正所謂萬事俱備只欠東風,在一家公司資料資產足夠龐大的現狀下,如何實作資料價值變現,形成通用服務才是現在很多公司招資料產品崗的主要原因,但然不是說資料治理、資料埋點、資料管理等這些資料鏈路上的環節不重要哈,主要是這篇文章想講資料化應用,才這么說的哈哈!資料化應用的衍生形態會有多種多種,本篇文章寫的只是基于自己接觸過的資料產品進行一個整理,后面有機會接觸更多的資料產品之后,有時間會進行不斷豐富,
DMP管理平臺的理解:除資料采集和整合之后,能夠實作資料的可視化分析,資料的BI看板展現,資料內容和人群的圈選,并實作分流定制策略,現在的很多DMP產品都是事后分析型,只能夠提供洞察,即在事件發生之后進行資料分析洞察現狀,但真正的DMP產品應該是能夠實作事前分析,即基于洞察結果,整合運營管理平臺,實作用戶的定向分流和內容池子的分層設計,針對不同用戶群體和內容池子實作定向配比和展現,實作真正前端展示的千人千面管理配置后臺系統,整合整個資料鏈路的東西,才是一個真正的DMP系統,
舉個例子:針對短視頻的呈現,一個真正的DMP系統應該是能夠基于標簽維度圈選出不同的用戶群體,再基于標簽圈選出不同的內容池子,結合不同場景進行內容分發,比如白天的時候分發多一些視頻時長再6-15s的,晚上用戶休閑時間,多分發一些視頻時長再15-60s,能夠實作在DMP平臺上進行視頻池子和用戶池子的映射配比,以及前端展示資源位投放,
本篇文章主要整合自己對現有的一些DMP平臺的了解,主要是包括:神策分析、易觀方舟、GrowingIO、極光推送、阿里達摩盤、生意參謀等幾個比較常見的DMP平臺,整理對DMP平臺的不同模塊的個人理解,內容主要包括模塊:智能分析、用戶洞察、智能運營、智能推薦和BI可視化
一、智能分析
智能分析,即基于資料埋點,對用戶本身、用戶與內容、用戶與平臺等一系動作進行資料抽象追蹤復現,實作對用戶的洞察分析,一個DMP平臺的智能分析是否真正智能,很大程度上依賴于資料埋點策略的制定和收集,具體關于資料埋點相關的這里不多說明,
1、事件分析
①事件,是追蹤或記錄的用戶行為或業務程序,舉例來說,一個電商產品可能包含如下事件:用戶注冊、瀏覽商品、添加購物車、支付訂單等,
②事件分析,是指基于事件的指標統計、屬性分組、條件篩選等功能的查詢分析
③上述的事件分析是神策分析基礎的前端操作界面,還可以結合用戶分群設計,增加定向人群維度的塞選,針對定向人群進行分析
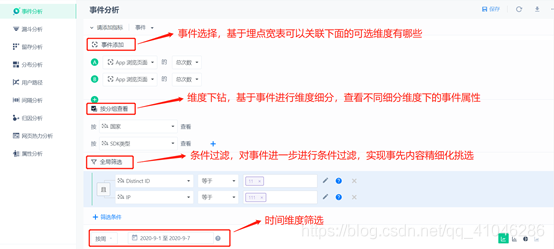
2、漏斗分析
①步驟:由一個元事件/虛擬事件 加一個或者多個篩選條件組成,表示一個轉化流程中的一個關鍵性的步驟;
②時間范圍:在界面上選擇的時間范圍,是指漏斗的第一個步驟發生的時間范圍;
③視窗期:用戶完成漏斗的時間限制,也即只有在這個時間范圍內,用戶從第一個步驟,行進到最后一個步驟,才能被視為一次成功的轉化
④漏斗分析:即基于步驟、時間范圍和視窗期,分析不同步驟的轉化情況
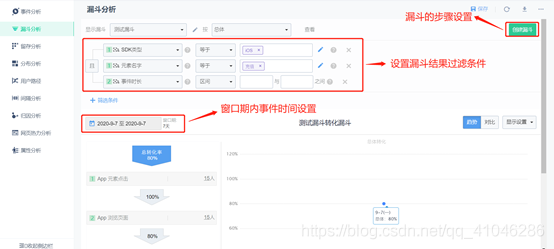
