我正在尋找從檔案名中洗掉以下輸入行并且我正在使用這個檔案:
cat <<EOF >./tz.txt
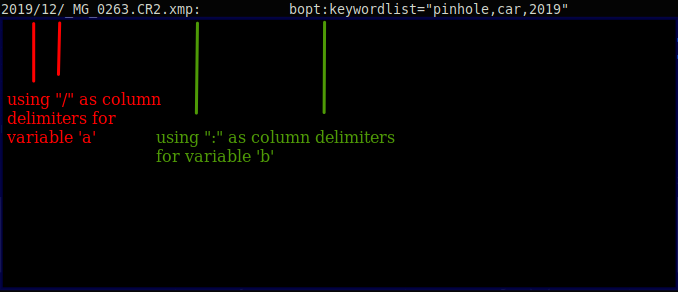
2019/12/_MG_0263.CR2.xmp: bopt:keywordlist="pinhole,car,2019"
2019/12/_MG_0262.CR2.xmp: bopt:keywordlist="pinhole,car,2019"
2020/06/ok/_MG_0003.CR2.xmp: bopt:keywordlist="lowkey,car,Chiaroscuro,2020"
2020/06/ok/_MG_0002.CR2.xmp: bopt:keywordlist="lowkey,car,Chiaroscuro,2020"
2020/04/_MG_0137.CR2.xmp: bopt:keywordlist="red,car,2020"
2020/04/_MG_0136.CR2.xmp: bopt:keywordlist="red,car,2020"
2020/04/_MG_0136.CR2.xmp: bopt:keywordlist="red,car,2020"
EOF
現在我正在使用以下腳本(存盤在檔案 ab.sh 中)從每一行中排除 [filename.xmp: bopt:] (例如 _MG_0263.CR2.xmp: bopt:),以便輸出如下所示:
2019/12/ keywordlist="pinhole,car,2019"
2019/12/ keywordlist="pinhole,car,2019"
2020/06/ok/ keywordlist="lowkey,car,Chiaroscuro,2020"
2020/06/ok/ keywordlist="lowkey,car,Chiaroscuro,2020"
2020/04/ keywordlist="red,car,2020"
2020/04/ keywordlist="red,car,2020"
2020/04/ keywordlist="red,car,2020"
以上是完整的預期輸出。某些檔案夾可能具有不同的結構,例如 2020/06/ok/
腳本代碼如下:
#!/bin/bash
file="./tz.txt"
while read line ; do
# variable a generates the folter structure with a variable range of considered columns
# using awk to figure out how many columns (aka folders) there are in the structure
a=$( cut -d"/" -f 1-$( awk -F'/' '{ print NF-1 }' $line ) $line )
# | |
# -this bit should create a number for-
# -the cut command -
# then b variable stores the last bit in the string
b=$( cut -d":" -f 3 $line )
# and below combine results from above variables
echo ${a} ${b}
done < ${file}
附圖中是用于將字串拆分為列并僅獲取相關資料的邏輯示意圖。
問題是我收到以下錯誤,我不確定我哪里出錯了。感謝您的任何建議或幫助
$ sh ~/ab.sh
awk: fatal: cannot open file `2019/12/_MG_0263.CR2.xmp:' for
reading (No such file or directory)
cut: '2019/12/_MG_0263.CR2.xmp:': No such file or directory
cut: 'bopt:keywordlist="pinhole,car,2019"': No such file or directory
cut: '2019/12/_MG_0263.CR2.xmp:': No such file or directory
cut: 'bopt:keywordlist="pinhole,car,2019"': No such file or directory
awk: fatal: cannot open file `2019/12/_MG_0262.CR2.xmp:' for reading (No such file or directory)
cut: '2019/12/_MG_0262.CR2.xmp:': No such file or directory
cut: 'bopt:keywordlist="pinhole,car,2019"': No such file or directory
cut: '2019/12/_MG_0262.CR2.xmp:': No such file or directory
cut: 'bopt:keywordlist="pinhole,car,2019"': No such file or directory
awk: fatal: cannot open file `2020/06/ok/_MG_0003.CR2.xmp:' for reading (No such file or directory)
cut: '2020/06/ok/_MG_0003.CR2.xmp:': No such file or directory
cut: 'bopt:keywordlist="lowkey,car,Chiaroscuro,2020"': No such file or directory
cut: '2020/06/ok/_MG_0003.CR2.xmp:': No such file or directory
cut: 'bopt:keywordlist="lowkey,car,Chiaroscuro,2020"': No such file or directory
....
