我是使用 R 映射資料的新手,我想要一些關于復雜表示的幫助。我會盡量說清楚:)
我有一個資料集,可以計算自 1950 年以來瑞典每天的觀察結果。每條線都是一個觀測值,帶有緯度、經度、儒略日、日期和年份資訊。我將瑞典分為三組緯度(1 為南,2 為中,3 為北)。我只關心緯度資訊,以便在需要時可以將每個點的經度轉換為相同的值。
我想根據這三組中的觀察密度來繪制隨時間的變化。為此,我想代表我資料集不同關鍵年份的變化:1950/1975/2000/2021,因此我需要創建多個地圖。另外,我希望每年都有一張 2 月前 15 天/3 月最后 15 天/4 月前 15 天和 5 月最后 15 天的累積觀測密度圖;這樣地圖的總數將是 4*4 = 16。理想情況下,變化將通過顏色漸變來表示(越暗,觀察越多)。但如果不合適,我不介意其他建議。
我的大資料集的隨機樣本:
> dput(df[sample(nrow(df), 50),])
structure(list(lat = c("65", "64", "65", "59", "59", "57", "57",
"68", "67", "63", "60", "61", "65", "59", "56", "65", "59", "57",
"55", "59", "56", "56", "59", "60", "59", "55", "59", "59", "57",
"55", "56", "57", "65", "59", "63", "59", "56", "59", "56", "56",
"57", "63", "58", "59", "63", "61", "55", "58", "66", "57"),
long = c("21", "17", "21", "14", "14", "13", "12", "18",
"18", "20", "16", "14", "17", "16", "12", "16", "15", "14",
"12", "17", "12", "16", "18", "14", "14", "14", "18", "17",
"12", "13", "12", "12", "21", "13", "19", "16", "12", "18",
"16", "12", "12", "18", "12", "17", "20", "17", "12", "13",
"19", "12"), date = c("2009-03-29", "2006-04-06", "2019-03-31",
"2006-04-04", "1975-04-13", "2014-02-05", "1996-04-02", "2021-04-08",
"1995-04-12", "2004-04-12", "2018-04-07", "2021-03-28", "1988-04-01",
"2002-03-17", "2015-03-12", "2019-04-05", "2016-03-19", "2021-04-03",
"2014-02-08", "2015-03-13", "2021-03-09", "2005-02-07", "2013-03-31",
"1989-03-23", "1989-03-27", "2015-01-21", "2011-04-04", "2018-03-26",
"1987-03-23", "2011-01-31", "2014-02-09", "2004-01-17", "2012-04-20",
"2017-03-07", "2005-04-02", "2017-01-28", "2016-03-19", "1984-03-30",
"2005-01-29", "2021-03-06", "2008-02-03", "2017-03-22", "2019-03-10",
"2010-01-17", "2009-04-10", "2016-01-23", "2019-03-01", "2006-03-04",
"2014-04-23", "2009-03-15"), julian_day = c("88", "96", "90",
"94", "103", "36", "93", "98", "102", "103", "97", "87",
"92", "76", "71", "95", "79", "93", "39", "72", "68", "38",
"90", "82", "86", "21", "94", "85", "82", "31", "40", "17",
"111", "66", "92", "28", "79", "90", "29", "65", "34", "81",
"69", "17", "100", "23", "60", "63", "113", "74"), year = c(2009L,
2006L, 2019L, 2006L, 1975L, 2014L, 1996L, 2021L, 1995L, 2004L,
2018L, 2021L, 1988L, 2002L, 2015L, 2019L, 2016L, 2021L, 2014L,
2015L, 2021L, 2005L, 2013L, 1989L, 1989L, 2015L, 2011L, 2018L,
1987L, 2011L, 2014L, 2004L, 2012L, 2017L, 2005L, 2017L, 2016L,
1984L, 2005L, 2021L, 2008L, 2017L, 2019L, 2010L, 2009L, 2016L,
2019L, 2006L, 2014L, 2009L), lat_grouped = c("3", "2", "3",
"1", "1", "1", "1", "3", "3", "2", "2", "2", "3", "1", "1",
"3", "1", "1", "1", "1", "1", "1", "1", "2", "1", "1", "1",
"1", "1", "1", "1", "1", "3", "1", "2", "1", "1", "1", "1",
"1", "1", "2", "1", "1", "2", "2", "1", "1", "3", "1")), row.names = c(22330L,
15394L, 44863L, 15258L, 1481L, 31695L, 6399L, 52043L, 6111L,
11508L, 42184L, 51391L, 4308L, 8764L, 34675L, 45080L, 37042L,
51743L, 31717L, 34723L, 50514L, 11892L, 30527L, 4572L, 4608L,
33744L, 26476L, 41366L, 4006L, 25265L, 31741L, 10122L, 29059L,
38340L, 12787L, 37827L, 37061L, 3029L, 11762L, 50464L, 18114L,
39026L, 43835L, 23081L, 22811L, 36179L, 43641L, 13743L, 33608L,
21917L), class = "data.frame")
我已經設法按照互聯網上的一些指導方針創建了基礎層,但我不知道如何繼續下去,而且我對所有我沒有設法使作業的不同方法感到困惑。
library(ggplot2)
library(gganimate)
library(gifski)
library(maps)
library(sf)
library(rgdal)
#map source: https://www.geoboundaries.org/data/1_3_3/zip/shapefile/
wd = "C:/Users/HP/Desktop/SWE_ADM0"
sweden <- readOGR(paste0(wd, "/SWE_ADM0.shp"), layer = "SWE_ADM0")
plot(sweden)
#To use the imported shapefile in ggmap, we need the fortify() function of the ggplot2 package.