3、留存分析
①留存分析是一種用來分析用戶參與情況/活躍程度的分析模型,考查進行初始行為后的用戶中,有多少人會進行后續行為,這是衡量產品對用戶價值高低的重要指標,
②初始行為選擇用戶只觸發一次的事件,比如“注冊”、“激活設備”等,后續行為選擇你期望用戶重復觸發的事件,比如“發帖”、“購買”等,這種留存用于對比分析不同階段開始使用產品的新用戶的參與情況,從而評估產品迭代或運營策略調整的得失,
②初始行為和后續行為選擇相同的,期待用戶重復觸發的事件,這種留存用于分析忠實用戶的使用模式
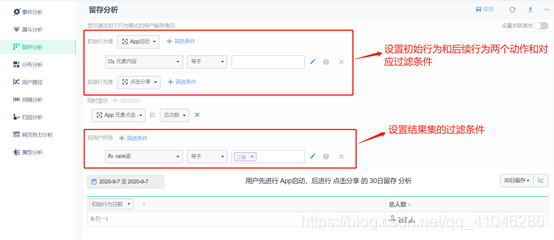
4、分布分析
①分布分析不但可以告訴你用戶有多依賴你的產品,還可以告訴你某個事件指標的用戶分布情況
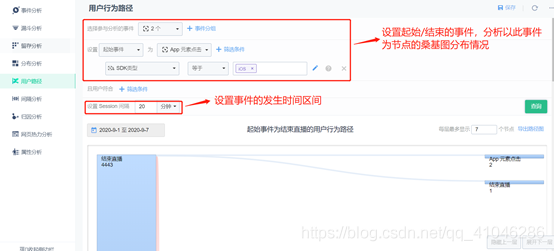
5、用戶路徑
①用戶路徑分析主要用于分析用戶在使用產品時的路徑分布情況
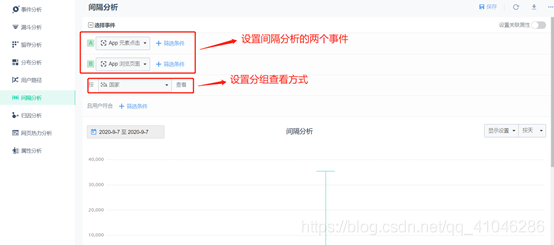
6、間隔分析
①如何衡量轉化,除了用漏斗看轉化率,還需要看轉化時長的分布情況,間隔分析即是解決這類問題和需求的,通過計算用戶行為序列中兩個事件的時間間隔,得到業務轉化環節的轉化時長分布,
②間隔分析通常是業務情況的反應,幫助我們探索可能存在的問題,而不設為直接優化的指標物件,例如產品用戶中提交訂單到支付訂單間隔時長中位數過長,反應出其中可能存在問題,需要結合事件分析,漏斗分析等功能定位具體問題
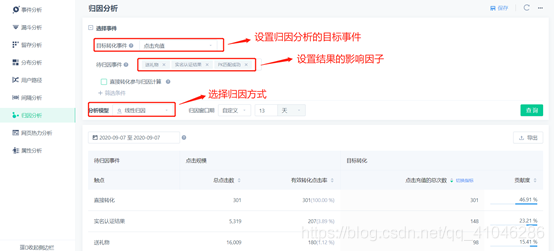
7、歸因分析
①業務上需要分析某個廣告位、推廣位對目標事件的轉化貢獻時,可以使用歸因分析模型進行分析,在歸因分析模型中,廣告位的點擊、推廣位的點擊被稱為「待歸因事件」,支付訂單等目標類事件被稱為「目標轉化事件」
②歸因類別說明:
A、首次觸點模型:多個「待歸因事件」對同一個「目標轉化事件」作出貢獻時,認為第一個「待歸因事件」功勞為 100%
B、末次觸點歸因:多個「待歸因事件」對同一個「目標轉化事件」作出貢獻時,認為最后一個「待歸因事件」功勞為 100%
C、線性歸因:多個「待歸因事件」對同一個「目標轉化事件」作出貢獻時,認為每個「待歸因事件」平均分配此次功勞
D、位置歸因:多個「待歸因事件」對同一個「目標轉化事件」作出貢獻時,認為第一個和最后一個「待歸因事件」各占 40% 功勞,其余「待歸因事件」平分剩余的 20% 功勞
E、時間衰減歸因:多個「待歸因事件」對同一個「目標轉化事件」作出貢獻時,認為越靠近「目標轉化事件」做出的貢獻越大
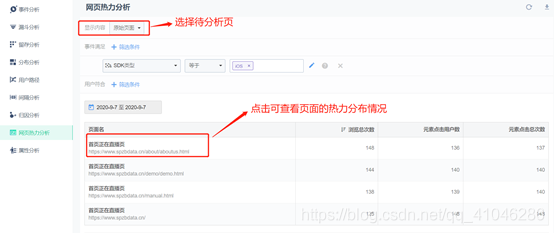
8、熱力分析
①網頁熱力分析主要用來分析用戶在網頁上的點擊、觸達深度等情況,并以直觀的效果展示給使用者
②顯示內容:分為原始頁面和頁面組兩類,原始頁面是用來分析單個頁面的點擊情況,而頁面組則用來分析一系列界面結構相似的網頁整體的瀏覽和點擊情況(例如京東的商品詳情頁,可以整體作為一個頁面組來進行分析)
