如何從以元組為值的字典創建 pyspark 資料框?
[['HNN', (0.5083874458874459, 56)], ['KGB', (0.7378654301578141, 35)], ['KHB', (0.6676891615541922, 18)]]
輸出應該看起來像那樣(請參閱附加的 ss)
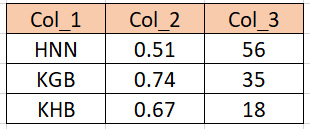
uj5u.com熱心網友回復:
我能想到的最簡單的方法是在每個串列中合并字串和元組。
這可以通過串列理解來完成,您將元素 0(字串)和解包元素 1(元組)使用*到串列串列中的每個串列的串列中。
l= [['HNN', (0.5083874458874459, 56)], ['KGB', (0.7378654301578141, 35)], ['KHB', (0.6676891615541922, 18)]]
df = spark.createDataFrame([[x[0],*x[1]] for x in l], ['col_1','col_2','col_3'])
輸出
----- ------------------ -----
|col_1| col_2|col_3|
----- ------------------ -----
| HNN|0.5083874458874459| 56|
| KGB|0.7378654301578141| 35|
| KHB|0.6676891615541922| 18|
----- ------------------ -----
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/451060.html
上一篇:字典中的字典