我有一個與時間相關的資料集,我(例如)正在嘗試對 Lasso 回歸進行一些超引數調整。
為此,我使用 sklearn'sTimeSeriesSplit而不是常規的 Kfold CV,即這樣的:
tscv = TimeSeriesSplit(n_splits=5)
model = GridSearchCV(
estimator=pipeline,
param_distributions= {"estimator__alpha": np.linspace(0.05, 1, 50)},
scoring="neg_mean_absolute_percentage_error",
n_jobs=-1,
cv=tscv,
return_train_score=True,
max_iters=10,
early_stopping=True,
)
model.fit(X_train, y_train)
有了這個,我得到了一個模型,然后我可以將它用于預測等。交叉驗證背后的想法是基于這個:
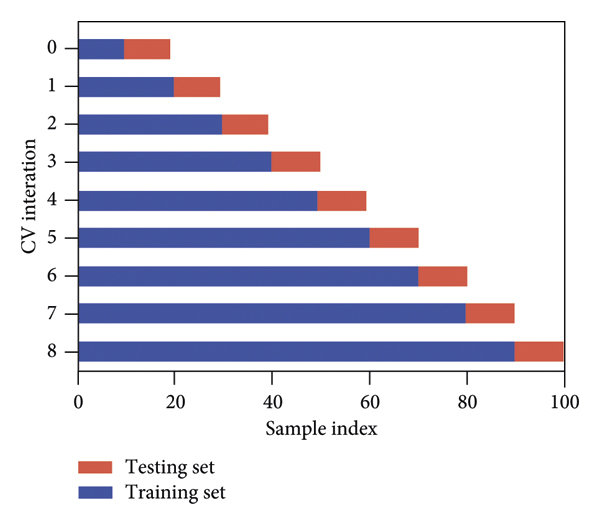
但是,我的問題是我實際上希望從所有 cv 的所有測驗集中獲得預測。我不知道如何從模型中得到它?
如果我嘗試,cv_results_我會得到每個分割和每個超引數的分數(來自評分引數)。但我似乎無法找到每個測驗拆分中每個值的預測值。我實際上需要它來進行一些回測。我認為使用最終模型來預測先前的值是不“公平的”。我想在這種情況下會有某種過度擬合。
所以,是的,有什么方法可以讓我提取每個拆分的預測值嗎?
uj5u.com熱心網友回復:
您可以在GridSearchCV.With 中使用自定義評分函式,您可以使用GridSearchCV在該特定折疊中給出的估計器來預測輸出。
從檔案評分引數是
評估測驗集上交叉驗證模型性能的策略。
from sklearn.metrics import mean_absolute_percentage_error
def custom_scorer(clf, X, y):
y_pred = clf.predict(X)
# save y_pred somewhere
return -mean_absolute_percentage_error(y, y_pred)
model = GridSearchCV(estimator=pipeline,
scoring=custom_scorer)
上述代碼中的輸入X和y來自測驗集。clf是estimator引數的給定管道。
顯然,您的估算器應該實作 predict 方法(應該是 中的有效模型scikit-learn)。您可以將其他評分添加到自定義評分中,以避免自定義功能產生無意義的評分。
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/479921.html
標籤:Python 机器学习 scikit-学习 交叉验证 网格搜索
上一篇:卷積網路上的二維矩陣