9、session分析
該項可以查看神策的說明檔案:
https://manual.sensorsdata.cn/sa/latest/guide_analytics_session-16286059.html
①session即會話,一般是由多個連續的事件組成構成一個分析主體
②其設定需要關注兩個核心點:Session 應該包含哪些行為事件、Session 如何切割:需設定切割時長,即相鄰事件間的時間間隔超出此時長,則進行切割
③關注指標:
跳出率、退出率、Session 時長、Session 深度、Session 內事件時長、Session 初始事件、Session 屬性
10、用戶分析
①用戶分析即以用戶為主體,跟蹤分析用戶的明細情況,比如用戶的行為序列分析,特別是在漏斗分析中,針對轉化流失的用戶的洞察
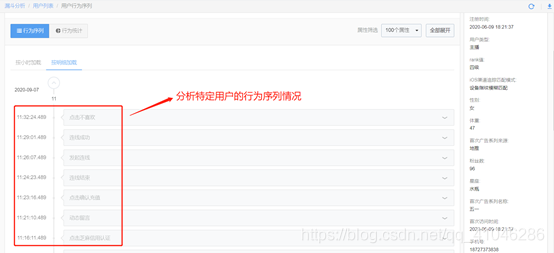
二、用戶洞察
用戶洞察模塊是基于在前面的分析基礎之上,進一步抽離出共性的東西進行抽象展現,形成一些通用的服務,滿足不同場景或者不同行業的需求,現在很多公司都在做的更多都是這一塊的東西,因其能夠更為直觀的給使用者帶來便捷的操作和結果呈現,
1、用戶畫像
用戶畫像可以說是現在數見不鮮的東西的,通過對用戶/內容的維度挖掘,然后展現出用戶/內容的多維度的資訊,實作對用戶/內容的洞察,其最大的好處是不僅能夠洞察用戶/內容多維度的資訊,還能夠成為推薦的輸入因子、能夠實作人群圈選等衍生服務,比如用戶分群,
①用戶畫像的核心:標簽維度的構建,即需要盡可能多的挖掘用戶/內容的維度資訊,為后續的呈現和篩選提供更多的分析選擇
②需要配備的功能:對于用戶畫像的設計,還需要做好標簽元資料的創建和管理
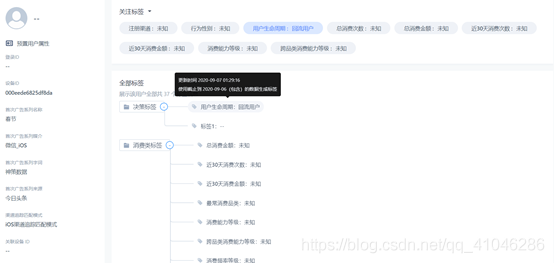
2、相似人群擴散
相似人群擴散是用戶畫像的衍生應用,在用戶畫像系統中,可以通過智能演算法(或簡單的標簽維度值相似性匹配),尋找到與「種子人群」特征相似的「相似用戶群」,針對「相似用戶群」我們可以進行有針對性的運營策略,比如:針對某個運營活動,某部分用戶的參與度非常之高,可以從中抽離出該群用戶的特征,進一步在用戶群體中尋找相似特征的用戶,再一次下發相同活動,
①相似人群的生成步驟可以分為三步:種子人群選擇 → 相似特征選擇 → 擴散人群范圍選擇
正向種子人群:預測人群的結果是與正向種子人群相似的
負向種子人群:預測人群的結果是與負向種子人群相悖的
②種子人群選擇:相似人群擴散功能使用用戶標簽、用戶屬性、用戶群、用戶行為、用戶行為序列作為種子人群的篩選條件,進行種子人群的構建
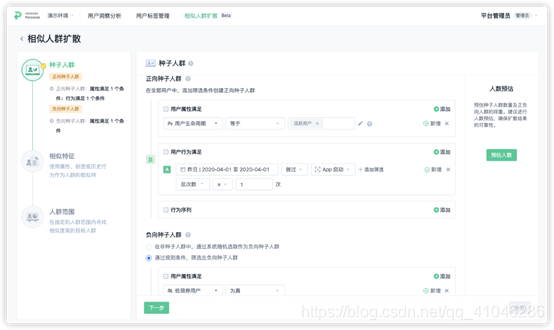
③相似特征選擇:相似特征是相似人群計算中的紐帶,根據選取的相似特征來學習和判斷其是否相似,使用用戶的標簽、用戶屬性、用戶行為的指標結果作為相似特征
