本作業所有資料均來自吳恩達在Coursera課程平臺,深度學習專項課程第五門Sequence Models課程中第二周的課后作業Emogify,
課程鏈接為:https://www.coursera.org/learn/nlp-sequence-models
本節作業所需資料以及代碼可從該作業檔案目錄下下載,鏈接為:
https://www.coursera.org/learn/nlp-sequence-models/notebook/acNYU/emojify
如何從Coursera下載打包課程教程鏈接:
下載Coursera-notebooks全部作業檔案coursera notebooks下載
注:本篇部分內容引于
【中文】【吳恩達課后編程作業】Course 5 - 序列模型 - 第二周作業 - 詞向量的運算與Emoji生成器
目錄
- 1. 作業簡介
- 2. 基準模型:Emogifier-V1 Pycharm復現
- 2.1- 資料集
- 2.2 - Emojifier-V1的結構
- 2.3 - 實作Emojifier-V1模型
- 2.4 - 訓練模型
- 2.5 - 驗證測驗集
- 2.6 - Emojifier-V1模型測驗
- 3. Emojifier-V2:在Keras中使用LSTM模塊
- 3.1 - Emojifier-V2模型的結構
- 3.2 - Keras與mini-batching
- 3.3 - 嵌入層( The Embedding layer)
- 3.4 - 構建Emojifier-V2模型
- 3.5 - 編譯訓練模型
- 3.6 - 驗證測驗集
- 3.7 - Emojifier-V2模型測驗
- 結語
1. 作業簡介
本次作業將實作通過詞向量來構建一個表情生成器,
你有沒有想過讓你的文字也有更豐富表達能力呢?比如寫下“Congratulations on the promotion! Lets get coffee and talk. Love you!”,那么你的表情生成器就會自動生成“Congratulations on the promotion! ? Lets get coffee and talk. ?? Love you! ??”,
??另一方面,如果你對這些表情不感冒,而你的朋友給你發了一大堆的帶表情的文字,那么你也可以使用表情生成器來懟回去,
