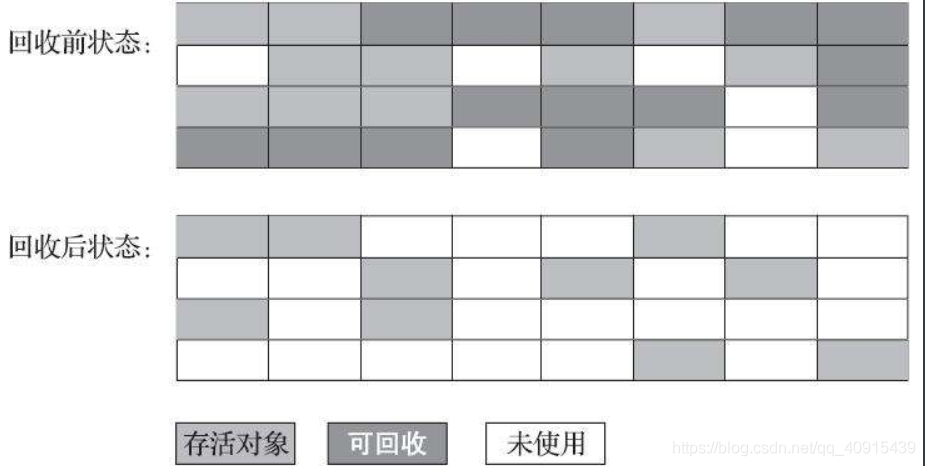
1.3.2 標記-清除演算法
這是最早出現的垃圾清除演算法
演算法分為兩個階段:先對要回收的物件進行標記,然后再進行回收
缺點:
- 執行效率不穩定:堆中有大量物件,會進行大量的標記和清除
- 內部的碎片化問題:標記和清除之后會產生大量的不連續的記憶體碎片
1.3.3 標記-復制演算法
半區復制的垃圾收集演算法
將可用記憶體按容量劃分為大小相等的兩塊,每次使用其中的一塊,當這一塊的記憶體用完了,就將還存活著的物件復制到另一塊上面,然后再把使用過的記憶體空間一次性清理掉,
在1989年,提出了一種更加優化的半區復制演算法,將新生代分成了一塊較大的伊甸園區和兩塊較小的幸存區
每次分配記憶體只使用伊甸園和一塊幸存區,發生垃圾收集時,將伊甸園和幸存區存活的物件一次性復制到另外一個幸存區,然后直接清理掉伊甸園和已用過的幸存區,
在新生代中的物件存活比較少,所以可以一次性復制到幸存區,但是如果萬一超過了記憶體,怎么辦?
需要依賴其他記憶體區域,也就是老年代進行記憶體分配擔保
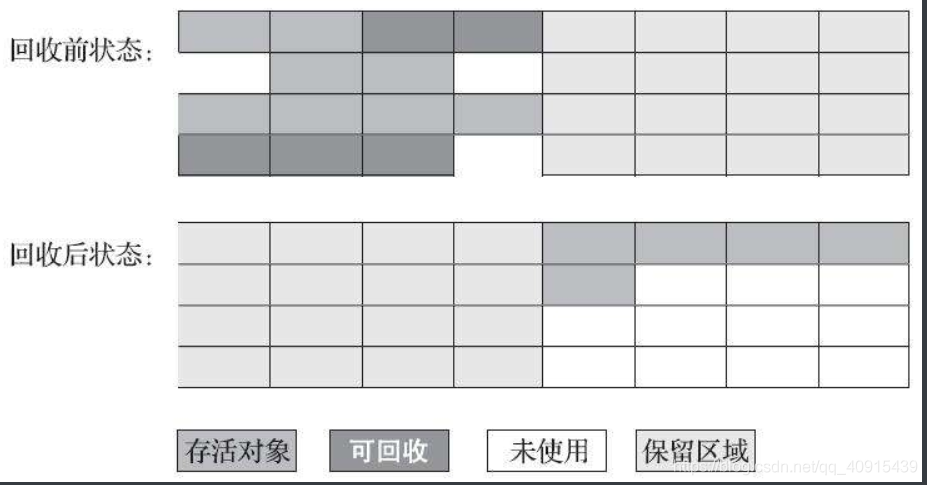
優點:不會產生記憶體碎片
缺點:記憶體間賦值開銷 只有一半空間可用 空間浪費太多
1.3.4 標記-整理演算法
標記程序仍然使用標記-清除,后序步驟將所有存活的物件都向記憶體空間一端移動,然后清理掉邊界以外的記憶體
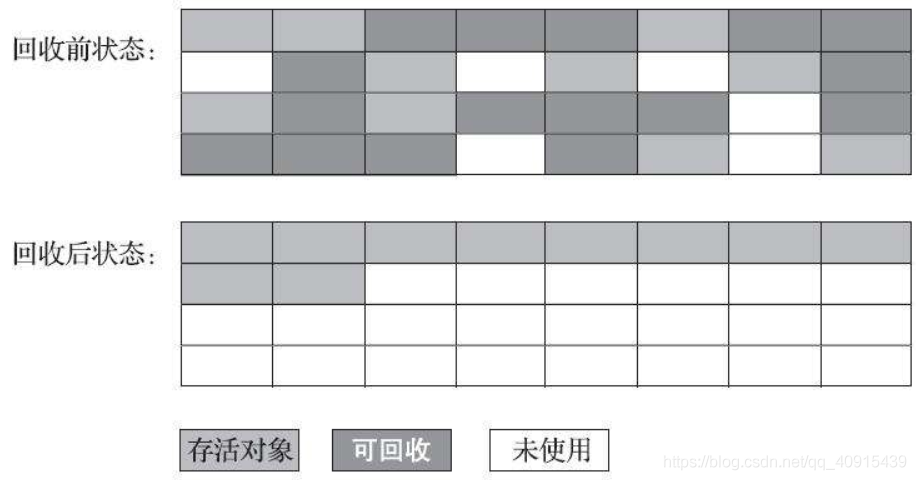
缺點:在每次移動的程序中,尤其是對老年代這種存活物件多的區域,會導致效率的降低
優點:沒有了記憶體碎片的產生
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/44713.html
標籤:其他