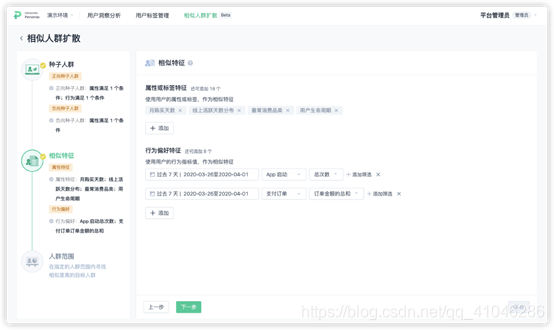
④擴散人群范圍選擇:「人群范圍」使用用戶標簽、用戶屬性、用戶群、用戶行為、用戶行為序列作為擴散人群的篩選條件,進行人群的構建,同時,可以選擇「是否包含種子人群」:能在計算計算結果中剔除掉種子人群
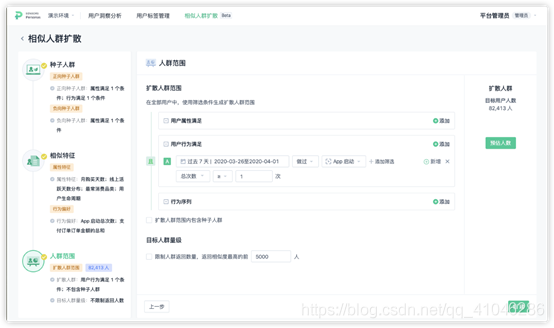
⑤在上訴實作相似人群擴散之后,最好還能夠進行基于AI的智能預測,實作對相似性的特征權重分析和相似性擬合分析,才能針對實作結果的可行度
特征影響指數:影響指數越大,可以反應出這個特征越重要
3、用戶分群
用戶分群是作為用戶畫像的另一衍生應用,即基于標簽的維度進行人群的圈選,使用同標簽維度下的用戶集,用于用戶特征分析,用戶分流、ABT測驗等一系列增長實驗操作
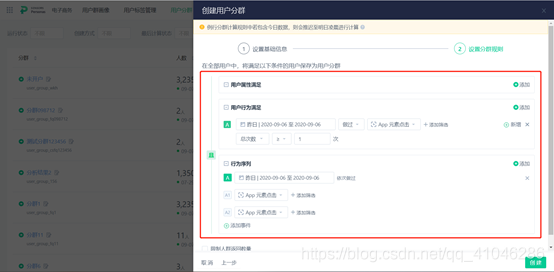
①用戶分群的人群圈選方式和用戶畫像其實本質相同,神策的用戶分群個人覺得比較好的點是其指標間的sql拼接邏輯是很抽象化和高復用性的,很多其他的DMP都是用的相同的模式,值得借鑒
②用戶分群更多的是要結合后續的用戶特征分析、用戶分流、訊息推送等后續動作才能凸顯其意義
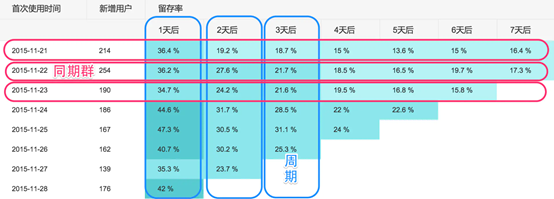
4、同期群分析
同期群分析,即對同期進入產品或同期使用了產品某個功能的用戶的后續行為表現進行評估,即進行斷代分析,
①同期群更多的是一種分析模式,當應用足夠廣泛的時候,有些會將其進一步抽象為單獨的模塊,特別是對于重運營模塊的產品,同期群的分析可能對于對用戶的分析有較強的需求
②同期群分析使你能夠觀察處于生命周期不同階段客戶的行為模式,而非忽略個體的自然生命周期,對所有客戶一刀切,同期群分析適用于營收、客戶流失率、口碑的病毒式傳播、客戶支持成本等任何你關注的資料指標
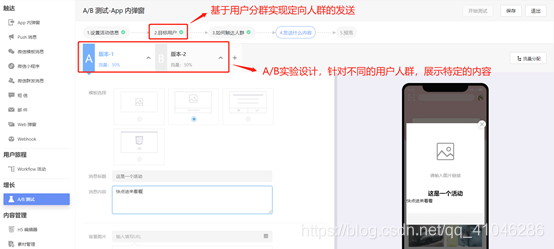
5、ABT和分流系統
前面的用戶分群能夠很好的基于標簽維度幫我們定向的圈選出不同的用戶群體集,對于新產品或者新功能的上線,常見的就會有灰度測驗,先針對部分種子用戶進行測驗,根據反饋結果進行調整優化后再全量開發,能很好的提高總體的用戶體驗;再比如在運營活動中,針對不同消費偏好的用戶群體,發送不同的推送文案等,這也是C端產品最為常見的模式,而要實作上述操作就需要有ABT系統和對應的分流系統,即實作人群分流,
6、特征分析
特征分析更多的是可視化的展現,針對特定人群進行特征展現,可視化是一個多變的作業,不同的呈現方式表達的內容都不一樣,在這里不進行過多的講述,現在做的比較好的可視化有echarts、阿里的Data-V等
三、智能運營
在用戶增長已經到達一定峰值的情況下,運營的作用凸顯重要,而基于資料實作智能精細化運營則是最大的催化劑,現存的DMP平臺,可以看到最多的就是訊息推送系統,當然訊息推送是最能夠觸達用戶的方式,而個人覺得,一個好的DMP的運營模塊,應該不當當包含訊息推送系統,還需要包含營銷預測、活動管理、資源配置等服務,這一塊自己的還有沒有實際接觸過完整的專案,所以只寫一點自己的認知理解,現在在這一塊做得比較好的是極光的訊息推送