??我們要構建一個模型,輸入的是文字(比如“Let’s go see the baseball game tonight!”),輸出的是表情(??),在眾多的Emoji表情中,比如“??”代表的是“心”而不是“愛”,但是如果你使用詞向量,那么你會發現即使你的訓練集只明確地將幾個單詞與特定的表情符號相關聯,你的模型也了能夠將測驗集中的單詞歸納、總結到同一個表情符號,甚至有些單詞沒有出現在你的訓練集中也可以,
??本次作業中,包含使用詞向量的基準模型(Emojifier-V1),以及一個更復雜的包含了LSTM的模型(Emojifier-V2),
2. 基準模型:Emogifier-V1 Pycharm復現
2.1- 資料集
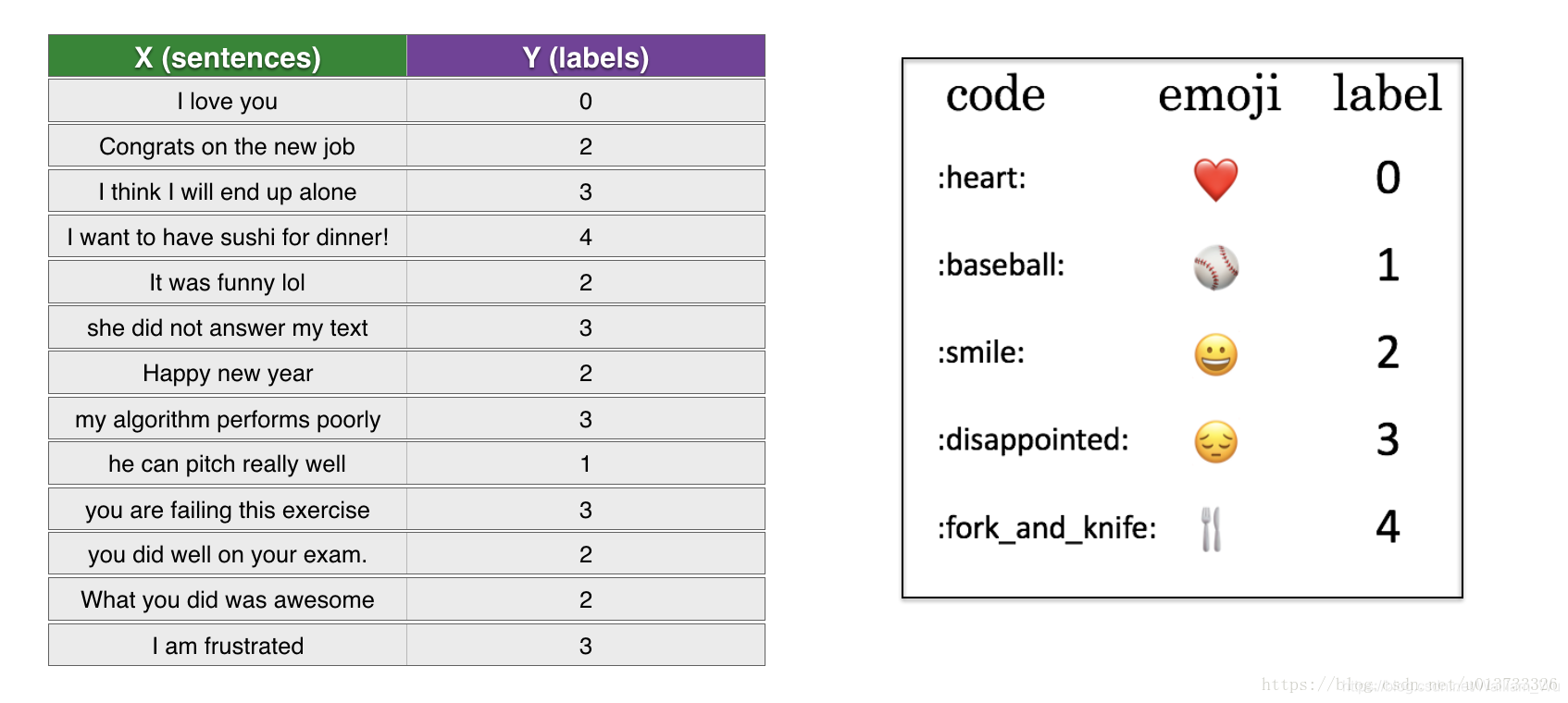
資料集(X,Y):
X:包含了127個字串型別的短句
Y:包含了對應短句的標簽(0-4)
匯入模塊:
import numpy as np
from emo_utils import *
import emoji
import matplotlib.pyplot as plt
加載資料集,訓練集:127,測驗集:56 :
X_train, Y_train = read_csv('data/train_emoji.csv')
X_test, Y_test = read_csv('data/tesss.csv')
maxLen = len(max(X_train, key=len).split()) #計算陳述句最大長度,方便后面補0操作
你可以看看訓練集中有什么:
注:由于字體緣故,故在Pycharm中顯示的表情是黑色的,哭臉笑臉有點像,
for idx in range(8):
print("example"+ str(idx) +":")
print(X_train[idx], label_to_emoji(Y_train[idx]))
Pycharm輸出:
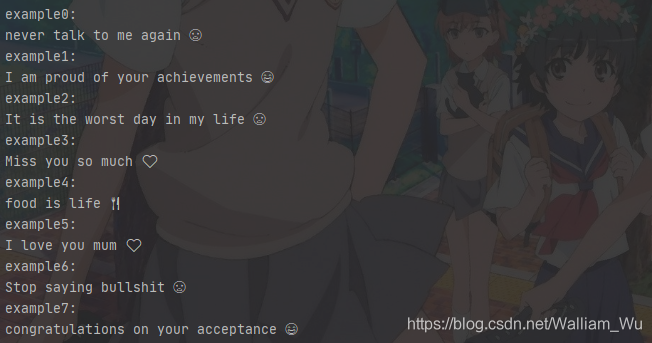
Notebook輸出:

2.2 - Emojifier-V1的結構
實作“Emojifier-V1”基準模型:
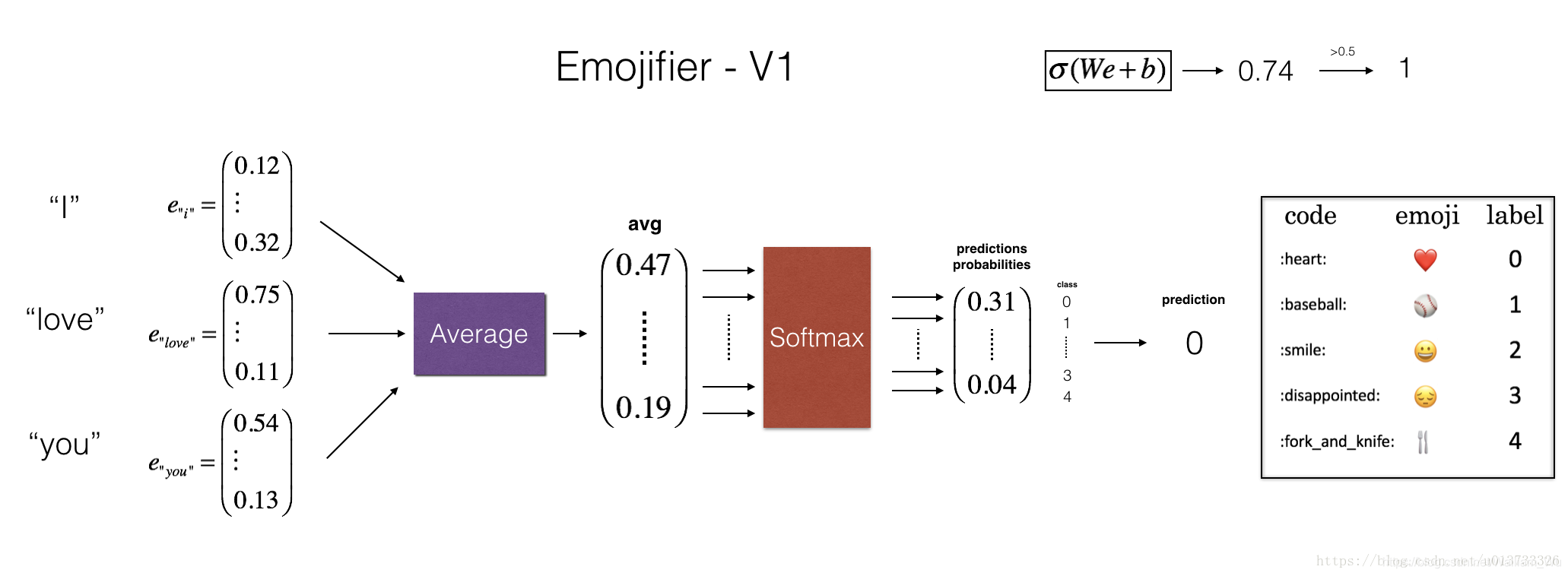
模型的輸入是一段文字(比如“l love you”),輸出的是維度為(1,5)的向量,最后在argmax層找尋最大可能性的輸出,現在我們將我們的標簽Y轉換成softmax分類器所需要的格式,即從(m,1)轉換為one-hot編碼(m,5),每一行都是經過one-hot編碼后的樣本,其中Y_oh指的是“Y-one-hot”,
Y_oh_train = convert_to_one_hot(Y_train, C = 5)
