我有一個每天包含 27M 樣本的資料集。我可以使用 將其減少count()到每天 1500 個樣本,而不會造成損失。
例如,當我從中繪制直方圖時,我可以用stat="identity"它比原始資料更快地處理計數資料。
是否有類似的方法來處理計數資料以使用ggridges::geom_density_ridges()或類似方法獲得嶺,從而獲得概率密度,而無需處理原始資料集?
uj5u.com熱心網友回復:
聽起來您當前的設定是這樣的(顯然有更多的情況):一個包含大量數字測量向量的資料框,其中至少有一個分組變數來指定不同的山脊線。
出于演示目的,我們將堅持使用 2000 個樣本而不是 2700 萬個樣本:
set.seed(1)
df <- data.frame(x = round(c(rnorm(1000, 35, 5), rnorm(1000, 60, 12))),
group = rep(c('A', 'B', 'C'), len = 2000))
我們可以使用 將這 2000 個觀察值減少到約 200 個,并使用 using 進行count繪圖:geom_histogramstat = 'identity'
df %>%
group_by(x, group) %>%
count() %>%
ggplot(aes(x, y = n, fill = group))
geom_histogram(stat = 'identity', color = 'black')
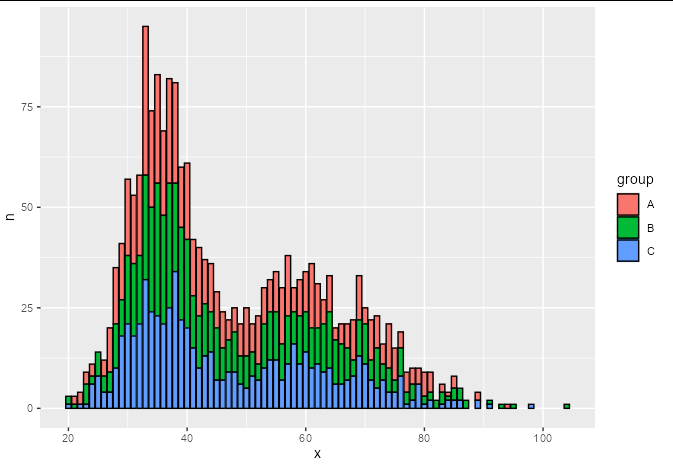
但是我們想從這 200 行計數而不是原始資料中創建密度脊線。當然,我們可以不計算它們并正常創建密度脊線,但這將非常低效。我們可以做的是使用計數作為密度計算的權重。似乎geom_density_ridges不帶weight引數,但stat_density確實如此,您可以告訴它使用density_ridgesgeom. 這允許我們將計數作為權重傳遞給密度計算。
library(ggridges)
df %>%
group_by(x, group) %>%
count() %>%
ggplot(aes(x, fill = group))
stat_density(aes(weight = n, y = group, height = after_stat(density)),
geom = 'density_ridges', position = 'identity')
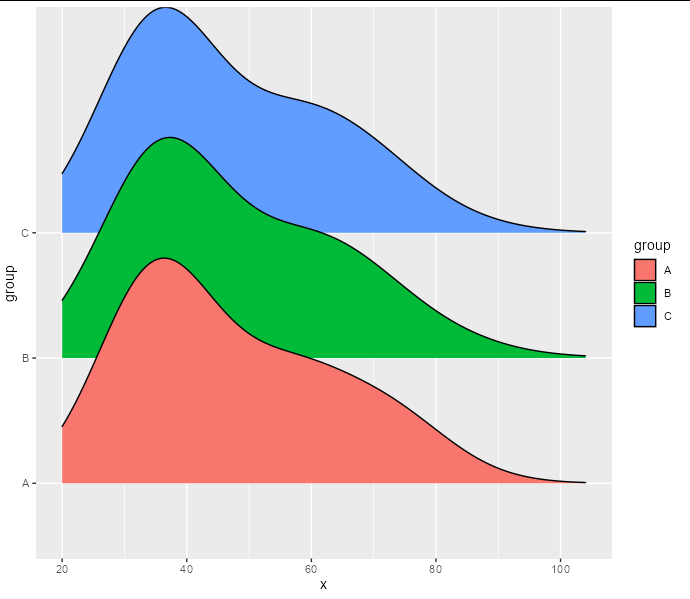
請注意,這應該給我們與在計數之前從整個資料集創建脊線相同的結果,因為我們的“箱”是唯一的間隔值。如果您的真實資料在計數之前對連續資料進行分箱,則在使用計數資料時,您的核密度估計會稍微不準確,具體取決于您的分箱有多“薄”。
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/471619.html
上一篇:繪制多個數值類別的箱線圖
下一篇:在甜甜圈圖中調整文本