最近一直在研究OpenVINO的INT8的推理性能,原本以為INT8是個萬能膏藥,任何模型經過INT8轉換都可以提高性能。但是實戰發現并非如此,最近分析了2個模型MobilenetV2和MobilenetV3,發現MobilenetV2的模型在轉成INT8以后性能會大幅提升,但是MobilenetV3轉換成INT8模型后性能反而會大幅下降。原來一直以為是自己轉換的方法不對,后來深入分析了一下模型的架構,發現了一點規律,在這里分享一下 :)
首先是能夠利用INT8模型大幅提高性能的例子 MoiblenetV2
從這里下載模型https://github.com/tensorflow/models/tree/master/research/slim/nets/mobilenet 下載mobilenet_v2_1.4_224這個模型,然后轉換成OpenVINO FP32模型
python "c:\Program Files (x86)\IntelSWTools\openvino\deployment_tools\model_optimizer\mo_tf.py" --reverse_input_channels --input_shape=[1,224,224,3] --input=input --mean_values=input[127.5,127.5,127.5] --scale_values=input[127.5] --output=MobilenetV2/Predictions/Reshape_1 --input_model=mobilenet_v2_1.4_224_frozen.pb
在mo轉換的時候,指定了mean/shift和reverse_input_channel, 讓OpenVINO幫忙在inference的時候把輸入的像素做RGB轉BGR,并且歸一化到[-1,1]之間
通過netron觀察原始mobilenet_v2_1.4_224_frozen.pb的網路架構和轉換后的mobilenet_v2_1.4_224_frozen.xml的網路架構
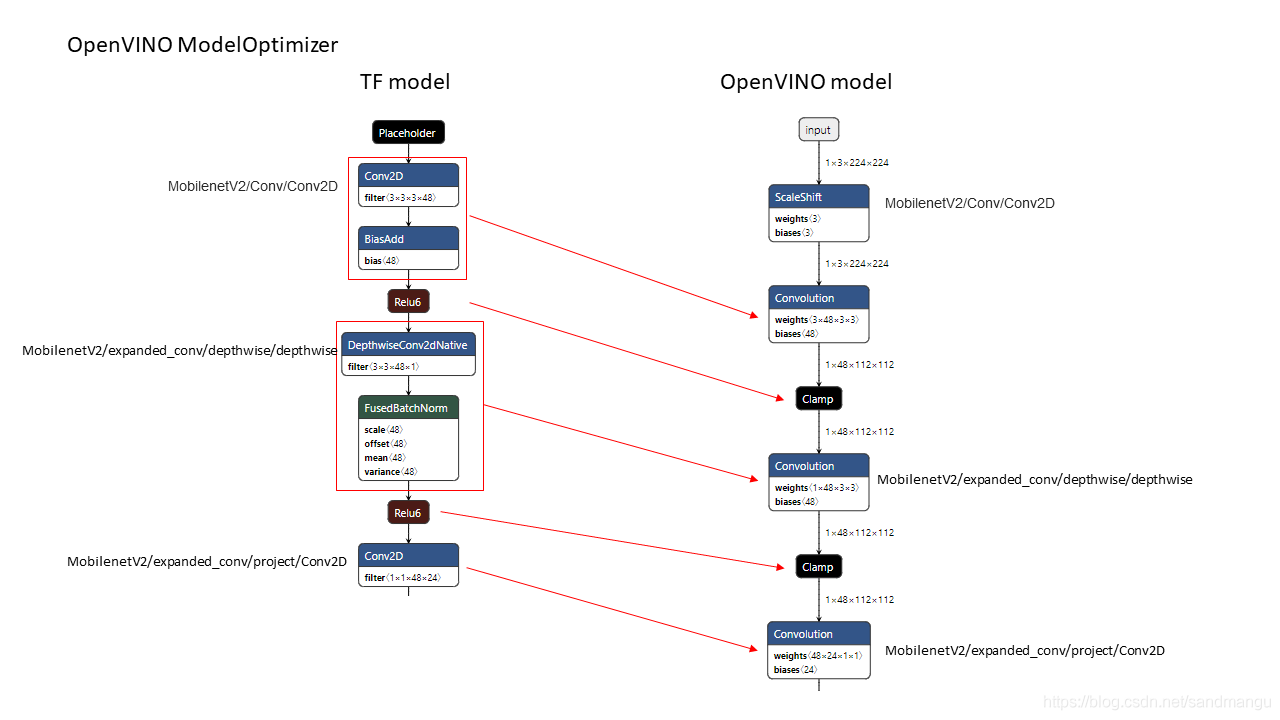
觀察一下輸入層下面幾層網路,可以看到MO在轉換的時候把Conv2D和BiasAdd合并優化成了一個Convolution操作,把DepthwiseConv2D和FusedBN合并成了一個Convolution操作。通過這種網路層的合并,節省了多個network layer之間的輸入輸出的記憶體讀寫的帶寬開銷,非常不錯 :)
接下來看看IE在運行時候的時間,利用openvino sdk自帶的benchmark app