Y_oh_test = convert_to_one_hot(Y_test, C = 5)
下面實作模型,
2.3 - 實作Emojifier-V1模型
①如圖2-4所示,第一步我們需要做的是將輸入的句子轉換為對應的詞向量表示;然后獲取均值;我們將使用預訓練的50維的GloVe詞嵌入,
加載詞嵌入:
word_to_index, index_to_word, word_to_vec_map = read_glove_vecs('data/glove.6B.50d.txt')
這里我們加載了:
word_to_index:字典型別的詞匯(400,001個)與索引的映射(有效范圍:0-400,000)
index_to_word:字典型別的索引與詞匯之間的映射,
word_to_vec_map:字典型別的詞匯與對應GloVe向量的映射,
②接下來我們將實作sentence_to_avg()函式,我們可以將之分為以下兩個步驟:
- 把每個句子轉換為小寫,然后分割為串列,我們可以使用X.lower() 與 X.split(),
- 對于句子中的每一個單詞,轉換為GloVe向量,然后對它們取平均,
def sentence_to_avg(sentence, word_to_vec_map):
# Step 1: 分割句子,轉換為串列,
words = sentence.lower().split()
# 初始化均值詞向量
avg = np.zeros((50,))
# Step 2: 對詞向量取均值
total = 0
for w in words:
total += word_to_vec_map[w]
avg = total/len(words)
return avg
現在我們可以實作所有的模型結構了,在使用sentence_to_avg()之后,進行前向傳播,計算損失,再進行反向傳播,最后再更新引數,
根據圖2-4模型結構實作model()函式,Yoh是已經經過獨熱編碼后的Y,那么前向傳播以及計算損失的公式如下:
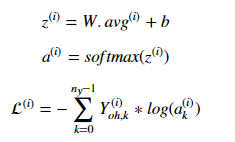
def model(X, Y, word_to_vec_map, learning_rate = 0.01, num_iterations = 400):
"""
在numpy中訓練詞向量模型,
引數:
X -- 輸入的字串型別的資料,維度為(m, 1),
Y -- 對應的標簽,0-7的陣列,維度為(m, 1),
word_to_vec_map -- 字典型別的單詞到50維詞向量的映射,
learning_rate -- 學習率.
