我有一個資料框,我想根據 id 對資料進行分組,然后將每個 id 的值粘貼在一起。但是,由于 id 的數量不相等,我必須用 填充這些 id 的缺失值mean of the day before。
我提供了一個示例如下,例如,對于id=1,id=2有兩個日期,但對于id=3,有三天。
df = pd.DataFrame()
df['id'] = [1, 1, 2,2, 3, 3, 3]
df['date'] = ['2019-01-01', '2019-01-03', '2019-01-01','2019-01-02', '2019-01-01', '2019-01-02','2019-01-03']
df['val1'] = [10, 100, 20, 30, 40, 50, 60]
df['val2'] = [30, 30, -20, -30, -40,-50, -60 ]
df['val3'] = [50, 10, 120, 300, 140, 150, 160]
我嘗試過使用以下代碼:
DF_sticked = df.filter(regex='val\d ', axis=1).groupby(df['id'])\
.apply(np.ravel).apply(pd.Series).rename(lambda x: f"val{x}", axis=1).reset_index().fillna(0)
但是,在上面的代碼中,我用 0 填充了缺失值。缺失值也在列的末尾。我想要的輸出如下。如您所見,val 4, val5, val 6ofid=1與前一天的平均值相同。或val 7, 8, 9 of id=2等于前一天的平均值(30、-30、300 的平均值)
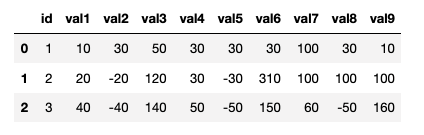
太感謝了。
uj5u.com熱心網友回復:
IIUC,計算之間的笛卡爾積id并date填充缺失的日期,然后使用您的代碼:
mi = pd.MultiIndex.from_product([df['id'].unique(), df['date'].unique()], names=['id', 'date'])
df = df.set_index(['id', 'date']).reindex(mi).sort_index().ffill()
# Your code
df = df.groupby(level='id').apply(np.ravel).apply(pd.Series).add_prefix('val')
輸出:
>>> df
val0 val1 val2 val3 val4 val5 val6 val7 val8
id
1 10.0 30.0 50.0 10.0 30.0 50.0 100.0 30.0 10.0
2 20.0 -20.0 120.0 30.0 -30.0 300.0 30.0 -30.0 300.0
3 40.0 -40.0 140.0 50.0 -50.0 150.0 60.0 -60.0 160.0
uj5u.com熱心網友回復:
您實際上可以旋轉資料框,然后將日期、transform('mean')和分組ffill:
tmp = df.pivot(index='id', columns='date').swaplevel(axis=1).sort_index(axis=1)
tmp[tmp.isna()] = tmp.groupby(level=0, axis=1).transform('mean').ffill(axis=1)
tmp = tmp.astype(int).droplevel(0, axis=1)
# Fix the columns
tmp = tmp.set_axis(np.arange(1, tmp.shape[1] 1).astype(str), axis=1).add_prefix('val')
輸出:
>>> tmp
val1 val2 val3 val4 val5 val6 val7 val8 val9
id
1 10 30 50 30 30 30 100 30 10
2 20 -20 120 30 -30 300 100 100 100
3 40 -40 140 50 -50 150 60 -60 160
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/448262.html
下一篇:我如何在一行代碼中撰寫它?