我正在尋找使用 groupby 函式的總列的總部分。當我使用 groupby 函式“代碼”時,它可以作業,但是我希望能夠通過將其放在變數中并列印它來將其過濾為一個標稱代碼。
subheading_one = df.groupby(['Code'])['Total'].sum()
subheading_two = df.groupby(['Code'])['Total'].sum()
subheading_three = df.groupby(['Code'])['Total'].sum()
print('Cost heading 1.1 £: ',subheading_one)
print('Cost heading 1.2 £: 'subheading_two)
print('Cost heading 1.3 £: 'subheading_three)
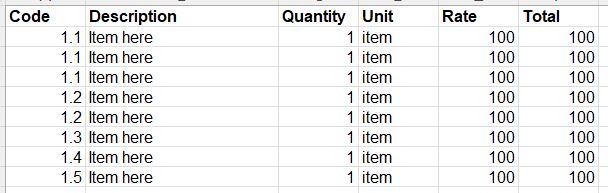
我附上了資料框的片段。正如您所看到的,我希望能夠僅總計“1.1”項并將該總計放入變數中(應等于 300)。有人可以幫忙嗎?
uj5u.com熱心網友回復:
您應該能夠執行.groupby一次操作,然后使用.loc選擇您想要的特定總數:
totals = df.groupby(['Code'])['Total'].sum()
print('Cost heading 1.1 £: ', totals.loc['1.1'])
print('Cost heading 1.2 £: ', totals.loc['1.2'])
編輯:如果您的代碼列是浮點數(不是字串),您可以執行以下操作:
totals = df.groupby(['Code'])['Total'].sum()
print('Cost heading 1.1 £: ', totals.loc[1.1])
print('Cost heading 1.2 £: ', totals.loc[1.2])
uj5u.com熱心網友回復:
你可以使用get_group這樣的
subheading_one = df.groupby(['Code'])['Total'].get_group('1.1').sum()
我假設您的代碼功能具有字串值。
uj5u.com熱心網友回復:
code = {'Code': [1.1, 1.1, 1.1, 1.2, 1.2, 1.3, 1.4, 1.5]}
df = pd.DataFrame(code)
df['Description'] = 'Item here'
df['Quantity'] = 1
df['Unit'] = 'Item'
df['Rate'] = 100
df['Total'] = 100
mask = df['Code'] == 1.1
subheading_one = df.loc[mask, 'Total'].sum()
mask = df['Code'] == 1.2
subheading_two = df.loc[mask, 'Total'].sum()
mask = df['Code'] == 1.3
subheading_three = df.loc[mask, 'Total'].sum()
print(f'Cost heading 1.1 £: {subheading_one}')
print(f'Cost heading 1.2 £: {subheading_two}')
print(f'Cost heading 1.3 £: {subheading_three}')
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/488310.html
上一篇:來自熊貓變數的增量列