num_iterations -- 迭代次數,
回傳:
pred -- 預測的向量,維度為(m, 1),
W -- 權重引數,維度為(n_y, n_h),
b -- 偏置引數,維度為(n_y,)
"""
np.random.seed(1)
# 定義訓練數量
m = Y.shape[0]
n_y = 5
n_h = 50
# 使用Xavier初始化引數
W = np.random.randn(n_y, n_h) / np.sqrt(n_h)
b = np.zeros((n_y,))
# 將Y轉換成獨熱編碼
Y_oh = emo_utils.convert_to_one_hot(Y, C=n_y)
# 優化回圈
for t in range(num_iterations):
for i in range(m):
# 獲取第i個訓練樣本的均值
avg = sentence_to_avg(X[i], word_to_vec_map)
# 前向傳播
z = np.dot(W, avg) + b
a = emo_utils.softmax(z)
# 計算第i個訓練的損失
cost = -np.sum(Y_oh[i]*np.log(a))
# 計算梯度
dz = a - Y_oh[i]
dW = np.dot(dz.reshape(n_y,1), avg.reshape(1, n_h))
db = dz
# 更新引數
W = W - learning_rate * dW
b = b - learning_rate * db
if t % 100 == 0:
print("第{t}輪,損失為{cost}".format(t=t,cost=cost))
pred = emo_utils.predict(X, Y, W, b, word_to_vec_map)
return pred, W, b
2.4 - 訓練模型
訓練模型:
pred, W, b = model(X_train, Y_train, word_to_vec_map)
print(pred)
執行結果:
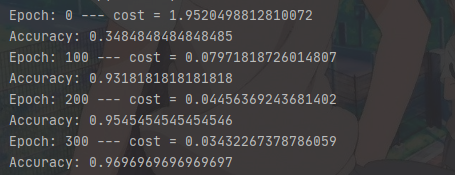
模型訓練的準確率達到97%,
2.5 - 驗證測驗集
print("Training set:")
pred_train = predict(X_train, Y_train, W, b, word_to_vec_map)
print('Test set:')
pred_test = predict(X_test, Y_test, W, b, word_to_vec_map)
執行結果:
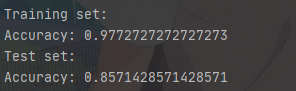
驗證集準確可達到86%,
2.6 - Emojifier-V1模型測驗
下面我們給出幾個句子,看看模型給出的表情時候正確吧!
X_my_sentences = np.array(["i adore you", "i love you", "funny lol", "lets play with a ball", "food is ready", "not feeling happy"])
Y_my_labels = np.array([[0], [0], [2], [1], [4],[3]])
pred = predict(X_my_sentences, Y_my_labels , W, b, word_to_vec_map)
print_predictions(X_my_sentences, pred)
執行結果:

從圖2-7我們可以發現準確率達到83%,即六個句子中最后一個句子是錯誤的,從而我們可以發現這個模型無法預測“not feeling happy”,“This movie is not good and not enjoyable”這一類的句子,因為它只是將所有單詞的向量做了平均,沒有關心過句中詞的順序,所以引出了本文介紹的第二個模型:Emojifier-V2模型,
