在OpenVINO 2019里是用Calibration tool把網路模型轉成INT8模型。到了OpenVINO 2020版本開始這個工具被去掉了,取而代之的是POT (Post-Training Optimization Tool)工具. POT的使用方法和引數的含義和Calibration Tool又有所不同,因此要轉INT8模型的話又要重新學習一遍官網的檔案。這里簡單記錄一下我用這個工具轉換mobilenet模型的一個程序。
這次用OpenVINO 2020轉換INT8主要用到2個工具
1. pot
這個是INT8轉換工具。在使用方法上和calibration tool不同的地方是calibration tool可以通過直接指定引數的方法來運行。而pot需要把大部分引數寫進一個config檔案,然后用
pot -c [config檔案]
的方法來運行。
2. accuracy_check
這個可以用來檢查模型在指定資料集上的推理精確度。
運行的命令和引數
accuracy_check -c [config組態檔] -s [放驗證資料集的根目錄路徑] -td CPU
首先是安裝程序
安裝程序和以前不一樣,以前是安裝好OpenVINO 工具包之后calibration tool就會帶在里面。而在OpenVINO 2020版之后,需要在安裝好OpenVINO之后再手動安裝accuracy_check和pot工具。
accuracy_checker安裝的路徑在
C:\Program Files (x86)\IntelSWTools\openvino\deployment_tools\open_model_zoo\tools\accuracy_checker
需要按照https://docs.openvinotoolkit.org/latest/_tools_accuracy_checker_README.html的說明運行這個目錄下的
python setup.py install
pot工具的安裝路徑在
C:\Program Files (x86)\IntelSWTools\openvino\deployment_tools\tools\post_training_optimization_toolkit
需要按照https://docs.openvinotoolkit.org/latest/_README.html的說明運行這個目錄下的
python setup.py install
安裝好工具之后就可以做INT8的模型轉換和模型的推理精度統計了
我的作業路徑c:\temp\mobilenetv3里有這么幾個檔案
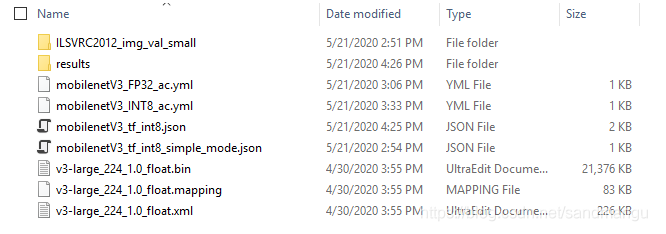
v3-large_224_1.0_float.xml/.bin/.mappling是mobilenet v3的FP32 OpenVINO IR模型
mobilenetV3_tf_int8_simple_mode.json和mobilenetV3_tf_int8.json是pot轉換Int8模型的組態檔 (pot命令專用)
mobilenetV3_FP32_ac.yml和mobilenetV3_INT8_ac.yml是accuracy_checker統計FP32模型和int8模型推理精確度的組態檔 (accuracy_checker命令專用)
ILSVRC2012_img_val_small目錄用來存放驗證資料集和資料集的注釋檔案
運行后會生成
results目錄用來存放轉換出來的int8模型
ILSVRC2012_img_val_small下面的資料集和標注檔案
我這個資料集是從imagenet里切出來的所以比較簡單,目錄里就是一個標注檔案加一堆圖片
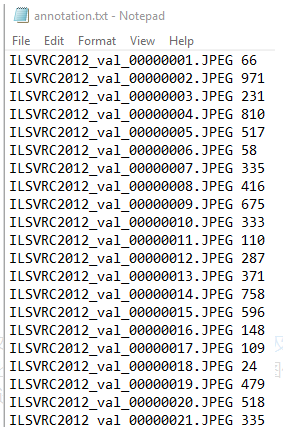
annotation.txt里每行就是目錄里的檔案名和對應的imagenet的標注label
這個label在網上有2個版本,可以參考這篇文章 下載imagenet2012資料集,以及label說明 自己弄一下。因為mobilenet是屬于影像分類classification,所以標注檔案比較簡單。要是mobilenet-ssd那種影像識別的模型,label就比較復雜,需要按照官方檔案把識別視窗坐標,分類label都弄進去。
先從前面calibration_tool用過的simple mode轉換開始,先寫一個轉換組態檔mobilenetV3_tf_int8_simple_mode.json
{
"model": {
//"model_name"指定生成的int8 IR檔案的檔案名
"model_name": "v3-large_224_1.0_int8",
//"model""weights"對應要轉換的原始IR檔案名
"model": "v3-large_224_1.0_float.xml",
"weights": "v3-large_224_1.0_float.bin"
},
"engine": {
//"type" 指定用simplified模式
"type": "simplified",
