所以基本上我對 sklearn 和使用 python 的 ML 很陌生。我習慣了 RapidMiner 和其他 GUI 工具。我有超過 200 萬行和 5 列的資料集,這是我的主成分(大約 98% 的方差)。我用 kmeans 執行了聚類并獲得了標簽。我已經知道集群的數量必須為 4,并使用 kmeans 生成的質心初始化演算法。
from sklearn.cluster import KMeans
preds = KMeans(n_clusters=4, init=centers_init).fit_predict(sc_norm_pca_data)
result = np.append(sc_norm_pca_data, preds.reshape([2208556, 1]), axis=1) # append labels to data
現在我面臨兩個問題:
我不知道什么是可視化資料的最佳方法,因為組件的數量是 5。也許我可以使用前 3 臺 PC 進行 3D 繪圖,或者獲取標簽并將它們附加到 pre-PCA 資料集。
我嘗試使用前 2 臺 PC 在二維平面上繪制結果,但顯然使用 matplotlib 繪制超過 200 萬個點是一個壞主意。所以,我再次嘗試了 10k 行的樣本,但 5 分鐘后仍然沒有。
idx = np.random.randint(10, size=10000) result = result[idx,:] plt.scatter(result[:, 0], result[:, 1], c=result[:,result.shape[1]-1]) # 5th column has the labels
我想收到一些關于我做錯了什么以及如何以正確的方式處理這些型別的情況的建議。還有,劇情拖這么久是正常的嗎?我正在使用 Colab 并在 PCA 之前進行了一些預處理(清潔、標準化等)。
uj5u.com熱心網友回復:
k-means 聚類的結果可以使用觀測資料的主要方向來可視化。這些主方向是使用 PCA 演算法計算的。以下是使用 iris 資料集執行此操作的快速示例:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
from sklearn import preprocessing
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
import itertools
iris = load_iris()
# get flower data
X = iris['data']
# get flower families
labels = iris['target']
nclusters = np.unique(labels).size
# scale flower data
scaler = preprocessing.StandardScaler()
scaler.fit(X)
X_scaled = scaler.transform(X)
# instantiate k-means
seed = 0
km = KMeans(n_clusters=nclusters, random_state=seed)
km.fit(X_scaled)
# predict the cluster for each data point
y_cluster_kmeans = km.predict(X_scaled)
# Compute PCA of data set
pca = PCA(n_components=X.shape[1], random_state=seed)
pca.fit(X_scaled)
X_pca_array = pca.transform(X_scaled)
X_pca = pd.DataFrame(X_pca_array, columns=['PC%i' % (ii 1) for ii in range(X_pca_array.shape[1])]) # PC=principal component
# decide which prediction labels to associate with observed labels
# - search each possible way of transforming observed labels
# - identify approach with maximum agreement
MAX = 0
for ii in itertools.permutations([kk for kk in range(np.unique(y_cluster_kmeans).size)]):
change = {jj: ii[jj] for jj in range(len(ii))}
changedPredictions = np.ones(y_cluster_kmeans.size) * -99
for jj in range(len(ii)):
changedPredictions[y_cluster_kmeans == jj] = change[jj]
successful = np.sum(labels == changedPredictions)
if successful > MAX:
MAX = successful
bestChange = change
# transform predictions to match observations
changedPredictions = np.ones(y_cluster_kmeans.size) * -99
for jj in range(len(ii)):
changedPredictions[y_cluster_kmeans == jj] = bestChange[jj]
# plot clusters for observations and predictions
fig, ax = plt.subplots(1, 2, figsize=(7, 3))
ax[0].scatter(X_pca['PC1'], X_pca['PC2'], c=changedPredictions)
ax[1].scatter(X_pca['PC1'], X_pca['PC2'], c=labels)
ax[0].set_title('Prediction')
ax[1].set_title('Truth')
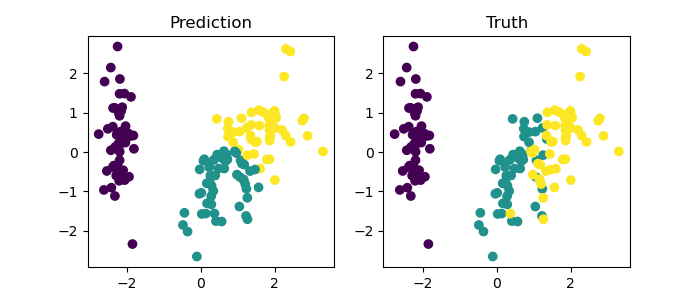
針對問題 (1):
由您來選擇 PCA 組件的數量,并且有許多方法可以在超過 2 個維度上可視化資料。如果我必須用 3 個 PCA 組件繪制資料,我可能會創建前兩個組件的散點圖影片,及時合并第三個組件。
可以通過檢查每個組件捕獲的變化(例如,特征值)來確定適當數量的 PCA 組件,這可以使用 來完成pca.explained_variance_:
eigenvalues = pca.explained_variance_
eigenvalues /= eigenvalues.sum()
plt.plot(eigenvalues, marker='o')
plt.xlabel('PC Dimension')
plt.ylabel('Normalized Eigenvalue')
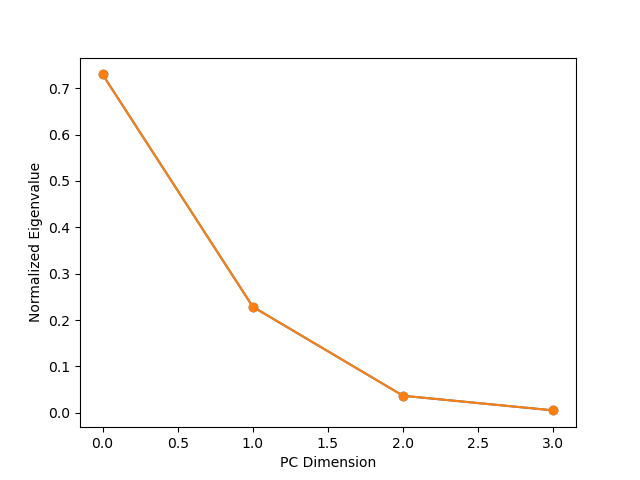
正如我們所看到的,前兩個 PCA 組件捕獲了大約 90% 的方差。
因此,您可以通過顯示它們對總方差的相對貢獻來證明使用三個 PCA 組件的合理性。通常只使用兩個,因為它們經常捕獲資料的大部分變化。
針對問題 (2):
繪制每個點需要一些時間,而這段時間將加起來數百萬個點。在這個執行緒中有一些關于散點圖的討論與大量資料
如果在查看繪圖時難以獲取所有資料,最好找到一種數值/統計方法來評估 k-means 聚類。舉個簡單的例子,在我的 Iris 資料集中,我可以計算失敗預測的數量:
print(r'%.1f percent successful predictions' % (100 * np.sum(labels == changedPredictions) / labels.size))
83.3 percent successful predictions
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/461107.html