我正在使用隨機森林解決二元分類問題,并使用 LIME 解釋器來解釋預測。
我使用下面的代碼來生成 LIME 解釋
import lime
import lime.lime_tabular
explainer = lime.lime_tabular.LimeTabularExplainer(ord_train_t.values, discretize_continuous=True,
feature_names=feat_names,
mode="classification",
feature_selection = "lasso_path",
class_names=rf_boruta.classes_,
categorical_names=output,
kernel_width=10, verbose=True)
i = 969
exp = explainer.explain_instance(ord_test_t.iloc[1,:],rf_boruta.predict_proba,distance_metric = 'euclidean',num_features=5)
我得到如下輸出
Intercept 0.29625037124439896
Prediction_local [0.46168824]
Right:0.6911888737552843
但是,以上內容在螢屏上列印為訊息
我們如何在資料框中獲取這些資訊?
uj5u.com熱心網友回復:
Lime 沒有直接匯出到資料框的功能,因此要走的路似乎是將預測附加到串列中,然后將其轉換為資料框。
是的,根據您有多少預測,這可能需要很多時間,因為模型必須單獨預測每個實體。
這是我找到的一個示例,explain_instance需要根據您的模型引數進行調整,但遵循相同的邏輯。
l=[]
for n in range(0,X_test.shape[0] 1):
exp = explainer.explain_instance(X_test.values[n], clf.predict_proba, num_features=10)
a=exp.as_list()
l.append(a)
df = pd.DataFrame(l)
如果您需要的比 as_list() 提供的更多,解釋器會提供更多資料。我運行了一個示例來查看解釋實體會檢索到的其他內容。
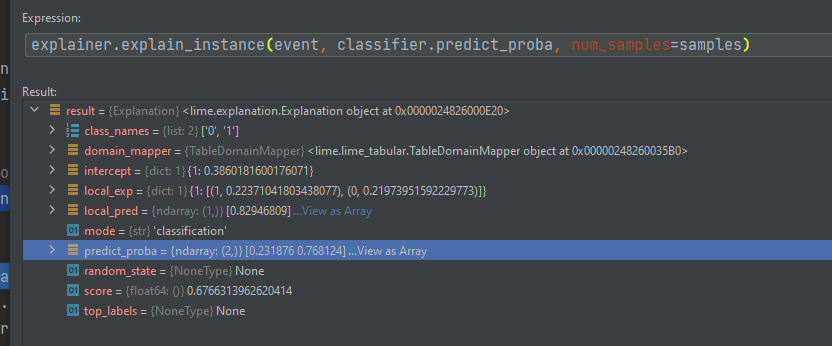
您可以不只是使用 as_list(),而是將您需要的其他值附加到此 as_list。
a = exp.to_list()
a.append(exp.intercept[1])
l.append(a)
使用這種方法,您可以獲得截距和 prediction_local,對于正確的值,我真的不知道它會是哪一個,但我確信物件解釋器在某個地方有另一個名稱。
在您的代碼上使用斷點并探索解釋器,也許您還想保存其他資訊。
Lime Github:問題參考 213
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/453460.html