3. Emojifier-V2:在Keras中使用LSTM模塊
現在我們構建一個能夠接受輸入文字序列的模型,這個模型會考慮到文字的順序,Emojifier-V2依然會使用已經訓練好的詞嵌入,
import numpy as np
np.random.seed(0)
import keras
from keras.models import Model
from keras.layers import Dense, Input, Dropout, LSTM, Activation
from keras.layers.embeddings import Embedding
from keras.preprocessing import sequence
np.random.seed(1)
from keras.initializers import glorot_uniform
匯入資料集、測驗集及詞嵌入:
X_train, Y_train = read_csv('data/train_emoji.csv')
X_test, Y_test = read_csv('data/tesss.csv')
word_to_index, index_to_word, word_to_vec_map = read_glove_vecs('data/glove.6B.50d.txt')
3.1 - Emojifier-V2模型的結構
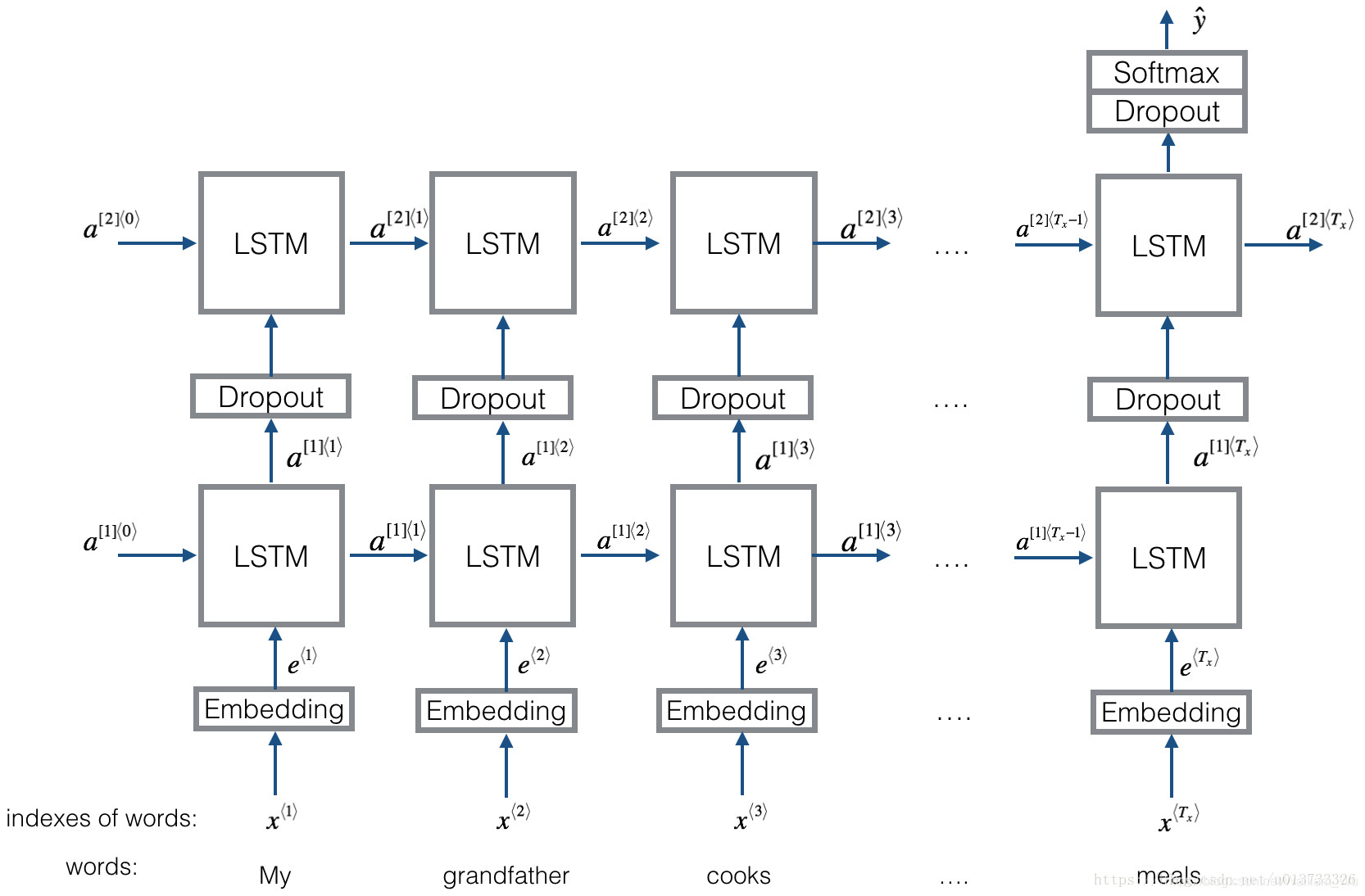
3.2 - Keras與mini-batching
在這個部分中,我們會使用mini-batches來訓練Keras模型,但是大部分深度學習框架需要使用相同的長度的文字,這是因為如果你使用3個單詞與4個單詞的句子,那么轉化為向量之后,計算步驟就有所不同(一個是需要3個LSTM,另一個需要4個LSTM),所以我們不可能對這些句子進行同時訓練,
那么通用的解決方案是使用填充,指定最長句子的長度,然后對其他句子進行填充到相同長度,比如:指定最大的句子的長度為20,我們可以對每個句子使用“0”來填充,直到句子長度為20,因此,句子“I love you”就可以表示為:
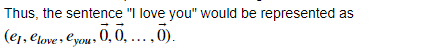
所以在這個例子中,任何任何一個超過20個單詞的句子將被截取,所以一個比較簡單的方式就是找到最長句子,獲取它的長度maxLen,然后指定它的長度為最長句子的長度,
maxLen = len(max(X_train, key=len).split())
3.3 - 嵌入層( The Embedding layer)
在keras里面,嵌入矩陣被表示為“layer”,并將正整數(對應單詞的索引)映射到固定大小的Dense向量(詞嵌入向量),它可以使用訓練好的詞嵌入來接著訓練或者直接初始化,在這里,我們將學習如何在Keras中創建一個Embedding()層,然后使用Glove的50維向量來初始化,因為我們的資料集很小,所以我們不會更新詞嵌入,而是會保留詞嵌入的值,
在Embedding()層中,輸入一個整數矩陣(batch的大小,最大的輸入長度),我們可以看看下圖:
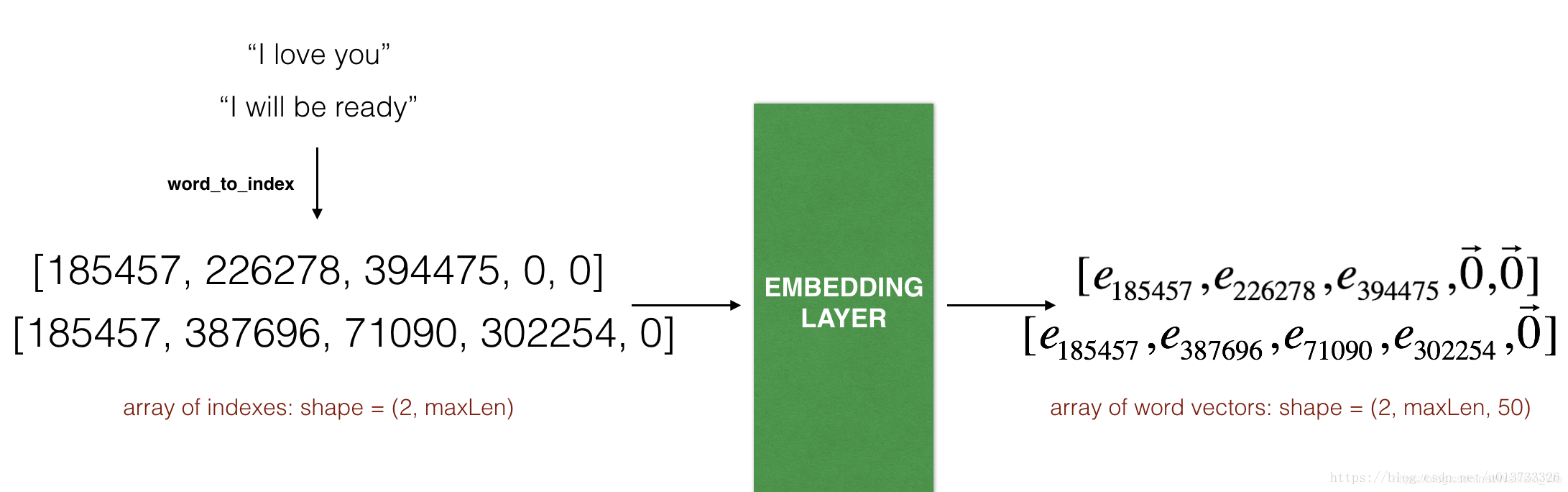
所以接下來將實作輸入句子并將其轉換為嵌入層可以接收的單詞指引所構成的串列,
def sentences_to_indices(X, word_to_index, max_len):
"""
輸入的是X(字串型別的句子的陣列),再轉化為對應的句子串列,
輸出的是能夠讓Embedding()函式接受的串列或矩陣(參見圖3-2),
引數:
X -- 句子陣列,維度為(m, 1)
