我正在嘗試在使用自定義相似度函式時構建相似度矩陣。問題是代碼運行速度很慢。
我有一個如下所示的資料框:
col1 col2 col3
'car' 'A' 'cat'
'car' 'C' 'dog'
'bike' 'A' 'cat'
...
我有一系列權重,將重要性歸于某一列 [0.1, 0.5, 0.4]
我想計算自定義相似度矩陣中的行之間的相似度,如果行對具有相同的值,則它們是相似的(考慮到使某些列比其他列更重要的權重)
我當前的相似性將兩個陣列作為輸入,并使用一些權重檢查它們之間有多少元素相同(這是一個與 x 和 y 長度相同的陣列)
def custom_similarity(x, y, weights):
similarity = np.dot((x == y).values*1,weights)
return(similarity)
給定一個資料框,其中每一行代表要比較的陣列之一,我想使用該函式生成資料框的相似性矩陣。
目前我正在做這樣的事情(所以填充一個空矩陣),它可以作業但它非常慢:
sim_matrix = np.zeros((len(df),len(df)))
for i in tqdm(range(len(df))):
obs_i = df.iloc[i,:]
for j in range(i, len(df)):
obs_j = df.iloc[j,:]
sim_matrix[i,j] = sim_matrix[j,i] = custom_similarity(obs_i, obs_j, weights)
我怎樣才能提高效率并加快速度?
uj5u.com熱心網友回復:
一種方法是使用scipy.spatial. 這已經比你自己滾動的效率高得多了。特別是,您可以使用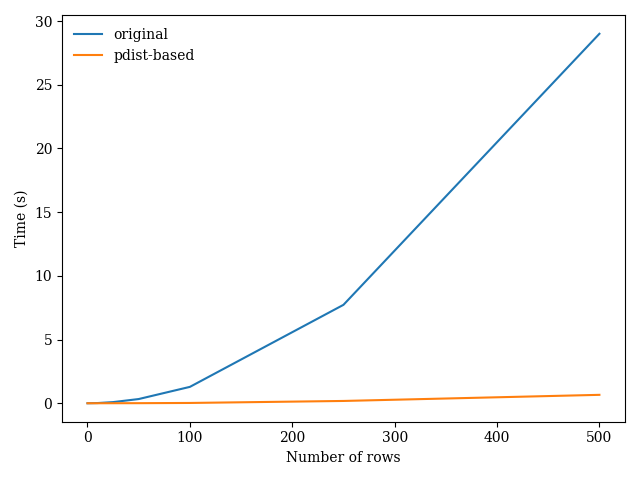
uj5u.com熱心網友回復:
嘗試這個 :
from functools import partial
custom_similarity = partial(custom_similarity, weights=weights)
sim_matrix = df.T.corr(custom_similarity)
(根據資料框,您可能需要custom_similarity通過洗掉來修改.values。還假設權重已標準化)
解釋:
partial是一個函式,它處理不能輕易傳遞給另一個函式的附加引數。在這種情況下,我們處理權重。
接下來我們必須轉置資料幀,因為corr基于列計算系數,最后我們custom_similarity作為“規則”傳遞以進行關聯。
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/452834.html
上一篇:python中的字謎演算法