// you can specify path to directory with images or video file
// also you can specify template for file names to filter images to load
// templates are unix style
//資料集的目錄
"data_source": "ILSVRC2012_img_val_small"
},
"compression": {
//指定優化的硬體運行設備,2020新加的設定,為將來用GPU推理做準備
"target_device": "CPU",
//優化演算法設定,DefaultQuantization是默認的優化演算法
"algorithms": [
{
"name": "DefaultQuantization",
"params": {
"preset": "performance",
"stat_subset_size": 300
}
}
]
}
}
然后運行
pot -c mobilenetV3_tf_int8_simple_mode.json
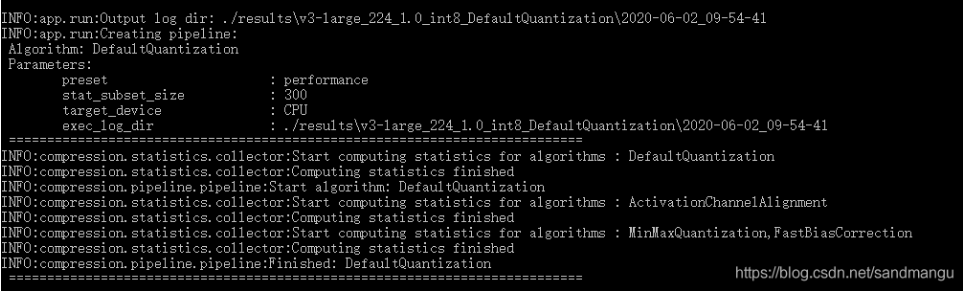
可以看到優化演算法增加到了3種 DefaultQuantization/ActivationChannelAlignment/MinMaxQuantization。但是從目前官方2020.2檔案看,只支持了前2種https://docs.openvinotoolkit.org/2020.2/_compression_algorithms_quantization_README.html
最終轉化的模型v3-large_224_1.0_int8.bin和v3-large_224_1.0_int8.xml生成到了./results\v3-large_224_1.0_int8_DefaultQuantization\2020-06-02_09-54-41下的optimized目錄里
接下來看看FP32模型和INT8模型的推理精準度
先配置mobilenetV3_FP32_ac.yml
models:
- name: v3-large_224_1.0_float
launchers:
#下面指定運行的框架 dlsdk就是openvino, 也可以是tensorflow或者其他框架
#model/weights是要測驗的模型檔案名
#adapter是告訴accuracy checker模型的輸出是目標分類還是目標識別或者其他的輸出
- framework: dlsdk
model: v3-large_224_1.0_float.xml
weights: v3-large_224_1.0_float.bin
adapter: classification
datasets:
#下面這部分是有關資料集的路徑,資料集的格式(imagenet,VOC或者其他)以及標注檔案的名字
- name: ILSVRC2012_img_val_small
data_source: ILSVRC2012_img_val_small
annotation_conversion:
converter: imagenet
annotation_file: "ILSVRC2012_img_val_small/annotation.txt"
#預處理告訴ac_checker工具在把資料集圖片送進模型前要做那些預處理,比如縮放,剪切或者調整RGB/BGR順序之類
preprocessing:
- type: resize
size: 256
- type: crop
size: 224
#這里定義統計準確度用的演算法,這里要看2種準確度,一個是top1的,還一個是top5的
metrics:
- name: accuracy @ top1
type: accuracy
top_k: 1
- name: accuracy @ top5
type: accuracy
top_k: 5
運行命令
accuracy_check -c mobilenetV3_FP32_ac.yml -s ./ -td CPU
看到輸出

看到從0%到100%就對了,這里有個小坑,就是accuracy_check運行時候必須用"-s ./"引數來指定資料集的根目錄,否則會報錯。
最終得到原始FP32模型的準確度為

再看看轉換出來的int8模型的準確度
mobilenetV3_INT8_ac.yml
models:
- name: v3-large_224_1.0_float
launchers:
- framework: dlsdk
model: results\v3-large_224_1.0_int8_DefaultQuantization\2020-06-02_09-54-41\optimized\v3-large_224_1.0_int8.xml
weights: results\v3-large_224_1.0_int8_DefaultQuantization\2020-06-02_09-54-41\optimized\v3-large_224_1.0_int8.bin
adapter: classification