word_to_index -- 字典型別的單詞到索引的映射
max_len -- 最大句子的長度,資料集中所有的句子的長度都不會超過它,
回傳:
X_indices -- 對應于X中的單詞索引陣列,維度為(m, max_len)
"""
m = X.shape[0] # 訓練集數量
# 使用0初始化X_indices
X_indices = np.zeros((m, max_len))
for i in range(m):
# 將第i個居住轉化為小寫并按單詞分開,
sentences_words = X[i].lower().split()
# 初始化j為0
j = 0
# 遍歷這個單詞串列
for w in sentences_words:
# 將X_indices的第(i, j)號元素為對應的單詞索引
X_indices[i, j] = word_to_index[w]
j += 1
return X_indices
下面就可以構造嵌入層,我們使用的是已經訓練好了的詞向量,在構建之后,使用sentences_to_indices()生成的資料作為輸入,Embedding()層將回傳每個句子的詞嵌入,
實作pretrained_embedding_layer()函式,它可以分為以下幾個步驟:
- 使用0來初始化嵌入矩陣,
- 使用word_to_vec_map來將詞嵌入矩陣填充進嵌入矩陣,
- 在Keras中定義嵌入層,當呼叫Embedding()的時候需要讓這一層的引數不能被訓練,所以我們可以設定trainable=False,
- 將詞嵌入的權值設定為詞嵌入的值,
def pretrained_embedding_layer(word_to_vec_map, word_to_index):
"""
創建Keras Embedding()層,加載已經訓練好了的50維GloVe向量
引數:
word_to_vec_map -- 字典型別的單詞與詞嵌入的映射
word_to_index -- 字典型別的單詞到詞匯表(400,001個單詞)的索引的映射,
回傳:
embedding_layer() -- 訓練好了的Keras的物體層,
"""
vocab_len = len(word_to_index) + 1
emb_dim = word_to_vec_map["cucumber"].shape[0]
# 初始化嵌入矩陣
emb_matrix = np.zeros((vocab_len, emb_dim))
# 將嵌入矩陣的每行的“index”設定為詞匯“index”的詞向量表示
for word, index in word_to_index.items():
emb_matrix[index, :] = word_to_vec_map[word]
# 定義Keras的embbeding層
embedding_layer = Embedding(vocab_len, emb_dim, trainable=False)
# 構建embedding層,
embedding_layer.build((None,))
# 將嵌入層的權重設定為嵌入矩陣,
embedding_layer.set_weights([emb_matrix])
return embedding_layer
3.4 - 構建Emojifier-V2模型
def Emojify_V2(input_shape, word_to_vec_map, word_to_index):
"""
實作Emojify-V2模型的計算圖
引數:
input_shape -- 輸入的維度,通常是(max_len,)
word_to_vec_map -- 字典型別的單詞與詞嵌入的映射,
word_to_index -- 字典型別的單詞到詞匯表(400,001個單詞)的索引的映射,
回傳:
model -- Keras模型物體
"""
# 定義sentence_indices為計算圖的輸入,維度為(input_shape,),型別為dtype 'int32'
sentence_indices = Input(input_shape, dtype='int32')
# 創建embedding層
embedding_layer = pretrained_embedding_layer(word_to_vec_map, word_to_index)
# 通過嵌入層傳播sentence_indices,你會得到嵌入的結果
embeddings = embedding_layer(sentence_indices)
# 通過帶有128維隱藏狀態的LSTM層傳播嵌入
# 需要注意的是,回傳的輸出應該是一批序列,
X = LSTM(128, return_sequences=True)(embeddings)
# 使用dropout,概率為0.5
X = Dropout(0.5)(X)
# 通過另一個128維隱藏狀態的LSTM層傳播X
# 注意,回傳的輸出應該是單個隱藏狀態,而不是一組序列,
X = LSTM(128, return_sequences=False)(X)
# 使用dropout,概率為0.5
X = Dropout(0.5)(X)
# 通過softmax激活的Dense層傳播X,得到一批5維向量,
X = Dense(5)(X)
# 添加softmax激活
X = Activation('softmax')(X)
# 創建模型物體
model = Model(inputs=sentence_indices, outputs=X)
return model
3.5 - 編譯訓練模型
在Keras中創建模型以后,我們需要編譯并評估這個模型,我們可以使用categorical_crossentropy 損失, adam 優化器與 [‘accuracy’] 指標,
model = Emojify_V2((maxLen,), word_to_vec_map, word_to_index)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
訓練模型前,由于Emojifier-V2模型是以(m, max_len)為輸入,(m, number of classes)為輸出,所以我們需要將X_train轉化為X_train_indices,Y_train轉化為Y_train_oh,
我們需要使用X_train_indices 與 Y_train_oh來擬合模型,我們使用epochs = 50 與 batch_size = 32
X_train_indices = sentences_to_indices(X_train, word_to_index, maxLen)
Y_train_oh = convert_to_one_hot(Y_train, C=5)
model.fit(X_train_indices, Y_train_oh, epochs=50, batch_size=32, shuffle=True)`
執行結果:
Epoch 1/50
132/132 [==============================] - 5s 41ms/step - loss: 1.6106 - acc: 0.1667
Epoch 2/50
132/132 [==============================] - 0s 1ms/step - loss: 1.5380 - acc: 0.3106
Epoch 3/50
132/132 [==============================] - 0s 1ms/step - loss: 1.5063 - acc: 0.3030
...