1、訊息推送
A、概覽:訊息推送廣義上指服務端主動發給客戶端的訊息,訊息形態包括App Push、短信、微信通知、郵件等
B、組成:推送內容+推送條件+推送時機+推送人群,即把內容在合適條件下、合適的時間推給合適的人,
①推送時機:是指推送的時間分為定時推送、立刻推送、回圈定時推送;
②推送人群:是指推送物件,分為基于用戶分群定向推,基于指定UID/DID定向推
③推送內容:即推送后用戶在App通知欄看到的訊息標題、訊息正文和點擊后的落地頁,其中標題和正文可以添加用戶變數,用戶接收到獨有的個性化文案
④推送條件:分為手動和自動,事件規則是指基于App內產品邏輯,當用戶滿足預設的邏輯時自動推送
C、常見應用場景
①運營活動推廣:創作大賽、熱門優惠活動等
②緊急事項公告:特殊節日部分功能關閉、春節物流停運、緊急安全事項通知等
③App業務通知:青檸任務獎勵領取、新用戶獎勵、關注主播開播、優惠券到期、購物車商品降價等
④離線聊天訊息提醒:IM聊天離線提醒
D、監測指標:推送的有效用戶數、下發成功數、到達數、展示數、點擊數、到達率、點擊率,標簡單說明如下:
①有效可下發數:轉化CID成功的用戶數(非有效可下發的情況:用戶ID無效、用戶未系結個推SDK、組態檔實效)
②下發成功數:成功下發到客戶端設備的數量(非下發成功的情況:用戶卸載APP、90天未登錄、未聯網)
③到達數:客戶端回傳接受成功的數量(非到達情況:客戶端回執跨天或者回執數有遺漏)
④展示數:客戶端展示的數量(非展示情況:用戶關閉通知權限、廠商未開放介面回呼)
⑤點擊數:點擊訊息數量(非點擊情況:用戶不感興趣忽略或者離線訊息過期)
E、其他說明:
①目前支持離線通道下發的安卓廠商僅有VIVO、OPPO、華為、小米、魅族五個廠商,且這五個廠商有各自ROM版本和手機型號的要求,
②離線通道只是在線通道無法下發的補償,用戶手機不滿足以上條件、或者長時間未登錄、卸載App即使離線通道也無法觸達,因此離線通道觸達折損因素比較多,
③通常情況下push觸達率和App榷訓正相關,但是第三發服務商有App聯盟互相喚起的功能,有一定的效果,
2、營銷預測
營銷預測類的資料產品,更多的像是傳統的CRM系統,能夠實作對客戶、訂單等和公司營業額相關的模塊管理,想之前作業經歷接觸過的是叫“特斯拉”的管理平臺,實作對客戶合同等相關的管理,能夠對客戶的訂單相關資訊進行資料化的管理,實作收益預測,營銷策略制定等,
現在有專門的CRM產品經理,個人感覺這一塊更多的已經隔離出資料產品的系列,但是如果能夠將此模塊集成到一個DMP系統上,打通各模塊的資料鏈接,能夠更好的實作資料驅動營銷決策,神策的神策客景產品就類似這樣的資料產品
3、運營資源管理和配置