sweden_fort <- ggplot2::fortify(sweden)
base_map <- ggplot(data = sweden_fort, mapping = aes(x=long, y=lat, group=group))
geom_polygon(color = "black", fill = "white")
coord_quickmap()
theme_void()
base_map
我希望有人能幫幫我,如果有什么不清楚或缺少資訊,我可以編輯我的帖子:)
非常感謝。
uj5u.com熱心網友回復:
如果我是你,我會使用sf物件,即在sweden地圖中讀取st_read()而不是readOGR()直接使用然后使用fortify(). 這將讓您使用geom_sf()而不是geom_polygon(). 此外,您應該簡化sweden您正在使用的 shapefile。你指的那個很詳細,也就是很多行。如果您嘗試在影片中使用它,渲染將花費數小時和數小時。您可以大大簡化它,而不會丟失情節的相關細節。也將其創建df為一個sf物件——一個由長/緯度點而不是線組成的物件——然后你就可以開始了。
所以,使用你的df上面和你指向的瑞典地圖,
library(tidyverse)
library(sf)
library(here)
#map source: https://www.geoboundaries.org/data/1_3_3/zip/shapefile/
## Simplify the map for quicker rendering
sweden <- st_read(here("data", "SWE_ADM0", "SWE_ADM0.shp"),
layer = "SWE_ADM0") |>
st_simplify(dTolerance = 1e3)
#> Reading layer `SWE_ADM0' from data source `scratch/data/SWE_ADM0/SWE_ADM0.shp' using driver `ESRI Shapefile'
#> Simple feature collection with 1 feature and 8 fields
#> Geometry type: MULTIPOLYGON
#> Dimension: XY
#> Bounding box: xmin: 10.98139 ymin: 55.33695 xmax: 24.16663 ymax: 69.05997
#> Geodetic CRS: WGS 84
df <- structure(list(lat = c("65", "64", "65", "59", "59", "57", "57",
"68", "67", "63", "60", "61", "65", "59", "56", "65", "59", "57",
"55", "59", "56", "56", "59", "60", "59", "55", "59", "59", "57",
"55", "56", "57", "65", "59", "63", "59", "56", "59", "56", "56",
"57", "63", "58", "59", "63", "61", "55", "58", "66", "57"),
long = c("21", "17", "21", "14", "14", "13", "12", "18",
"18", "20", "16", "14", "17", "16", "12", "16", "15", "14",
"12", "17", "12", "16", "18", "14", "14", "14", "18", "17",
"12", "13", "12", "12", "21", "13", "19", "16", "12", "18",
"16", "12", "12", "18", "12", "17", "20", "17", "12", "13",
"19", "12"), date = c("2009-03-29", "2006-04-06", "2019-03-31",
"2006-04-04", "1975-04-13", "2014-02-05", "1996-04-02", "2021-04-08",
"1995-04-12", "2004-04-12", "2018-04-07", "2021-03-28", "1988-04-01",
"2002-03-17", "2015-03-12", "2019-04-05", "2016-03-19", "2021-04-03",
"2014-02-08", "2015-03-13", "2021-03-09", "2005-02-07", "2013-03-31",
"1989-03-23", "1989-03-27", "2015-01-21", "2011-04-04", "2018-03-26",
"1987-03-23", "2011-01-31", "2014-02-09", "2004-01-17", "2012-04-20",
"2017-03-07", "2005-04-02", "2017-01-28", "2016-03-19", "1984-03-30",
"2005-01-29", "2021-03-06", "2008-02-03", "2017-03-22", "2019-03-10",
"2010-01-17", "2009-04-10", "2016-01-23", "2019-03-01", "2006-03-04",
"2014-04-23", "2009-03-15"), julian_day = c("88", "96", "90",
