Adata file被匯入到SQL Server表中。資料檔案中的一列是文本資料型別,此列中的值僅為整數。SQL Server db 中目標表中的相應列的型別為varchar(100)。但是在資料匯入之后,SQL Server 會存盤0474525431諸如4.74525431E8.Scientific Notations
問題:在上述情況下,我們如何防止 SQL Server 將值存盤到Scientific Notations。例如,當0474525431插入到VARCHAR(100)列中時,它應該按原樣存盤,而不是按原樣存盤4.74525431E8
更新:
匯入資料的代碼:
from pyspark.sql.functions import *
df = spark.read.csv(".../Test/MyFile.csv", header="true", inferSchema="true")
server_name = "jdbc:sqlserver://{SERVER_ADDR}"
database_name = "database_name"
url = server_name ";" "databaseName=" database_name ";"
table_name = "table_name"
username = "username"
password = "myPassword"
try:
df.write \
.format("com.microsoft.sqlserver.jdbc.spark") \
.mode("overwrite") \
.option("url", url) \
.option("dbtable", table_name) \
.option("user", username) \
.option("password", password) \
.save()
except ValueError as error :
print("Connector write failed", error)
更新2:
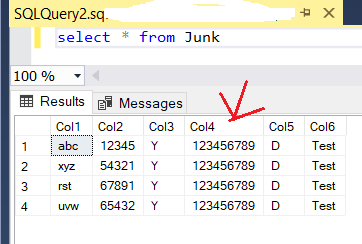
這個問題似乎也與前導零有關。我創建了一個示例檔案(如下所示)并將其資料匯入相應的 SQL 表(也如下所示),并注意到前導零已被洗掉。盡管資料檔案和表格中的所有 6 列都是文本(varchar),但這種情況仍在發生:
資料檔案:
Col1|Col2|Col3|Col4|Col5|Col6
abc|12345|Y|0123456789|D|Test
xyz|54321|Y|0123456789|D|Test
rst|67891|Y|0123456789|D|Test
uvw|65432|Y|0123456789|D|Test
資料匯入后的表格:
uj5u.com熱心網友回復:
Spark 正在推斷模式,并選擇integer包含值“0474525431”的列。因此,在讀取 DataFrame 時,該值將轉換為整數并丟棄前導零。
因此,您需要確保 DataFrame 具有正確的型別。您可以在創建 DataFrame 時顯式指定架構,或者在加載到 SQL Server 之前關閉inferSchema然后將選定的列轉換為不同的型別。兩者的例子都在這個答案中。
這是一個示例,顯示如果 DataFrame 使用string列而不是integer列,則會保留前導“0”。
from pyspark.sql.functions import *
jdbcUrl = "jdbc:sqlserver://{0}:{1};database={2}".format(jdbcHostname, jdbcPort, jdbcDatabase)
connectionProperties = {
"user" : jdbcUsername,
"password" : jdbcPassword,
"driver" : "com.microsoft.sqlserver.jdbc.SQLServerDriver"
}
pushdown_query = "(select '0474525431' f, * from sys.objects) emp"
df = spark.read.jdbc(url=jdbcUrl, table=pushdown_query, properties=connectionProperties)
df.write.mode("overwrite").option("header",True).csv("datalake/temp.csv")
df = spark.read.csv("datalake/temp.csv", header="true", inferSchema="false")
df.printSchema()
table_name = "table_name"
try:
df.write \
.format("com.microsoft.sqlserver.jdbc.spark") \
.mode("overwrite") \
.option("url", jdbcUrl) \
.option("dbtable", table_name) \
.option("user", jdbcUsername) \
.option("password", jdbcPassword) \
.save()
except ValueError as error :
print("Connector write failed", error)
df = spark.read.jdbc(url=jdbcUrl, table=table_name, properties=connectionProperties)
display(df)
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/474815.html
標籤:sql服务器 阿帕奇火花 天蓝色 sql 数据库 sql-server-2019
上一篇:具有副作用的冪等性