運營資源管理和配置,是指能夠實作對運營活動、運營管理、產品資源調度的平臺,其實就是我們現在很多公司的運營活動管理后臺,但現在的運管管理后臺有個很大的弊端就是其與其他的資料類產品是隔離的,也不能很好的配置產品模塊和用戶、內容池,
一個真正的運營后臺應該是能夠實作個性化配置用戶池、內容池和產品模塊池的,比如:基于多個用戶分群的池子和內容包圈選出來的內容池子,進行針對不同人群的運營活動前端資源位的配置以及對應文案的分流相關的處理
四、智能推薦
智能推薦的資料類產品,更多就是集成推薦演算法模型,做到個性化配置商品和用戶人群,實作千人千面的設計,推薦系統更多的是基于自己公司的情況進行開發設計的,在這里只寫一些自己之前面試的時候被問到的一些關于推薦的點對應的知識的整理,
1、特征工程
特征工程一般包括特征構建、特征提取、特征選擇三部分, 特征提取與特征選擇都是為了從原始特征中找出最有效的特征,它們之間的區別是:
a) 特征提取強調通過特征轉換的方式得到一組具有明顯物理意義或統計意義的特征;
b) 特征選擇是從特征集合中挑選一組具有明顯物理意義或統計意義的特征子集,
兩者都能幫助減少特征維度、資料冗余,特征提取有時能發現更有意義的特征屬性,特征選擇的程序經常能表示出每個特征對于模型構建的重要性,
特征工程的標準化流程主要分為以下幾步:
(1)基于業務理解,找到對因變數有影響的所有自變數,即特征,
(2)評估特征的可用性、覆寫率、準確率等,
(3)特征處理:包括特征清洗、特征預處理、特征選擇,
(4)特征監控:特征對演算法模型的影響很大,微小的浮動都會帶來模型效果的很大波動,因此做好重要特征的監控可防止特征例外變動帶來線上事故
2、預測性建模的資料準備任務
① 資料清洗:識別和糾正資料中的錯誤,
② 特征選擇:找出與任務最相關的輸入變數,
③資料轉換:改變變數的型別、尺度或分布,
舉例:
a、規范化轉換:將變數縮放到0到1的范圍,
b、標準化轉換:將變數縮放為標準高斯分布
④ 特征工程:從可用資料中推導新變數,
⑤資料降維:創建縮減資料維數的映射
舉例:
a、主成分分析 (PCA)
b、奇異值分解 (SVD)
五、BI可視化
可視化的應用更多的是應用于資料大屏和BI資料看板,兩者的側重點不同,之前面試就被問過兩者的區別,個人認知內的是如下情況
①資料大屏更多的是一個門面作用,即視覺呈現效果大于內容,邏輯流程大于業務指標定義,更多的是用于會議展覽、業務監控、風險預警、地理資訊分析等多種業務的展示需求,為了展示需求可能會進行資料脫敏、資料造假等二次資料加工,現有比較有名的資料大屏服務有阿里云的Data-V、百度的SUGAR等
②BI資料看板更多的是內部資料洞察,一般都是展示各個業務線和整個公司層面關注的一些指標維度,比如GMV、渠道轉化這些,其更注重指標的真實性,不能進行任何資料造假,
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/1443.html
標籤:其他
上一篇:真香!阿里首發Spring Boot技術秘籍,實戰原始碼齊全了
下一篇:機器學習演算法背后的數學原理