benchmark_app.exe -m mobilenet_v2_1.4_224_frozen.xml -nireq 1 -nstreams 1 -b 1 -pc
這里只想獲得最快的單幀影像的推理時間,不考慮高并發,所以用以上引數指定每次inference request只有1,也可以用-api sync來獲得相同的資料
benchmark_app.exe -m mobilenet_v2_1.4_224_frozen.xml -api sync -pc
-pc引數可以讓benchmark之后列印出每一層網路計算的時間,再觀察一下頭幾層的運算時間
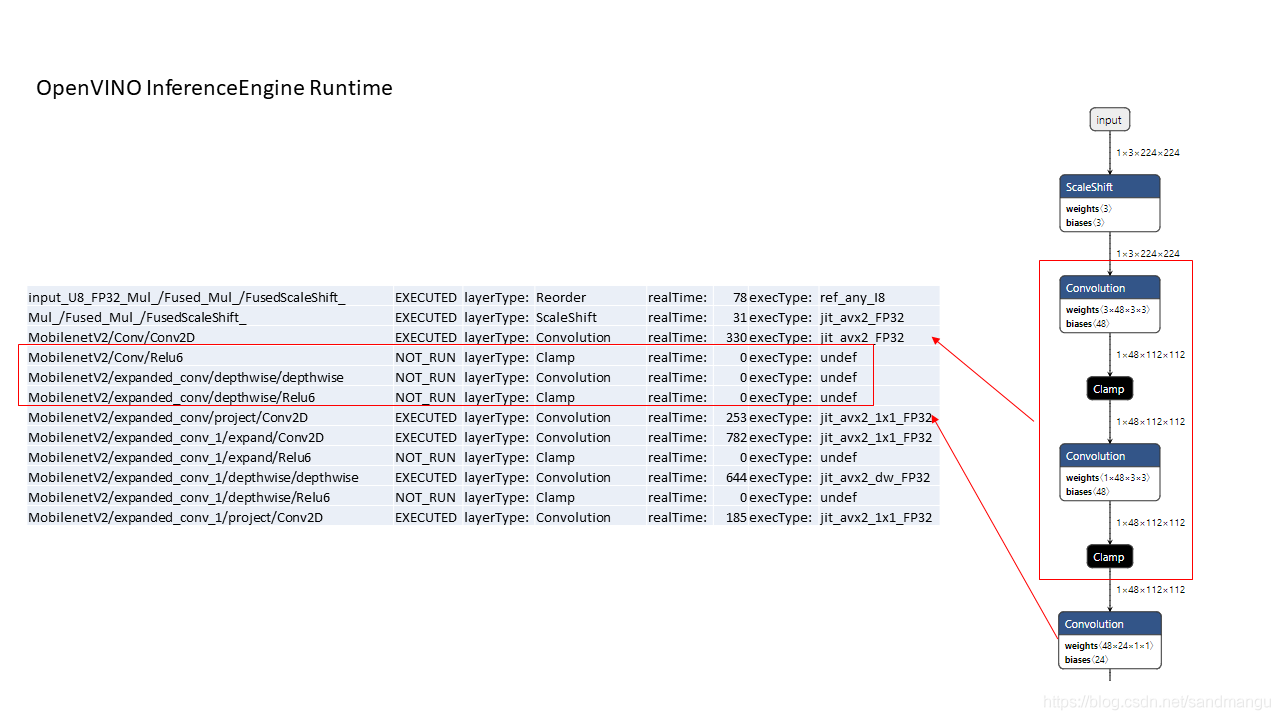
IE在運算時,通過MKL-DNN的post-ops操作,把convolution->relu6->depthwise_convolution->relu6 4層操作又合并在一起計算了,這下又節省了不少記憶體讀寫的開銷了。
最終我們得到了MobilenetV2 FP32的各層計算的時間, 每次推理7.75ms
Full device name: Intel(R) Core(TM) i5-7440HQ CPU @ 2.80GHz
Count: 6688 iterations
Duration: 60023.43 ms
Latency: 7.75 ms
Throughput: 111.42 FPS
接下來看看INT8模型的運行時間
首先轉換成INT8模型,模型轉換最簡單的方法就是用OpenVINO官方提供的docker workbench來轉換,全部圖形化操作,省去了寫各種轉換組態檔的時間;另一種方法用sdk自帶的calibration tool工具來轉換,如果不考慮轉換精度的話,可以設定轉換模式為-sm (simple mode), 在這種模式下,不需要提供用于計算轉換精度的樣本集,轉換工具會轉換所有能夠轉成INT8的網路層。這樣轉出來的模型雖然精度損失很大,但是可以用benchmark_app來快速評估轉換出來INT8模型的性能提升。
python "c:\Program Files (x86)\IntelSWTools\openvino\deployment_tools\tools\calibration_tool\calibrate.py" -sm -m mobilenet_v2_1.4_224_frozen.xml -e C:\Users\???\Documents\Intel\OpenVINO\inference_engine_samples_build\intel64\Release\cpu_extension.dll
