這個問題是此處發布的問題的衍生問題: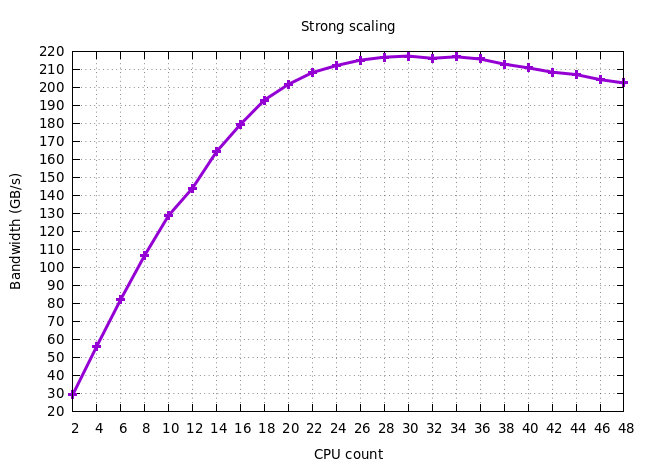
問題:如果你看一下強縮放圖,你可以看到峰值有效帶寬實際上是在 33 個 CPU 時達到的,之后增加 CPU 只會減少它。為什么會這樣?
uj5u.com熱心網友回復:
概述
這個答案提供了可能的解釋。簡而言之,所有并行作業負載都不會無限擴展。當許多內核競爭相同的共享資源(例如 DRAM)時,使用太多內核通常是有害的,因為在某個時候,有足夠的內核來飽和給定的共享資源,而使用更多內核只會增加開銷。
更具體地說,在您的情況下,L3 快取和 IMC 可能是問題所在。啟用Sub-NUMA 集群和非臨時負載應該會稍微提高基準測驗的性能和可擴展性。盡管如此,還有其他架構硬體限制可能導致基準無法很好地擴展。下一節將介紹英特爾 Skylake SP 處理器如何處理記憶體訪問以及如何找到瓶頸。
在引擎蓋下
在您的情況下,英特爾至強 Skylake SP 處理器的布局如下所示:
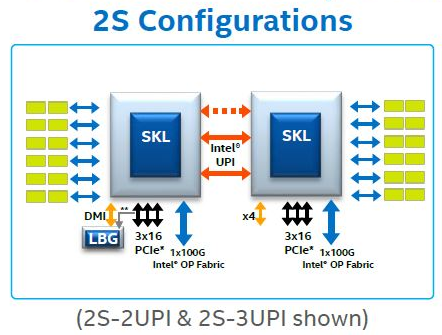

資料來源:
資料來源:英特爾
此外,讓更多內核并行訪問 L3 可能會導致預取快取行的更多早期驅逐,這些快取行需要稍后在內核實際需要它們時再次提取(需要支付額外的 DRAM 延遲時間)。這種影響并不像看起來那么不尋常。事實上,由于 DDR4 DRAM 的高延遲,硬體預取單元必須提前很長時間預取資料,以減少延遲的影響。他們還需要同時執行大量請求。這通常不是順序訪問的問題,但更多的內核會導致從快取和 IMC 的角度來看,訪問看起來更隨機。問題是 DRAM 的設計使得連續訪問比隨機訪問更快(多個連續應連續加載高速快取行以使帶寬完全飽和)。您可以分析LLC-load-misses硬體計數器的值,以檢查是否使用更多執行緒重新獲取了更多資料(我在我的基于 Skylake 且只有 6 核的 PC 上看到了這種效果,但它的強度不足以對最終吞吐量)。為了緩解這個問題,您可以使用非臨時加載來請求處理器將資料直接加載到行填充緩沖區而不是 L3 快取中,從而降低污染(這里是一個相關的答案)。由于并發性較低,使用較少的內核可能會更慢,但使用大量內核時應該會更快一些。請注意,這并不能解決從 IMC 的角度來看,獲取的地址看起來更隨機的問題,并且沒有太多可做的事情。
低級架構 DRAM 和快取在實踐中非常復雜。有關記憶體的更多資訊可以在以下鏈接中找到:
- 每個程式員都應該知道的關于記憶體的知識
- 高性能科學計算簡介(第 1.3 節)
- 講座:主存盤器和 DRAM 系統
- 短講:動態隨機存取存盤器(共 7 部分)
- 英特爾? 64 和 IA-32 架構軟體開發人員手冊(第 3 卷)
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/476515.html
上一篇:Python-傳遞SQLAlchemy模型或id號更好嗎?再次查詢?
下一篇:mysql動態搜索查詢索引