不同的機器學習演算法是如何從資料中學習并預測未知資料的呢?
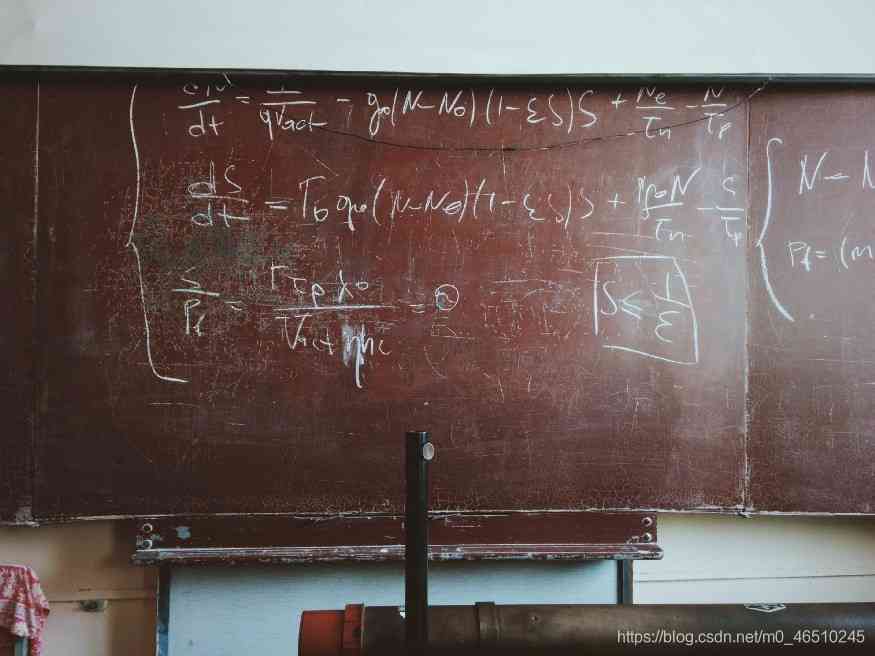
? 機器學習演算法的設計讓它們從經驗中學習,當它們獲取越來越多的資料時,性能也會越來越高,每種演算法都有自己學習和預測資料的思路,在本文中,我們將介紹一些機器學習演算法的功能,以及在這些演算法中實作的有助于它們學習的一些數學方程,
機器學習演算法的型別
機器學習演算法大致可以分為以下四類:
**監督學習:**用于預測的目標是已知的情況,這些演算法生成一個函式,該函式將輸入映射到輸出變數,回歸和分類演算法都屬于這一類,在回歸中,輸出變數是連續的,而在分類中,輸出變數包含兩個或更多的離散值,監督學習演算法包括線性回歸,邏輯回歸,隨機森林,支持向量機,決策樹,樸素貝葉斯,神經網路,
**無監督學習:**目標或輸出變數是未知的情況,這些演算法通常對資料進行分析并生成資料簇,關聯、聚類和維數約簡演算法屬于這一類,K-means聚類、PCA(主成分分析)、Apriori演算法等也都是非監督學習演算法,
**半監督學習:**它是監督和非監督學習方法的結合,它使用已知資料來訓練自己,然后標記未知資料,
**強化學習:**機器從“試錯”程序中學習的方法,機器從過去的決策經驗中學習,并利用它的學習來預測未來決策的結果,強化學習演算法的例子有Q-Learning, Temporal Difference等,
線性回歸
? 線性回歸是通過擬合資料點上的最佳直線來預測連續變數的結果,最佳擬合線定義了因變數和自變數之間的關系,該演算法試圖找到最適合預測目標變數值的直線,通過使資料點與回歸線之間的差的平方和最小達到最佳擬合線,