轉換出來的INT8模型可以繼續用benchmark列印出各層的計算時間,并且和FP32的時間做一個對比
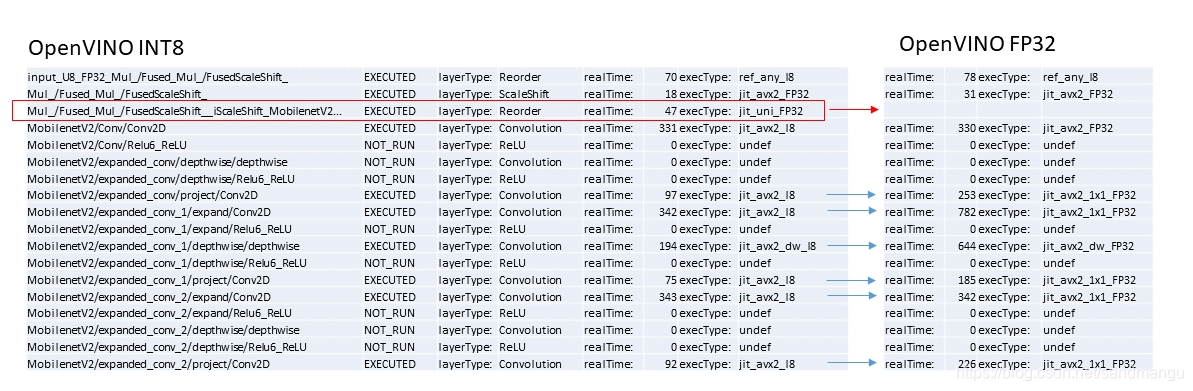
可以看到
INT8模型在進行Conv INT8計算前,多做了一步FP32, 因為MKL-DNN做Conv FP32計算時,最高效的記憶體格式是nChw8c,而Conv INT8的計算,首選記憶體格式是nhwc。所以從FP32計算切換到INT8模式前,要先做一步Reorder; 同理在INT8計算完以后回傳FP32計算前,也需要多做一步Reorder, 把記憶體資料排列再轉換回去。
相對于Conv FP32, 每次Conv INT8卷積計算的時間可以大幅度縮減。我的CPU最高支持到AVX2, 如果CPU支持AVX512, 這個計算時間可以繼續縮減。
總的INT8 模型的推理時間是4.70ms每幀,相對FP32推理的7.75ms 提升了不少
Full device name: Intel(R) Core(TM) i5-7440HQ CPU @ 2.80GHz
Count: 12037 iterations
Duration: 60006.28 ms
Latency: 4.70 ms
Throughput: 200.60 FPS
要注意的是, 上面這個4.70ms只是一個理論的資料。這個資料的前提是所有能夠轉成INT8的卷積計算全部轉成INT8計算。在實際轉換程序中,calibration tool會根據你定義好的精度損失閾值來動態的調整轉換的Conv層的數量,如果精度損失超過了你的閾值, 會再把一些Conv INT8卷積層再回退到FP32卷積層。最終得到的INT8模型里既會有INT8卷積層,也會有FP32卷積層,因此會實際的性能會不如這個理論值。
最終,統計了一下MobilenetV2 FP32和INT8推理時各層的數量和CPU計算用的時間
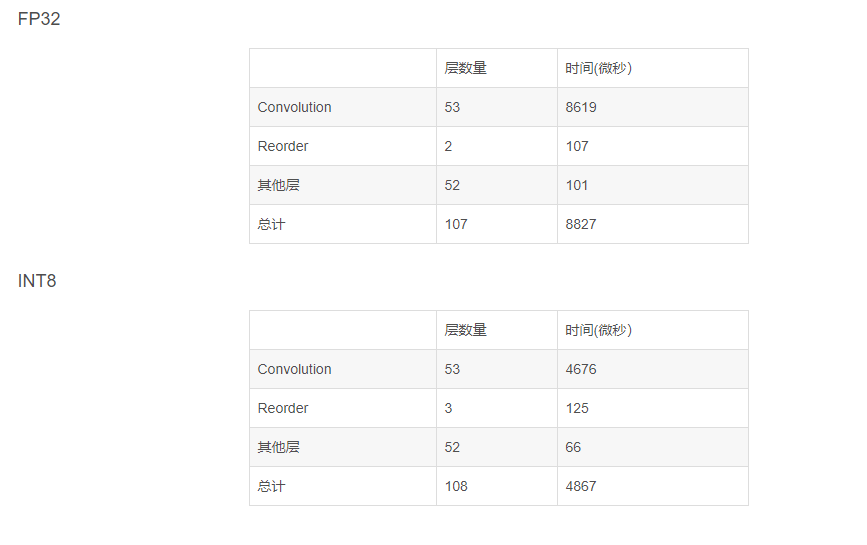
可以看出基本上在推理開始就通過一次Reorder開始做INT8卷積,然后就一直INT8卷積計算下去,直到最后計算Softmax前才切換回FP32資料。 這樣卷積層計算基本節省了一大半的時間,而額外增加的一層Reorder只增加了額外20us不到的開銷。
MobilenetV2是個非常好的基于OpenVINO的INT8模型提升性能的例子
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/135590.html
標籤:英特爾技術
上一篇:基于openvino 2019R3的推理性能優化的學習與分析 (六) 基于CPU的INT8推理(inference)性能分析