我正在嘗試復制我在一篇論文中發現的奇妙情節。該圖基本上有一個中心 y 軸,然后根據變數在左側和右側創建條形圖。接下來是劇情:
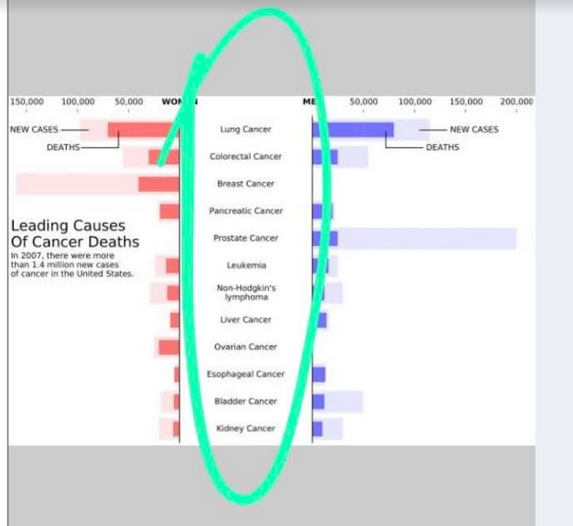
我有一個類似的資料框來復制這個情節。我的資料框df具有下一個結構:
df
# A tibble: 64 x 4
Gender Cases Deaths Group
<chr> <int> <dbl> <chr>
1 F 6163 24 G1
2 M 9067 136 G1
3 F 430 4 G2
4 M 1026 51 G2
5 F 43 0 G3
6 M 67 1 G3
7 F 1382 43 G4
8 M 888 26 G4
9 F 249 4 G5
10 M 191 10 G5
# ... with 54 more rows
我想創建提到的圖,在中心軸上顯示變數Group,在 x 軸(左和右)我想顯示變數Cases并Deaths根據Gender變數,這將是左邊的條形表示M性別,右邊的條形為F性別。
為了達到目標圖,我草繪了一些可能是基礎的代碼,但我不知道如何修改它以改變軸的順序。這是代碼:
library(ggplot2)
library(tidyverse)
#Code for F gender
df %>% pivot_longer(-c(Group,Gender)) %>%
filter(Gender=='F') %>%
mutate(Group=factor(Group,levels = unique(df$Group),ordered = T)) %>%
ggplot(aes(x=Group,y=value,fill=name))
geom_bar(stat = 'identity')
scale_x_discrete(limits = rev(unique(df$Group)))
coord_flip()
theme(legend.position = 'top')
#Code for F gender
df %>% pivot_longer(-c(Group,Gender)) %>%
filter(Gender=='M') %>%
mutate(Group=factor(Group,levels = unique(df$Group),ordered = T)) %>%
ggplot(aes(x=Group,y=value,fill=name))
geom_bar(stat = 'identity')
scale_x_discrete(limits = rev(unique(df$Group)))
coord_flip()
theme(legend.position = 'top')
這會產生下一個情節:
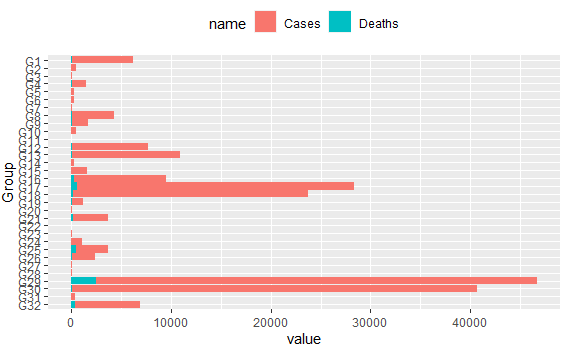
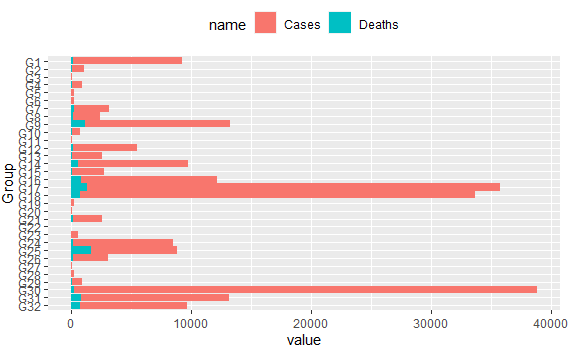
我發現這些圖的一個問題是,盡管我想要顯示條形圖,但它們有兩個問題。首先,我希望其中一個條(例如死亡)可以比另一個條(例如案例)更薄。其次,柱的結構是累積所有值。我希望這兩個度量在每個軸上都從零開始。
我希望這個情節可以在ggplot2. 我的資料df是下一個:
#Data
df <- structure(list(Gender = c("F", "M", "F", "M", "F", "M", "F",
"M", "F", "M", "F", "M", "F", "M", "F", "M", "F", "M", "F", "M",
"F", "M", "F", "M", "F", "M", "F", "M", "F", "M", "F", "M", "F",
"M", "F", "M", "F", "M", "F", "M", "F", "M", "F", "M", "F", "M",
"F", "M", "F", "M", "F", "M", "F", "M", "F", "M", "F", "M", "F",
"M", "F", "M", "F", "M"), Cases = c(6163L, 9067L, 430L, 1026L,
43L, 67L, 1382L, 888L, 249L, 191L, 278L, 248L, 36L, 2925L, 4248L,
2286L, 1576L, 12106L, 441L, 690L, 7L, 53L, 7645L, 5335L, 10862L,
2546L, 229L, 9136L, 1578L, 2657L, 9301L, 11384L, 27773L, 34435L,
23599L, 32952L, 1105L, 170L, 31L, 94L, 3469L, 2408L, 1L, 6L,
86L, 566L, 1108L, 8355L, 3203L, 7174L, 2314L, 2943L, 46L, 54L,
26L, 187L, 44201L, 837L, 40608L, 38616L, 343L, 12284L, 6571L,
8882L), Deaths = c(24, 136, 4, 51, 0, 1, 43, 26, 4, 10, 0, 2,
1, 242, 84, 112, 49, 1164, 7, 33, 0, 4, 26, 115, 63, 24, 7, 556,
14, 86, 228, 784, 596, 1344, 189, 705, 24, 15, 0, 1, 180, 120,
0, 0, 0, 7, 8, 155, 465, 1630, 39, 125, 3, 3, 0, 0, 2511, 87,
114, 219, 8, 847, 340, 760), Group = c("G1", "G1", "G2", "G2",
"G3", "G3", "G4", "G4", "G5", "G5", "G6", "G6", "G7", "G7", "G8",
"G8", "G9", "G9", "G10", "G10", "G11", "G11", "G12", "G12", "G13",
"G13", "G14", "G14", "G15", "G15", "G16", "G16", "G17", "G17",
"G18", "G18", "G19", "G19", "G20", "G20", "G21", "G21", "G22",
"G22", "G23", "G23", "G24", "G24", "G25", "G25", "G26", "G26",
"G27", "G27", "G28", "G28", "G29", "G29", "G30", "G30", "G31",
"G31", "G32", "G32")), row.names = c(NA, -64L), class = c("tbl_df",
"tbl", "data.frame"))
非常感謝!
