我有兩個串列,一個包含用戶輸入,另一個包含映射。
用戶輸入如下所示:
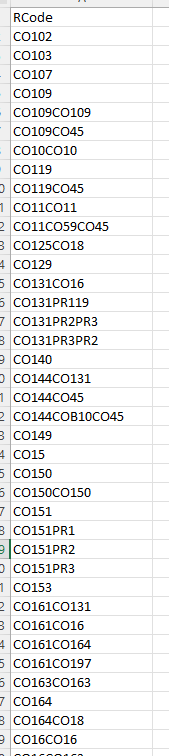
映射如下所示:
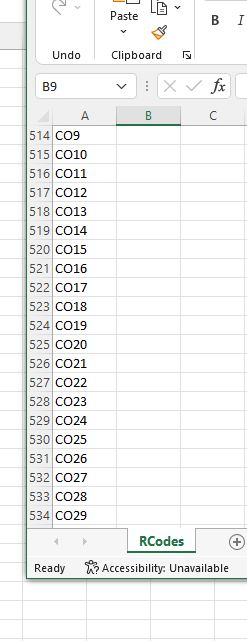
我正在嘗試拆分用戶輸入串列中的字串。有時他們輸入一個記錄為 CO109CO45,但實際上這是兩個代碼,不屬于一起。它們需要用逗號或空格分隔,例如 CO109,CO45。
有許多具有相同行為的示例,我正在考慮使用映射串列來匹配和拆分。這是可以做到的嗎?你有什么建議?在此先感謝您的幫助!
uj5u.com熱心網友回復:
在拆分中使用向前看和向后看的組合。
df = pd.DataFrame({'RCode': ['CO109', 'CO109CO109']})
print(df)
RCode
0 CO109
1 CO109CO109
df.RCode.str.split('(?<=\d)(?=\D)')
0 [CO109]
1 [CO109, CO109]
Name: RCode, dtype: object
uj5u.com熱心網友回復:
您可以嘗試使用正則運算式:
import re
l = ['CO2740CO96', 'CO12', 'CO973', 'CO870CO397', 'CO584', 'CO134CO42CO685']
df = pd.DataFrame({'code':l})
df.code = df.code.str.findall('[A-Za-z] \d ')
print(df)
Output:
code
0 [CO2740, CO96]
1 [CO12]
2 [CO973]
3 [CO870, CO397]
4 [CO584]
5 [CO134, CO42, CO685]
uj5u.com熱心網友回復:
我通常使用這樣的東西作為輸入original_list:
output_list = [
[
('CO' target).strip(' ,')
for target in item.split('CO')
]
for item in original_list
]
可能有更有效的方法可以做到這一點,但您不需要資料幀/熊貓的開銷,也不需要正則運算式的難以閱讀的方面。
如果您有可管理數量的前綴(“CO”、“PR”等),則可以在每個前綴上設定遞回函式拆分。- 或者您可以將 .find() 與完整代碼一起使用。
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/453891.html