我有一個關于集群的問題。當您使用 k-最近鄰演算法時,您必須說您期望有多少個集群。我現在的問題是,我有一些運行,其中集群的數量會有所不同。我查了一下,有一些方法可以限制你擁有多少個集群,但這些演算法適用于二維問題。就我而言,我具有三個功能。您知道我可以使用哪些演算法來解決三維問題嗎?如果有人可以幫助我,我會很高興,因為我自己也做了一些研究,但我找不到任何東西。:)
例如,它應該定位兩個集群,一個單點和資料行作為第二個集群:
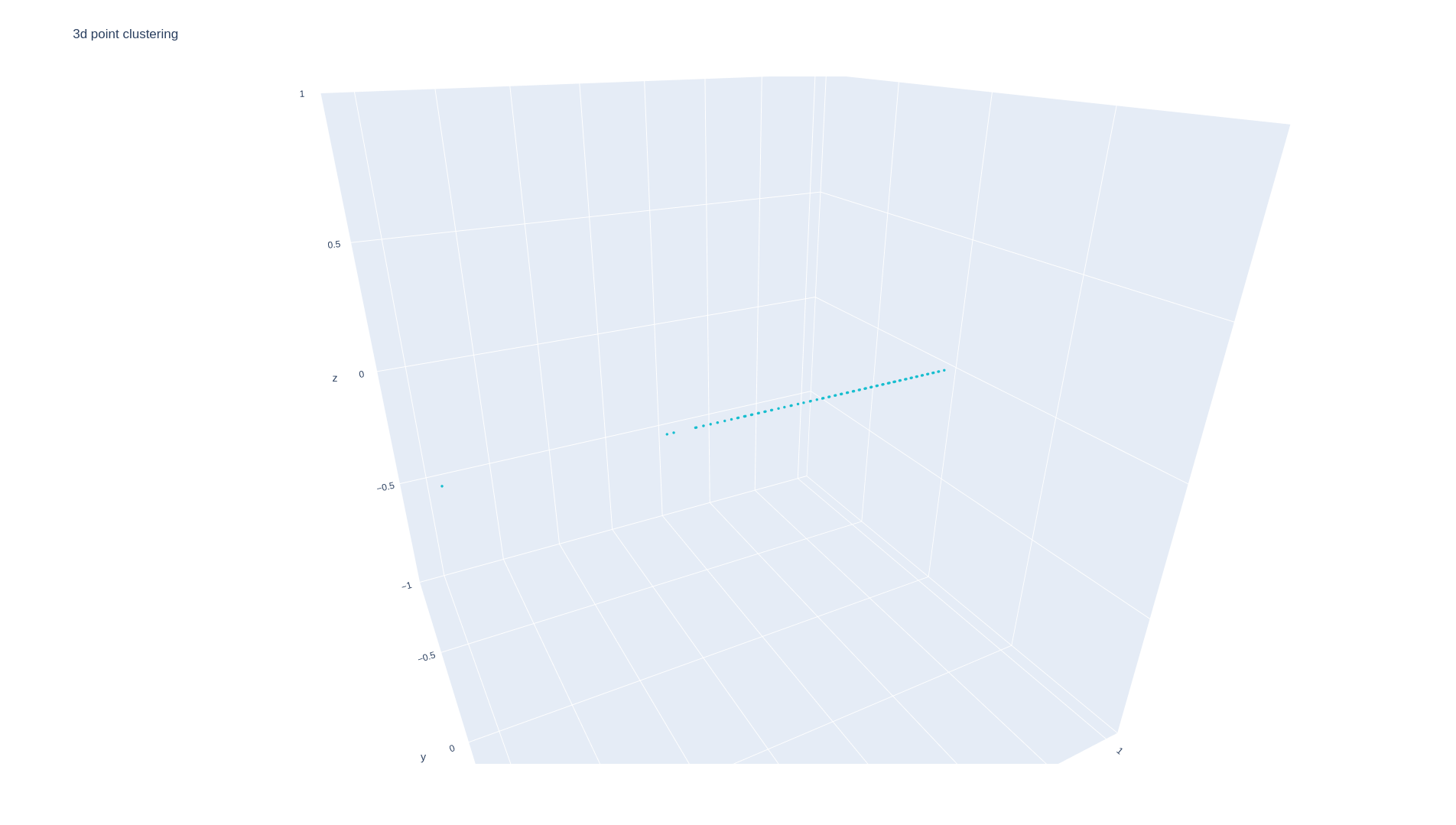
這里以第二個例子為例,在這里我期望演算法可以自動找到三個集群,長線,短線和單點:

謝謝。:)
uj5u.com熱心網友回復:
正如@ForceBru 在評論中所說,您也可以將 k-means 演算法用于 3D 資料。當我必須處理要聚類的 3D 點時,我總是使用sklearn.cluster.KMeans 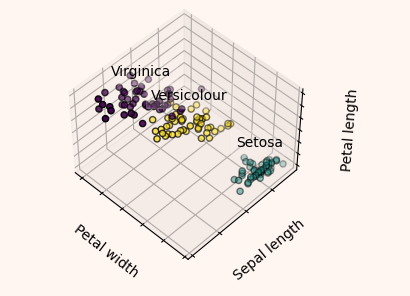
上面鏈接中提供的示例的關鍵部分如下:
from sklearn.cluster import KMeans
from sklearn import datasets
np.random.seed(5)
iris = datasets.load_iris()
X = iris.data
y = iris.target
estimators = [
("k_means_iris_8", KMeans(n_clusters=8)),
("k_means_iris_3", KMeans(n_clusters=3)),
("k_means_iris_bad_init", KMeans(n_clusters=3, n_init=1, init="random")),
]
您也可以嘗試使用 DBSCAN 演算法(但我不是它的專家)。看看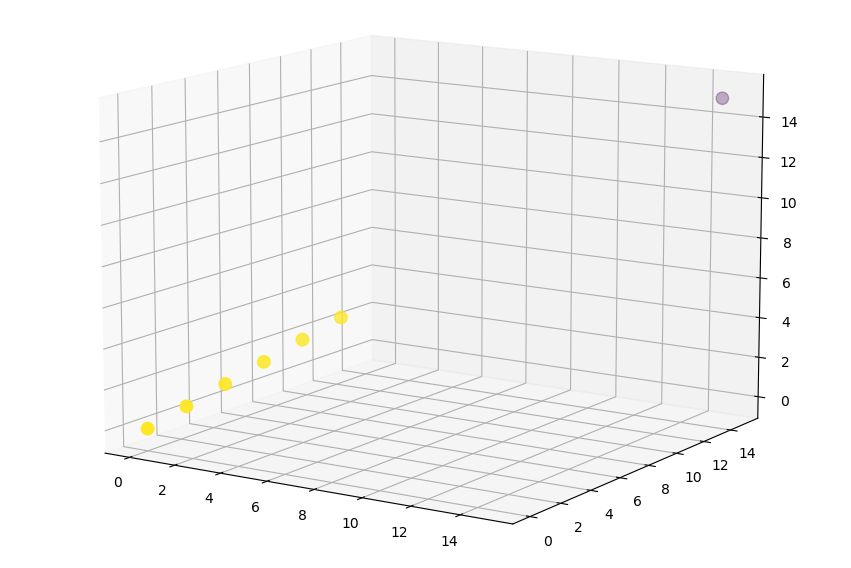
嘗試研究檔案中的 DBSCAN 引數,然后調整它們以滿足您的目標。
最后,這里有很多其他的聚類演算法,看看吧!
希望能幫助到你!
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/479923.html