uj5u.com熱心網友回復:
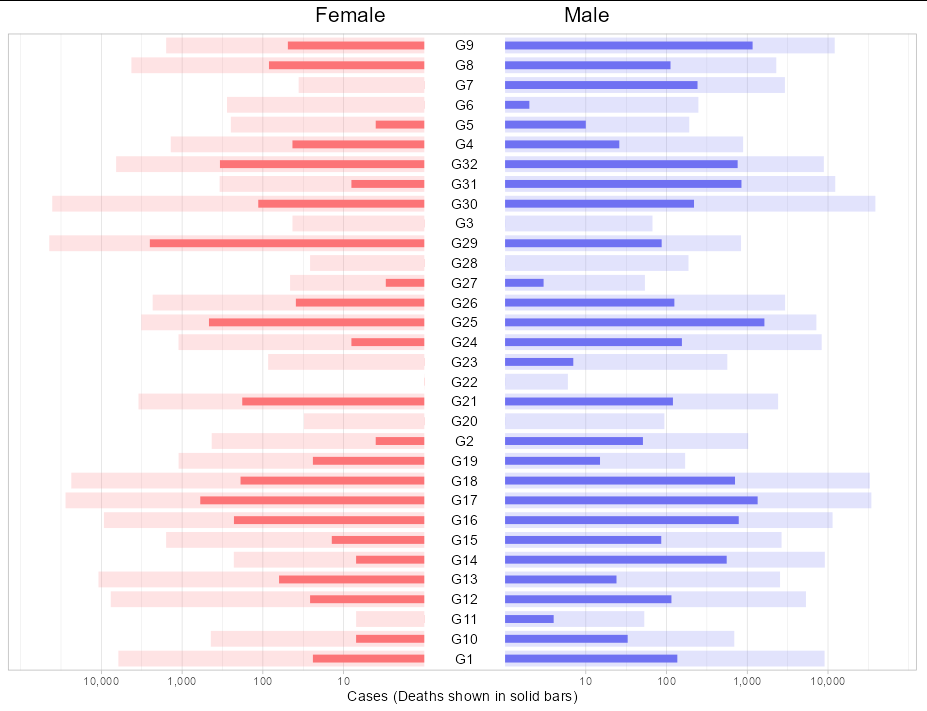
我根本不會轉向這里。如果您將病例和死亡分開,兩個呼叫geom_col將重疊。要獲得具有中心 y 軸的鏡像設定,我只需繪制一個矩形并將標簽作為注釋。這意味著您也需要偽造您的 x 軸,以調整矩形占用的空間。
您需要將其中一種性別的 x 值設為負值。由于我們需要對數轉換,因此在獲取對數后將它們設為負數。
df %>%
mutate(Cases = ifelse(Gender == "F", -log10(Cases) - 0.5, log10(Cases) 0.5),
Deaths = ifelse(Deaths == 0, 1, Deaths),
Deaths = ifelse(Gender == "F", -log10(Deaths) - 0.5,
log10(Deaths) 0.5)) %>%
ggplot(aes(Cases, Group, fill = Gender))
geom_col(width = 0.8, alpha = 0.2)
geom_col(width = 0.4, aes(x = Deaths))
annotate(geom = "rect", xmin = -0.5, xmax = 0.5, ymax = Inf, ymin = -Inf,
fill = "white")
annotate(geom = "text", x = 0, y = levels(factor(df$Group)),
label = levels(factor(df$Group)))
theme_light()
scale_x_continuous(breaks = c(-4.5, -3.5, -2.5, -1.5, 1.5, 2.5, 3.5, 4.5),
labels = c("10,000", "1,000", "100", "10", "10",
"100", "1,000", "10,000"))
scale_fill_manual(values = c("#fc7477", "#6f71f2"))
labs(title = "Female Male",
x = "Cases (Deaths shown in solid bars)")
theme(axis.text.y = element_blank(),
axis.title.y = element_blank(),
axis.ticks.y = element_blank(),
panel.grid.major.y = element_blank(),
plot.title = element_text(size = 16, hjust = 0.5),
legend.position = "none")
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/474414.html