uj5u.com熱心網友回復:
替換回圈的一個awk想法:while
awk -F':' '
{ gsub(/[^/] $/,"",$1) # strip everything after last "/" from 1st field
print $1, $3
}' "${file}"
# or as a one-liner sans comments:
awk -F':' '{gsub(/[^/] $/,"",$1); print $1, $3}' "${file}"
這會產生:
2019/12/ keywordlist="pinhole,car,2019"
2019/12/ keywordlist="pinhole,car,2019"
2020/06/ok/ keywordlist="lowkey,car,Chiaroscuro,2020"
2020/06/ok/ keywordlist="lowkey,car,Chiaroscuro,2020"
2020/04/ keywordlist="red,car,2020"
2020/04/ keywordlist="red,car,2020"
2020/04/ keywordlist="red,car,2020"
一種sed選擇:
$ sed -En 's|^(.*)/[^/] :.*:([^:] )$|\1/ \2|p' "${file}"
在哪里:
-En- 啟用對擴展正則運算式的支持,抑制輸入行的自動列印- 因為資料包括
/我們將|用作sed腳本分隔符的字符 ^(.*)/- [第一個捕獲組] 將所有內容匹配到最后一個/...[^/] :- 匹配所有不是/第一個的東西:,然后.......*:- 將所有內容匹配到下一個:([^:] )$- [第二個捕獲組]最后匹配行尾的所有內容:\1/ \2- 列印第一個捕獲組/第二個捕獲組
這會產生:
2019/12/ keywordlist="pinhole,car,2019"
2019/12/ keywordlist="pinhole,car,2019"
2020/06/ok/ keywordlist="lowkey,car,Chiaroscuro,2020"
2020/06/ok/ keywordlist="lowkey,car,Chiaroscuro,2020"
2020/04/ keywordlist="red,car,2020"
2020/04/ keywordlist="red,car,2020"
2020/04/ keywordlist="red,car,2020"
uj5u.com熱心網友回復:
首先,awk命令的最后一個引數應該是檔案名。您正在向它傳遞一個包含輸入檔案一行內容的變數。這就是您收到awk: fatal: cannot open file錯誤的原因。
其次,您在命令中犯了同樣cut的錯誤,導致: No such file or directory錯誤。
兩者awk都cut設計用于處理完整的檔案。您可以將它們鏈接在一起,以便通過使用管道字符:一個的輸出成為另一個的輸入:|。例如:
cat ${file} | awk ... | cut ...
但這很快就會變得復雜和笨拙。更好的解決方案是使用 Stream Editor sed。sed將逐行讀取它的輸入,并且可以在逐行輸出結果之前對每一行執行相當復雜的操作。
這應該做你想要的:
#!/bin/bash
file="/tz.txt"
sed -En 's/^([0-9]{4}\/[0-9]{2}\/).*bopt:(.*)$/\1 \2/p' ${file}
以下是參考運算式的解釋:
s/pat/rep/p 搜索pat,如果找到,替換為rep并列印結果。
在我們的例子中,pat是:
^ 一行的開始
( 開始記住接下來的內容
[0-9]{4} 任何數字恰好重復 4 次
\/ 角色(/轉義)
[0-9]{2}\/任何數字恰好重復 2 次,然后是/
) 停止記憶
.*bopt: 任何 0 個或多個字符后跟bopt:
(.*) 記住 0 個或多個字符...
$ ...直到行尾。
并且rep是:
\1 \2 記住的第一件事,然后是一個空格,然后是我們記得的第二件事。
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/465452.html