OpenVINO號稱支持CPU INT8的推理已經好久了 Introducing int8 quantization for fast CPU inference using OpenVINO 號稱在mobilenet-ssd上 i7-8700能有1.36X的性能提升。但是前幾個版本的calibration tool的變化實在太大了,從native C++變成python tool, 再到現在的DL workbench docker, 從開始的反人類操作到現在總算能用了。雖然還有很多bug,雖然現在只是對于世界知名模型轉換友好,但是總算能在我自己本地看看FP32到INT8的性能提升了
下面實操一下
先搭建環境
安裝docker for windows, 按照這個連接的windows安裝部分一步一步來 Install DL Workbench from Docker Hub* on Windows* OS
安裝DeepLearning Workbench
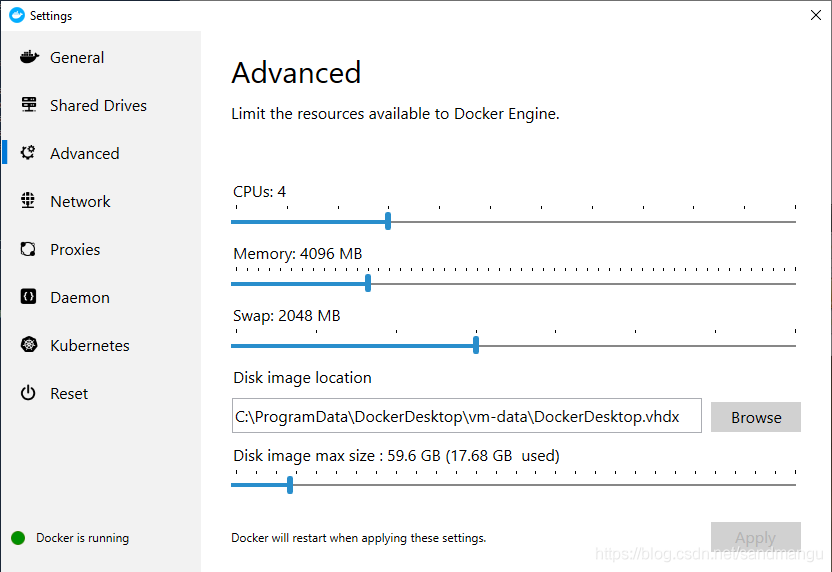
螢屏右下角docker圖示上點滑鼠右鍵,進入Setting,把記憶體設大一點,否則等下轉換可能會因為記憶體不夠導致crash,設定完成后docker會自動重啟動
啟動powershell, 運行下面的命令把docker鏡像拖到本地
docker pull openvino/workbench:latest
運行下面命令啟動workbench container
docker run -p 127.0.0.1:5665:5665 \
--name workbench \
