深度模型在訓練的時候,為了得到最好的推理精度,通常都不會把影像資料(0,255)直接送進去,而是會對資料做歸一化處理。比如把資料從(0,255)的8bit整數轉到(0,1)或者(-1,1)的32bit浮點之間;同時對于RGB資料,不同的推理框架在訓練時對于彩色通道的排列RGB/BGR也不同。因此對應的在推理的時候, 也需要把攝像頭抓到的資料也做對應的預處理, 把資料做一個歸一化,以及色彩通道的調整。
OpenVINO的用MO轉換模型的時候,也考慮到了這個問題,可以在mo轉換的時候加一些對應的引數來幫忙做資料預處理。具體的做法是在IE runtime在推理的時候,在模型的最上層先加一個ScaleShift層來做歸一化;對于RGB通道的調整,會再加一個reorder層來做資料的交換。這么做的好處是
OpenVINO在實作ScaleShift計算的時候會自動用SIMD指令加TBB或者OpenMP來做資料并行的優化,經過Intel工程師優化過的代碼遠比我們自己寫的C代碼實作效率要高了不知道幾條馬路
用MKLDNN做卷積的時候,前面也需要一個Reoder來調整記憶體資料排列順序,這個reorder操作可以捎帶手把RGB<->BGR的轉換也做了,不需要消耗額外的時間開銷。
下面用Resnet的ONNX模型來舉個例子,演示一下怎么在MO的時候設定preprocess引數
先看看ONNX Open Model Zoo上對Resnet 輸入資料和預處理的介紹
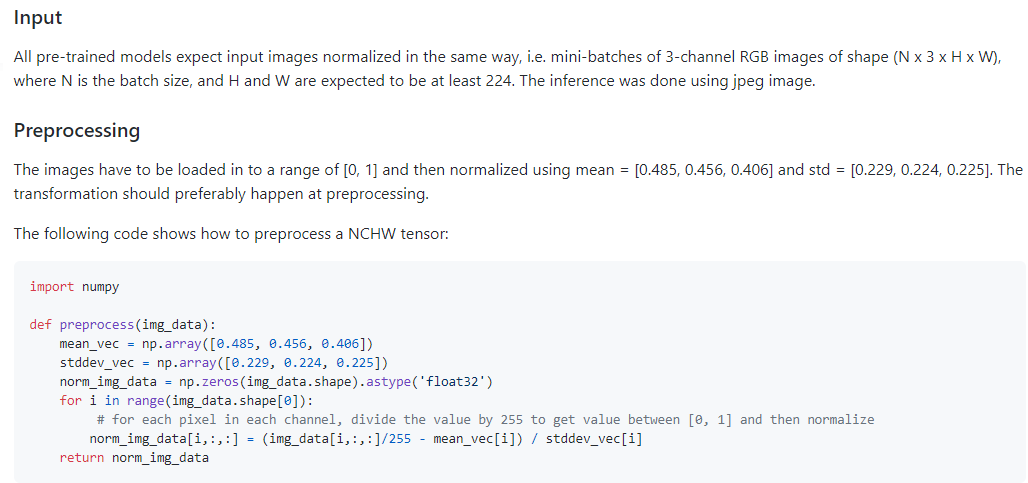
從網站上這部分的描述可以看到輸入資料要求是RGB排列
歸一化資料的演算法是
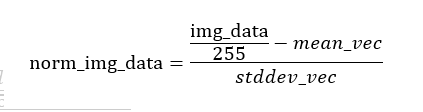
RGB 3個通道的mean, stddev分別為
mean_vec = np.array([0.485, 0.456, 0.406])
stddev_vec = np.array([0.229, 0.224, 0.225])
對應R通道的img_data, 應該是
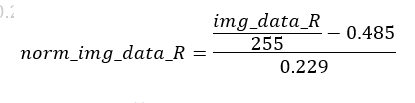
對應OpenVINO的ScaleShift層的Mean和Scale,計算公式是

對比一下上面Resnet ONNX模型預處理的公式
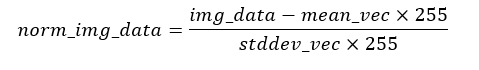
所以OpenVINO MO的Preprocess里Mean/Scale的值應該是
#Resnet ONNX preprocess
mean_vec = np.array([0.485, 0.456, 0.406])
stddev_vec = np.array([0.229, 0.224, 0.225])
#OpenVINO
mean_values = mean_vec * 255
scale_values = stddev_vec * 255
#mean_value = [123.675,116.28,103.53]
#scale_value = [58.395,57.12,57.375]
算出了Mean/Scale的值, 接下來開始MO轉換了
C:\Program Files (x86)\IntelSWTools\openvino\deployment_tools\model_optimizer>python mo_onnx.py --input_shape=[1,3,224,224] --input=data --reverse_input_channels --mean_values=data[123.675,116.28,103.53] --scale_values=data[58.395,57.12,57.375] --input_model .\resnet34-v2-7.onnx -o .\
這里用了幾個引數
--input_shape=[1,3,224,224] 告訴IE runtime 輸入的影像解析度為 224x224 3通道
--reverse_input_channels 告訴IE runtime 預處理時把顏色通道交換一下,因為我用的是OpenCV做的影像處理,影像資料默認是BGR排列的,需要轉成RGB再去推理
--mean_values=data[123.675,116.28,103.53] --scale_values=data[58.395,57.12,57.375] 前面算出來的歸一化引數
最后把轉換出來的模型用accuracy_check一下精度, 輸入的影像只做一個224x224的縮放,剩下的都交給IE推理的runtime去做
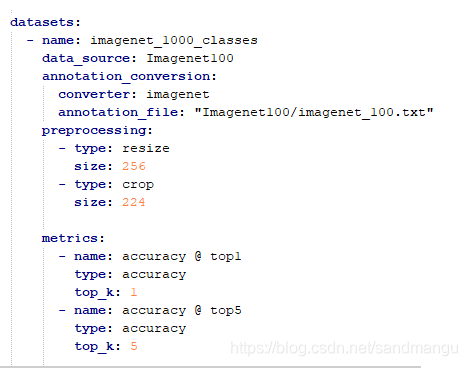
得到結果
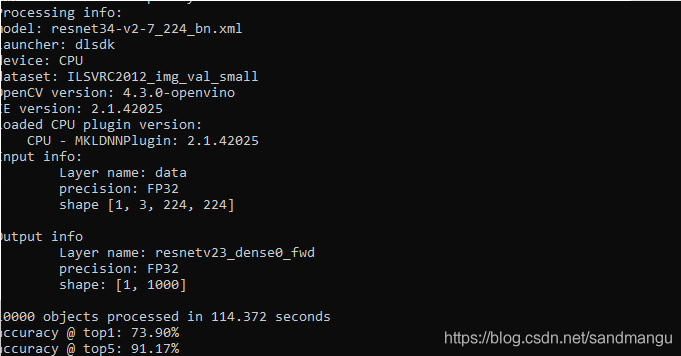
很不錯 :)
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/135618.html
標籤:英特爾技術