文本識別技術(OCR)可以識別收據、名片、檔案照片等含文字的圖片,將其中的文本資訊提取出來,代替了人工資訊錄入與檢測等操作,降低了輸入成本,快速、方便,提升產品的易用性,
隨著技術的發展,OCR已經深入生活的諸多方面,交通場景下,主要用于車牌識別,便于停車場管理、智能交通、移動警務等;生活場景下,主要用于證照識別,便于提取身份證、銀行卡、護照、結婚證、戶口本、營業執照等證照影像的文字資訊,還可對街景路牌進行識別;票據場景下,主要用于發票憑證識別,便于銀行、稅務等大量票據表格錄入及長期存盤;其他場景下,可以利用OCR對書籍、報告、簡歷、合同等檔案進行識別,將紙質檔案電子化,便于保存和查看,
Demo

HMS Core機器學習服務OCR能力在2020年01月15日首次上線,為開發者們提供了豐富的API介面,HMS Core OCR能力支持任意角度的文本識別,對橫豎排、彎曲文本精準識別的同時,還能對文本段落進行準確劃分,對文本內容精確定位,為了保證一些卡證、票據的隱私性,HMS Core OCR能力還支持端側和云側推理,端側適合相機或視頻畫面實時處理,圖片中稀疏文本識別,當呼叫端側介面時,可識別中文(簡體)、日文、韓文、拉丁語(包括英文、西班牙文、葡萄牙文、意大利文、德文、法文、俄文)10個語種;云側對文字識別精度要求高,適合圖片中稀疏文本識別、檔案圖片密集文本識別,當呼叫云側介面時,可以識別中文(簡體)、英文、西班牙文、葡萄牙文、意大利文、德文、法文、俄文、日文、韓文、波蘭文、芬蘭文、挪威文、瑞典文、丹麥文、土耳其文、泰文、阿拉伯文、印地文19個語種,核心語種的識別精度達到行業頂尖水平,
基于用戶需求和技術進步,HMS Core 機器學習服務OCR能力進行了升級優化:端側模型輕量化、準確率提升,
能力演進:
1、端側模型輕量化:文本識別端側10個語種能力增強(模型層面)
KPI不變,端側模型輕量化壓縮42%,運行所占記憶體從之前版本的19.4M降到11.1M左右,
模型的輕量化將模型體積縮小,并且可以輕量化展示,記憶體占比小,運行更加流暢,
2、準確率提升:云側OCR能力演進(中文模型)
云側OCR中文識別準確率從87.62%提升到92.95%,高于行業平均水準,競爭力大幅提高,
技術描述:
OCR是通過檢測紙上的字符,以檢測暗、亮的方式確定其形狀,而后用字符識別法將形狀翻譯成計算機文字的程序,即針對印刷體字符,采用光學的方式將紙質檔案中的文字轉換成為黑白點陣的影像檔案,并經過識別軟體將影像中的文字轉換成文本格式,供文字處理軟體進一步編輯加工的技術,
由于通用領域中存在大量彎曲文本的情況,演算法團隊通過重新設計文本檢測模型,在橫向文本的基礎上,增加了任意旋轉角度、彎曲文本的支持,使得在出行、廣告牌等場景下的準確率和易用性大大增加,
文本識別還支持純端側推理,在涉及各類卡證、票據等隱私資訊的場景下,相比云側服務更加安全、可靠,考慮到端側設備的算力、功耗等因素,演算法團隊通過巧妙的模型框架設計、量化、剪枝等技術,在保證識別精度的情況下,將識別模型壓縮到商用的標準,保證用戶的使用體驗,
競品對比:
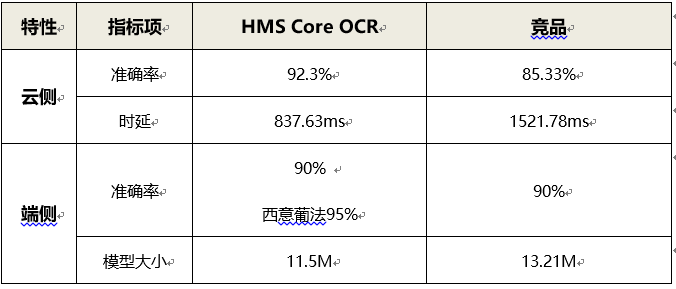
OCR能力演進后,端側和云側的識別準確率都在業界屬于領先地位,
云側平均準確率高于競品約7%,時延僅為競品的55%,
端側平均準確率和模型體積均優于競品,一些小語種的準確率甚至達到95%,
優化更新:
-
基于現在市面上OCR能力大多只針對印刷體字符, HMS Core機器學習服務正在進行通用手寫體識別能力的開發(手寫體識別、手寫體+印刷體混合識別),
-
加入更多語種,預計新增羅馬尼亞語、馬來語、菲律賓語等,
-
預計新增版面分析功能(PDF重排),機器學習服務支持多種內容識別處理功能,提升自身AI能力競爭力,
為了滿足眾多場景需要,HMS Core會不斷開發新功能幫助開發者構建多元化應用,后續新增功能以華為HMS Core機器學習服務聯盟官網為準,
了解更多詳情>>
訪問華為開發者聯盟官網
獲取開發指導檔案
華為移動服務開源倉庫地址:GitHub、Gitee
關注我們,第一時間了解 HMS Core 最新技術資訊~
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/520742.html
標籤:其他