--privileged \
-v /dev/bus/usb:/dev/bus/usb \
-v /dev/dri:/dev/dri \
-e PROXY_HOST_ADDRESS=0.0.0.0 \
-e PORT=5665 \
-it openvino/workbench:latest
看到powershell里嘩啦嘩啦運行列印出了一堆字就好了
以后再要運行,直接在powershell里運行命令
docker start -a workbench
接下來打開Chrome瀏覽器(不要用edge瀏覽器),打開地址 127.0.0.1:5665,如果出現下面的網頁就可以用了
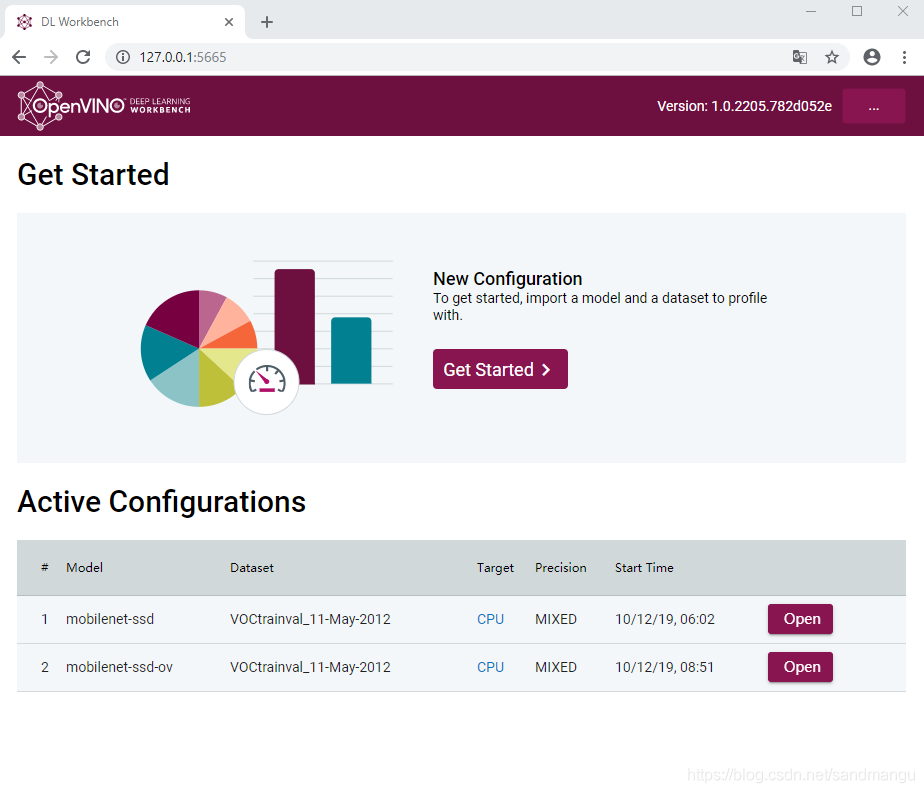
Workbench可以幫你看模型檔案的拓撲,測驗推理的性能和精確度,以及做FP32/FP16/INT8轉換。
具體匯入模型的教程可以參考Intel官網 Work with Models and Sample Datasets
轉換Mobilenet-ssd模型其實很簡單了,按照官網教程
匯入下載好的mobilenet-ssd caffe模型
匯入一個用于校正用的資料集,轉換INT8模型必須用ImageNet 或者 Pascal VOC格式的資料集,我這里用VOC的官方資料集
先驗證一下mobilenet-ssd官方模型的準確率,
做INT8轉換,轉換時候需要設允許的精度下降程度和使用資料集的百分比
等待轉換完成
下載轉換好的INT8模型到本地
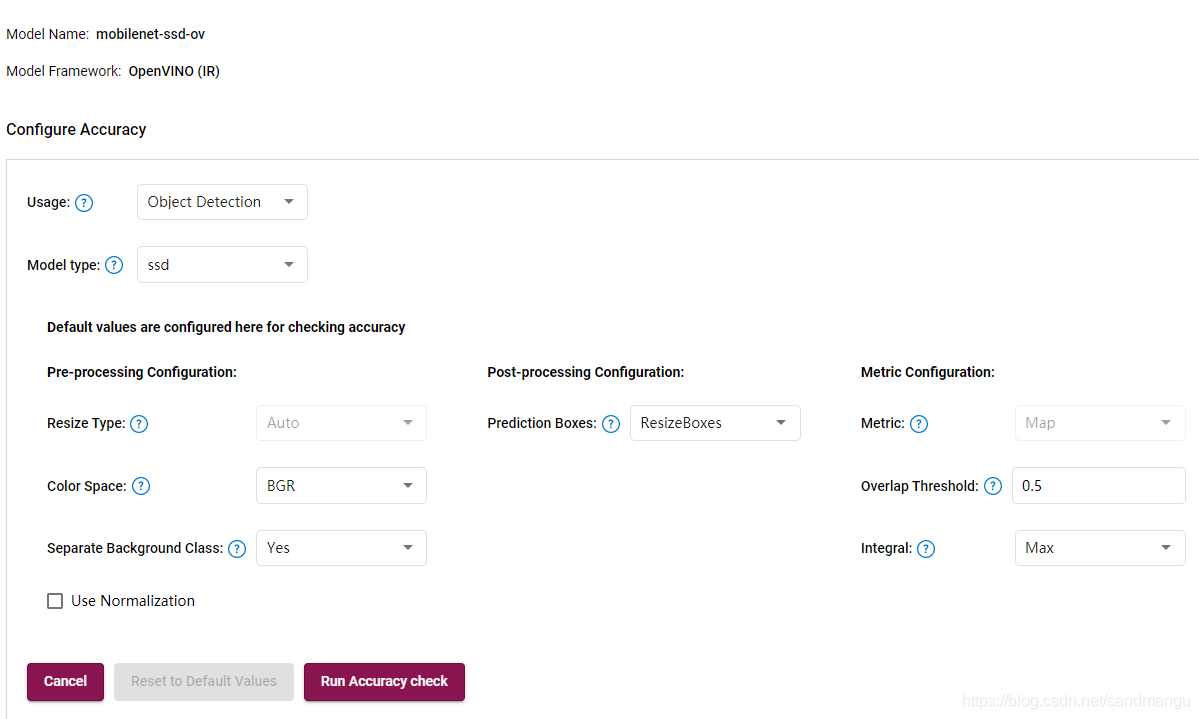
我的驗證模型精度的設定為
轉換好的網頁顯示如下