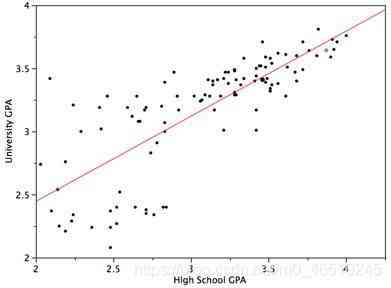
Equation: Y = c + m?X? + m?X? + …… +mnXn
Y → Dependent Variable or Target Variable
m → Slope
c → Intercept
X → Independent Variables
邏輯回歸
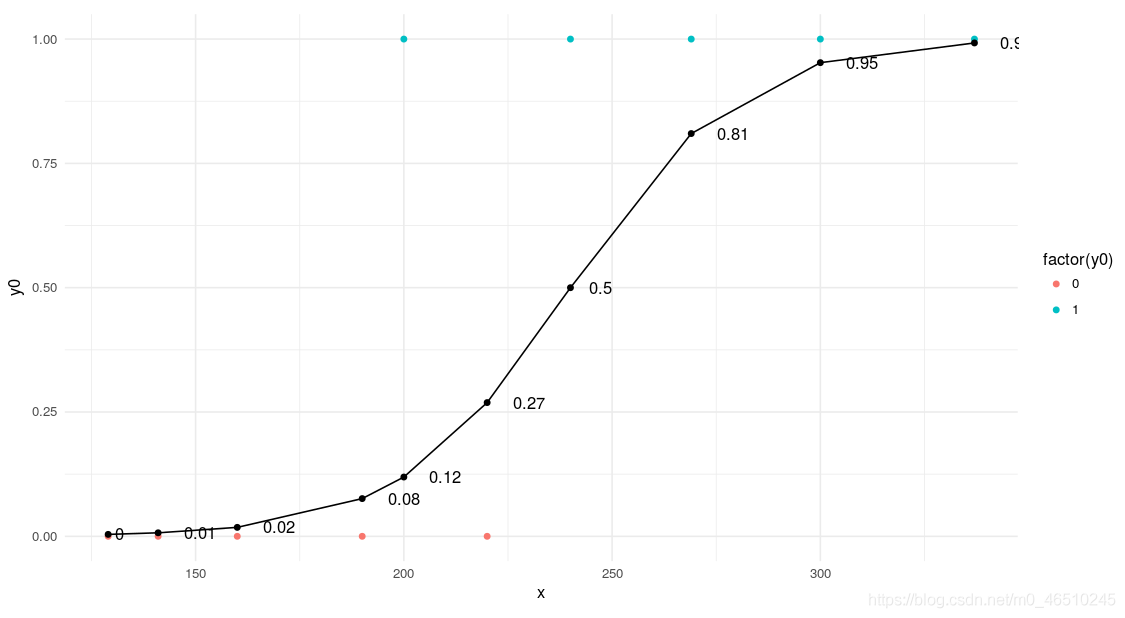
? 邏輯回歸是一種基于自變數估計分類變數結果的分類演算法,它通過將資料擬合到logistic函式來預測某一事件發生的概率,通過最大化似然函式,對logistic函式中自變數的系數進行優化,優化決策邊界,使成本函式最小,利用梯度下降法可以使代價函式最小化,
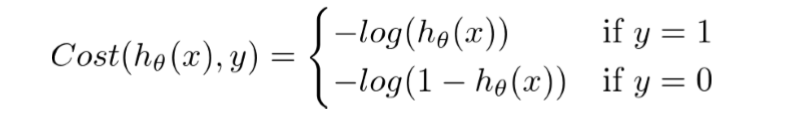
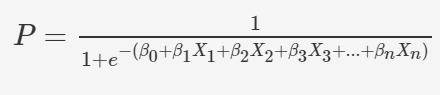
樸素貝葉斯演算法
? 樸素貝葉斯是一種基于貝葉斯定理的分類演算法,該演算法假設自變數之間不存在相關性,也就是說,一個類中某個特性的出現與同一類中另一個特性的出現是沒有關系的,我們針對類為所有預測器創建一個頻率表(目標變數的不同值),并計算所有預測器的可能性,利用樸素貝葉斯方程,計算所有類別的后驗概率,樸素貝葉斯分類器的結果將是所有類概率中概率最高的類,

決策樹