"94", "103", "36", "93", "98", "102", "103", "97", "87",
"92", "76", "71", "95", "79", "93", "39", "72", "68", "38",
"90", "82", "86", "21", "94", "85", "82", "31", "40", "17",
"111", "66", "92", "28", "79", "90", "29", "65", "34", "81",
"69", "17", "100", "23", "60", "63", "113", "74"), year = c(2009L,
2006L, 2019L, 2006L, 1975L, 2014L, 1996L, 2021L, 1995L, 2004L,
2018L, 2021L, 1988L, 2002L, 2015L, 2019L, 2016L, 2021L, 2014L,
2015L, 2021L, 2005L, 2013L, 1989L, 1989L, 2015L, 2011L, 2018L,
1987L, 2011L, 2014L, 2004L, 2012L, 2017L, 2005L, 2017L, 2016L,
1984L, 2005L, 2021L, 2008L, 2017L, 2019L, 2010L, 2009L, 2016L,
2019L, 2006L, 2014L, 2009L), lat_grouped = c("3", "2", "3",
"1", "1", "1", "1", "3", "3", "2", "2", "2", "3", "1", "1",
"3", "1", "1", "1", "1", "1", "1", "1", "2", "1", "1", "1",
"1", "1", "1", "1", "1", "3", "1", "2", "1", "1", "1", "1",
"1", "1", "2", "1", "1", "2", "2", "1", "1", "3", "1")), row.names = c(22330L,
15394L, 44863L, 15258L, 1481L, 31695L, 6399L, 52043L, 6111L,
11508L, 42184L, 51391L, 4308L, 8764L, 34675L, 45080L, 37042L,
51743L, 31717L, 34723L, 50514L, 11892L, 30527L, 4572L, 4608L,
33744L, 26476L, 41366L, 4006L, 25265L, 31741L, 10122L, 29059L,
38340L, 12787L, 37827L, 37061L, 3029L, 11762L, 50464L, 18114L,
39026L, 43835L, 23081L, 22811L, 36179L, 43641L, 13743L, 33608L,
21917L), class = "data.frame")
## Convert the given sample data to an `sf` object of points, setting
## the coordinate system to be the same as the `sweden` map
df <- df |>
mutate(id = 1:nrow(df),
date = lubridate::ymd(date),
year = factor(lubridate::year(date))) |>
st_as_sf(coords = c("long", "lat"), crs = 4326)
# Subset the data to the years to you want, and create the plot
df_selected <- df |>
filter(year %in% c(1975, 1989, 2016, 2021))
ggplot()
geom_sf(data = sweden)
geom_sf(data = df_selected,
mapping = aes(color = lat_grouped))
facet_grid(lat_grouped ~ year)
guides(color = "none")
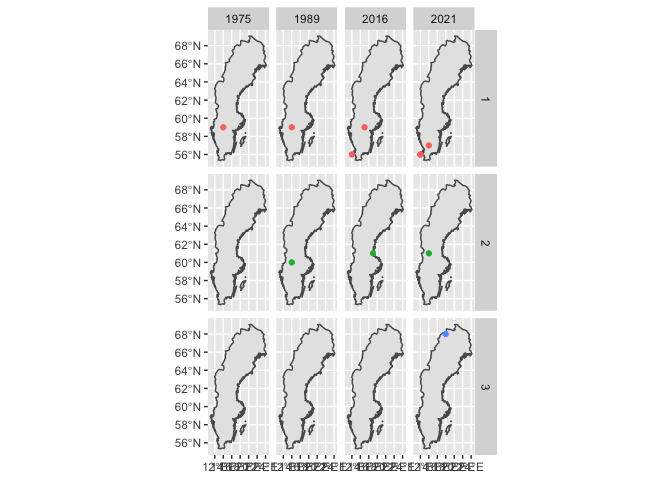
您可以設定例如theme_void()或地圖主題以擺脫網格線等。
更新:最后一次編輯,只是關于繪制密度的問題。計算累積資料后,您可以例如使用 2D 內核密度估計覆寫您的地圖。例如,這是一個非常粗略的第一次切割,按緯度組刻面。
ggplot()
geom_sf(data = sweden)
geom_density_2d_filled(data = df,
mapping = aes(x = map_dbl(geometry, ~.[1]),
y = map_dbl(geometry, ~.[2])),
alpha = 0.4)
facet_wrap(~ lat_grouped)
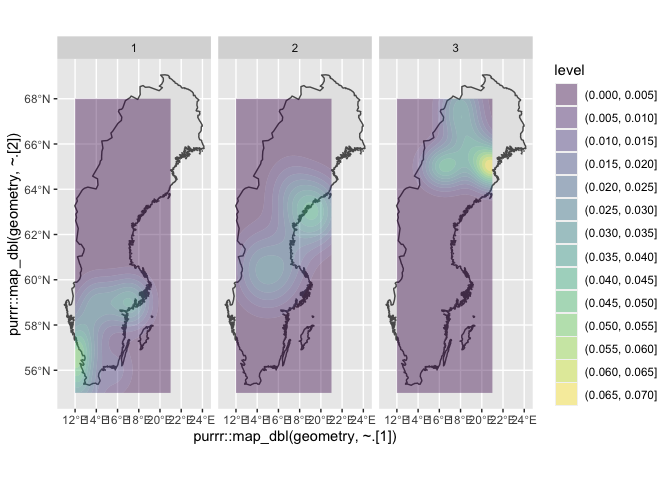
這里的map_dbl()函式(來自purrr包)是一種進入幾何列df并首先提取x(即經度)然后提取y(即緯度)資料的方法,以便給出geom_density_2d()計算其估計所需的坐標。
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/482737.html
上一篇:重新排列堆疊的條形圖圖例標簽而不更改R中的圖(并修復刻度線)
下一篇:Ggplot2:在一個圖中使用scale_fill_manual()為geom_rect()和geom_line()創建圖例?