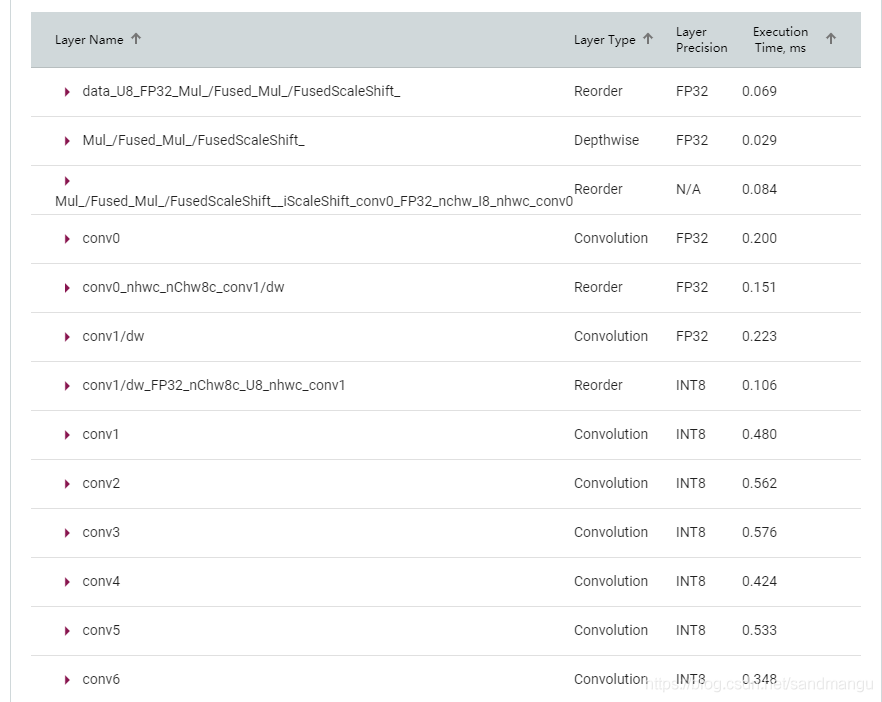
INT8的模型各層的資料型別也可以直接看到,不是所有層都轉換成了INT8
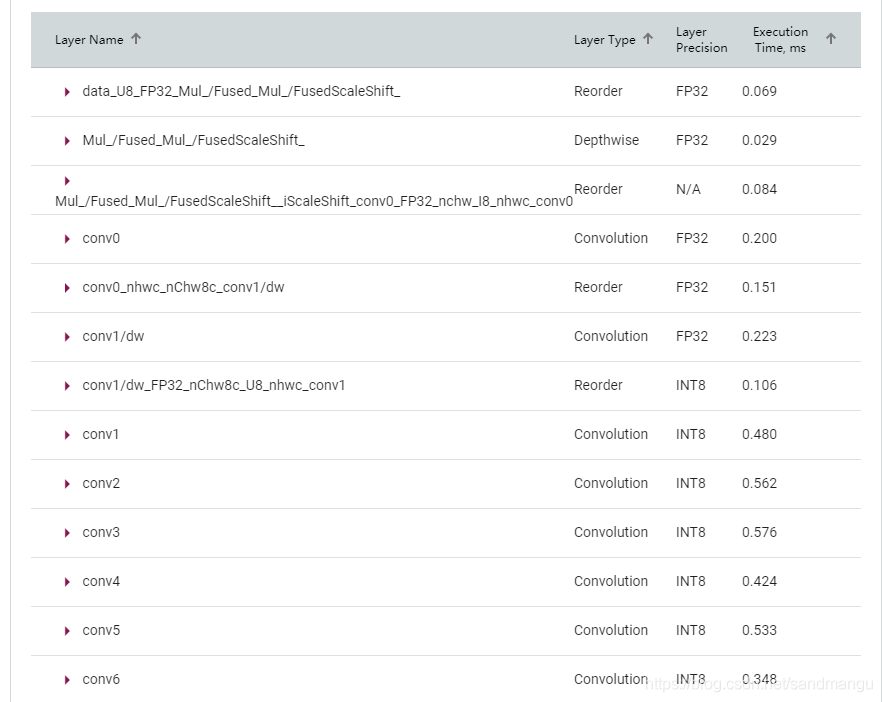
把模型帶進前面的benchmark程式里試試
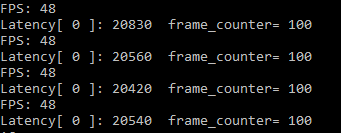
CPU Batchsize = 1, nireq = 1 Throughput: 48FPS
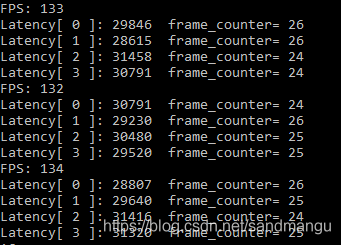
CPU Batchsize = 1, nireq = 4 Throughput: 133FPS
把INT8模型加載到GPU里,推理性能和GPU FP32一致,可見GPU在內部把INT8模型轉化為FP32
再測下MULTI:CPU,GPU INT8 Batchsize = 1, nireq = 8 (CPU_THROUGHPUT_AUTO/GPU_THROUGHPUT_AUTO), Throughput: 150FPS
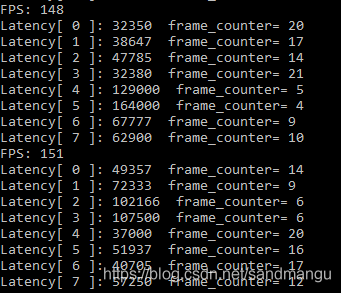
這個性能倒是跟MULTI:CPU,GPU FP16的最好資料類似,大概是因為雖然CPU算INT8快了不少,但是GPU反而在做FP32計算,拖了后腿。
簡單總結一下,OpenVINO的CPU INT8推理
CPU INT8推理性能和GPU FP16性能類似,相對與CPU FP32有30%以上的性能提升,如果CPU推理時推理模型能轉換成INT8模式,還是盡量用INT8模型