? 決策樹主要用于分類問題,但它們也可以用于回歸,在該演算法中,我們根據有效性劃分資料集的屬性,將資料集劃分為兩個或多個同構集,選擇將分割資料集的屬性的方法之一是計算熵和資訊增益,熵反映了變數中雜質的數量,資訊增益是父節點的熵減去子節點的熵之和,選擇提供最大資訊增益的屬性進行分割,我們也可以使用基尼指數作為雜質標準來分割資料集,為了防止過度分割,我們優化了max_features、min_samples_split、max_depth等決策樹的超引數,
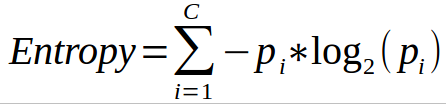
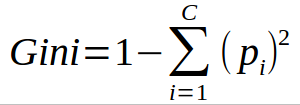
隨機森林
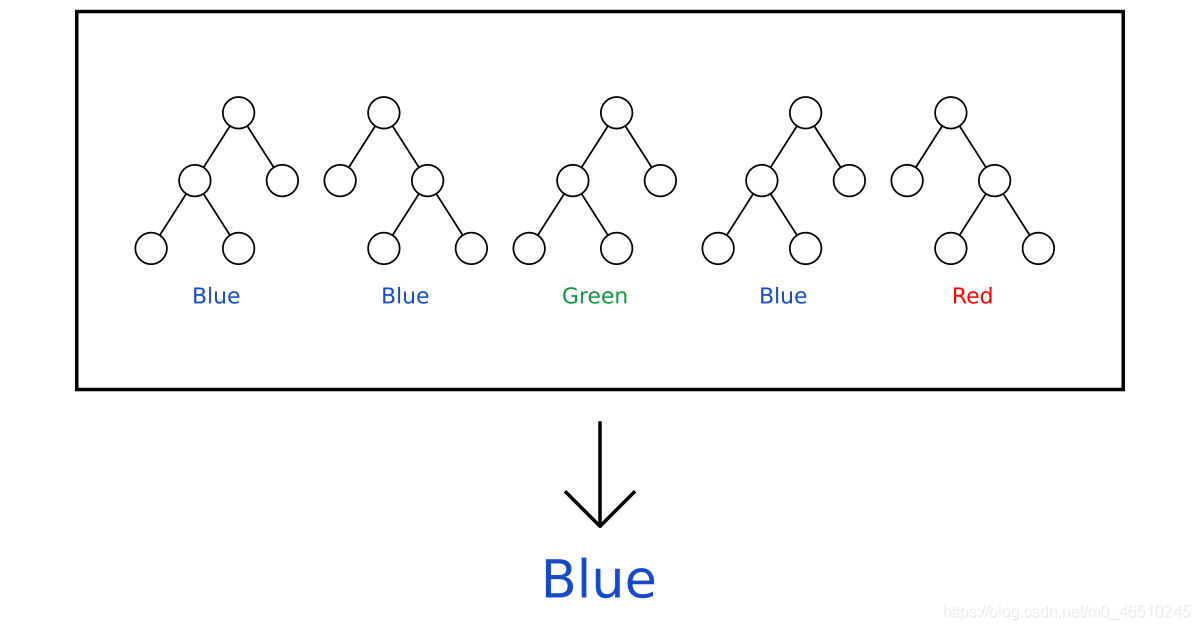
? 隨機森林由多個決策樹組成,作為一個集合來運行,在隨機森林中,每棵決策樹預測一個類結果,投票最多的類結果成為隨機森林的預測項,為了做出準確的預測,決策樹之間的相關性應該最小,有兩種方法可以確保這一點,即使用Bagging和特性選擇,Bagging是一種從資料集中選擇隨機觀察樣本的技術,特征選擇允許決策樹僅在特征的隨機子集上建模,這就防止決策樹使用相同的特性進行預測的情況,
k-NN (k - Nearest Neighbors)
? 該演算法也可用于回歸和分類,該演算法通過計算資料點與所有資料點的距離來找到k個資料點的最近鄰,資料點被分配給k個鄰居中點數最多的類(投票程序),在回歸的情況下,它計算k個最近鄰居的平均值,距離度量可以使用歐幾里得距離,曼哈頓距離,閔可夫斯基距離等,為了消除距離相等的可能,k的值必須是一個奇數,由于每個資料點與其他資料點的距離都需要計算,因此該演算法的計算時間開銷較大,

