我正在尋找一種方法來顯示元分析的估計值,其中包含大量比較,而不是森林圖。我在圖 1 中看到了本出版物中顯示的一個木材圖:
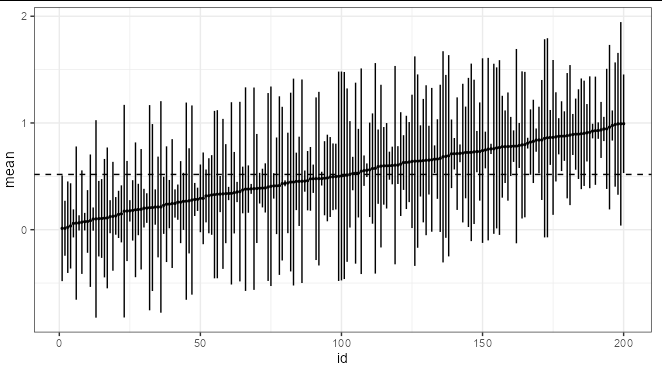
編輯
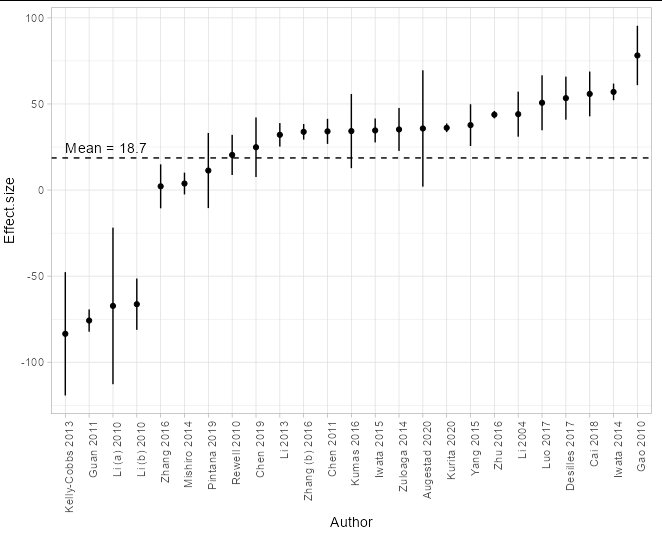
使用示例資料,我們現在可以執行以下操作:
- 使論文成為因子變數,因子的順序是從最低效應到最高效應大小
- 添加
upper和lower代表高于一個標準誤差和低于效應大小一個標準誤差的列。如果您希望這是一個 95% 的置信區間,請執行效果大小 /- 1.96 倍標準誤差。
首先,我們需要確保每篇論文都是唯一標識的。目前,您的樣本資料包含兩篇同名的不同論文(Zhang 2016),因此我們需要更改其中一篇以將其標記為唯一:
df$Author[12] <- "Zhang (b) 2016"
現在讓我們按效果大小排列論文,并為每篇論文添加我們的下限和上限:
df$Author <- factor(df$Author, df$Author[order(df$Effect.size)])
df$lower <- df$Effect.size - df$Standard.error
df$upper <- df$Effect.size df$Standard.error
情節本身就是:
ggplot(df, aes(Author, Effect.size))
geom_point()
geom_linerange(aes(ymin = lower, ymax = upper))
geom_hline(yintercept = mean(df$Effect.size), linetype = 2)
annotate(geom = 'text', x = 1, y = mean(df$Effect.size), vjust = -0.5,
label = paste('Mean =', round(mean(df$Effect.size), 1)), hjust = 0)
theme_light()
theme(axis.text.x = element_text(angle = 90, hjust = 1))
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/478912.html