Epoch 48/50
132/132 [==============================] - 0s 1ms/step - loss: 0.0759 - acc: 0.9697
Epoch 49/50
132/132 [==============================] - 0s 1ms/step - loss: 0.0467 - acc: 0.9924
Epoch 50/50
132/132 [==============================] - 0s 1ms/step - loss: 0.0417 - acc: 0.9848
3.6 - 驗證測驗集
在訓練集準確率基本接近100%情況下驗證測驗集,
X_test_indices = sentences_to_indices(X_test, word_to_index, max_len=maxLen)
Y_test_oh = convert_to_one_hot(Y_test, C=5)
loss, acc = model.evaluate(X_test_indices, Y_test_oh)
print("Test accuracy = ", acc)
結果如下:
56/56 [==============================] - 1s 10ms/step
Test accuracy = 0.928571428571
驗證集的準確率為93%,
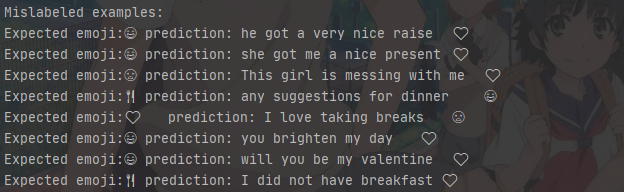
我們可以看看哪些結果是錯誤的:
print("Mislabeled examples:")
C = 5
y_test_oh = np.eye(C)[Y_test.reshape(-1)]
X_test_indices = sentences_to_indices(X_test, word_to_index, maxLen)
pred = model.predict(X_test_indices)
for i in range(len(X_test)):
x = X_test_indices
num = np.argmax(pred[i])
if (num != Y_test[i]):
print('Expected emoji:' + label_to_emoji(Y_test[i]) + ' prediction: ' + X_test[i] + label_to_emoji(num).strip())
print('\n')
結果如下:
3.7 - Emojifier-V2模型測驗
x_test = np.array(['not feeling happy','no one knows America better than Trump', 'I want to have lunch with you', 'I love playing basketball', 'I love China',
'I love yangping'])
X_test_indices = sentences_to_indices(x_test, word_to_index, maxLen)
pred = model.predict(X_test_indices)
for i in range(len(x_test)):
# print(x_test[i] +' '+ label_to_emoji(np.argmax(model.predict(X_test_indices))))
x = X_test_indices
num = np.argmax(pred[i])
print(x_test[i] + ' ' + label_to_emoji(num).strip())
Pycharm結果如下:
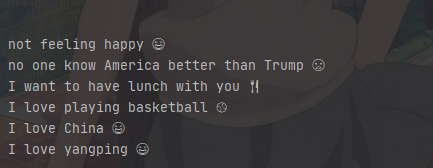
為了看得更清晰
Notebook結果如下:

注:最后輸出Pycharm與Notebook不太相似,可能是兩中編譯器所訓練的權重不同導致,同時在Pycharm實作時,所用的GloVe詞嵌入模型是從網上下載的,可能與Notebook中的版本不同,
但可以看出,Emojifier-V2模型可以正確預測“not feeling happy”所定義的表情符號,
結語
經過一下午的嘗試總算成功將Coursera上面的專案在自己本地電腦上復現出來,其中也遇到了許多bug,但還好都一一解決了,其中注意,在Pycharm上復現該專案時,讀取txt檔案會出現gbk編碼錯誤的bug,解決方式如下:
打開emo_utils.py檔案,其中將read_glove_vecs(glove_file)函式中open(glove_file, ‘r’)改為open(glove_file, ‘r’ , encoding=‘utf-8’),即解決,
def read_glove_vecs(glove_file):
with open(glove_file, 'r' , encoding='utf-8') as f:
words = set()
word_to_vec_map = {}
for line in f:
line = line.strip().split()
curr_word = line[0]
words.add(curr_word)
word_to_vec_map[curr_word] = np.array(line[1:], dtype=np.float64)
最后也墻裂推薦一下吳恩達老師的深度學習課程,真的非常好!!!
這篇博客相當于記錄自己的一次嘗試,也希望可以幫助到需要的同學們!
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/77162.html
標籤:其他