OpenVINO的INT8模型轉換只是在保證設定的識別精度的情況下盡量把某些層轉成INT8, 并不存在轉換INT8程序中重新使用資料集training來提升精度的程序。所以轉換出來的模型的效率不高,轉出來的模型是FP32/INT8的混合模型,不是純INT8模型
目前2019R3版本的OpenVINO的INT8模型轉換只是針對一些開源的公開模型比較友好,對于支持那些有自定義層Custom Layer的模型轉換還很麻煩,效果也不好
INT8模型對GPU來說等于FP32模型,所以GPU使用INT8模型效率不高,盡量不要給GPU加載INT8模型
最后補充一下,以上結果均是就mobilenet-ssd來測驗。資料顯示INT8 multi模式和FP16 multi模式性能接近。但是還沒有分析性能不能提升的原因在哪里,不知道此時瓶頸在記憶體帶寬上還是在計算量上。對于其他推理模型,可能結果不一樣;同時對于其他的硬體平臺,可能結果也不一樣,有的筆記本平臺Intel的集成顯卡性能更強一些,大部分臺式機上CPU的主頻和核數更多一些。所以測驗結果很可能也不一樣,但是就只做推理計算而言,普通的CPU和集成顯卡也是可以勝任相當一部分實時推理計算的需求的。
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/135587.html
標籤:英特爾技術
上一篇:基于openvino 2019R3的推理性能優化的學習與分析 (五) 基于CPU/GPU混合運算的推理(inference)性能分析
下一篇:基于openvino 2019R3的INT8推理(inference)性能的深入研究 (一) MobilenetV2