datasets:
- name: ILSVRC2012_img_val_small
data_source: ILSVRC2012_img_val_small
annotation_conversion:
converter: imagenet
annotation_file: "ILSVRC2012_img_val_small/annotation.txt"
preprocessing:
- type: resize
size: 256
- type: crop
size: 224
metrics:
- name: accuracy @ top1
type: accuracy
top_k: 1
- name: accuracy @ top5
type: accuracy
top_k: 5
運行
accuracy_check -c mobilenetV3_int8_ac.yml -s ./ -td CPU
得到結果

可以看到,通過simplified_mode轉出來的int8模型,因為前面文章講到的mobilenetv3里面新的演算法還不支持int8轉換,所以導致精度損失很大
最后再試試pot里的新AccuracyAwareQuantization演算法,
{
"model": {
"model_name": "v3-large_224_1.0_float",
"model": "v3-large_224_1.0_float.xml",
"weights": "v3-large_224_1.0_float.bin"
},
"engine": {
"launchers":
[
{
"framework": "dlsdk",
"adapter": "classification"
}
],
"datasets":
[
{
"name": "imagenet_1000_classes",
"annotation_conversion": {
"converter": "imagenet",
"annotation_file": "ILSVRC2012_img_val_small/annotation.txt"
},
"data_source": "ILSVRC2012_img_val_small",
"preprocessing": [
{
"type": "resize",
"size": 256,
},
{
"type": "crop",
"size": 224,
}
],
"metrics": [
{
"name": "accuracy@top1",
"type": "accuracy",
"top_k": 1
},
{
"name": "accuracy@top5",
"type": "accuracy",
"top_k": 5
}
]
}
]
},
"compression": {
"target_device": "CPU",
"algorithms": [
{
//"name": "DefaultQuantization",
//"params": {
// "preset": "performance",
// "stat_subset_size": 300
//}
#這里改成AccuracyAwareQuantizaton演算法,下面的maximal_drop是定義的允許的轉換后模型的最大推理精度下降值
"name": "AccuracyAwareQuantization",
"params": {
"preset": "performance",
"stat_subset_size": 300,
"maximal_drop": 0.01,
}
}
]
}
}
運行
pot -c mobilenetV3_tf_int8.json
通過下面的列印可以看到這個演算法默認是先默認把所有支持int8轉換的層都轉成int8, 然后統計一遍推理精度,如果不滿足定義好的精度下降值,就把幾層int8的層回退到FP32模式,然后再統計推理精度,如果還不滿足就再繼續回退幾層int8到FP32,這么反復回圈下去,直到轉換出的模型滿足精度為止。
當然我這個轉換mobilenetV3的嘗試因為是演算法不支持的原因,轉出來的int8模型始終滿足不了定義的精度下降值, 最后毫無懸念的失敗了。如果是mobilenetV2模型,即使用simplified_mode, 精度下降也非常低,直接可以拿來用 :)
最后分享一下openvino 2020.2轉int8的感受
首先是新的模型修改了模型壓縮演算法,原來老的calibration tool轉出來的int8模型檔案大小和轉化前的FP32模型大小基本一致(20MB). 新的pot轉出來的int8模型的大小是5MB左右,終于變到了FP32模型的四分之一大小
是老的GPU是不支持int8推理的,我嘗試了一下在我的7代i5-7440HQ電腦上用集成顯卡推理基于GPU硬體算出來int8模型,速度比算FP32還慢。看來新的int8模型是給未來的intel顯卡做準備的 :)
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/135615.html
標籤:英特爾技術
上一篇:QT三維坐標系顯示三維球面