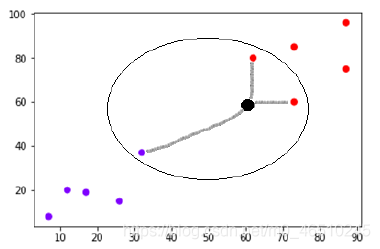
K-Means
? K-Means是一種無監督學習演算法,用于形成資料簇,形成的集群應該使集群內的資料點盡可能相似,集群之間的差異盡可能明顯,它隨機選擇K個位置,每個位置作為一個簇的質心,資料點被分配到最近的簇,在分配資料點之后,計算每個聚類的質心,再次將資料點分配到最近的聚類中,此程序將重復進行,直到在每次連續迭代中資料點保持在同一簇中,或簇的中心不改變為止,我們還可以指示演算法在進行一定次數的迭代后停止計算,
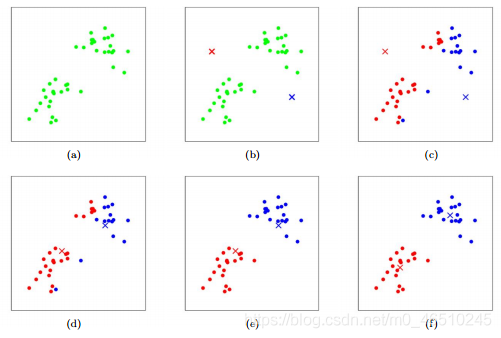
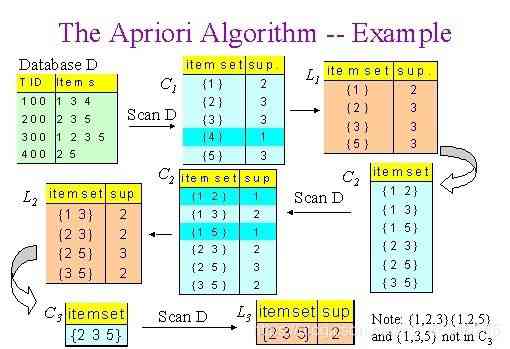
Apriori演算法
? Apriori演算法是一種基于關聯規則的資料庫頻繁項集識別演算法,頻繁項集是支持度大于閾值的項集,關聯規則可以被認為是一種IF-THEN關系,它通常用于市場籃子分析中,發現不同商品之間的關聯,支持、置信度和提升是幫助確定關聯的三個措施,
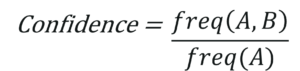
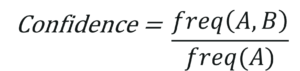
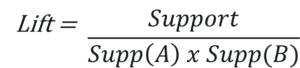
? 支持指某些專案集一起出現的頻率,
? 置信度計算專案集在其中一個專案出現的概率,
? 提升表示關聯規則的強度,支持是用戶定義的閾值,
XGBoost
? XGBoost是一種基于決策樹的梯度增強演算法(集成的另一種型別),XGBoost涉及一組較弱的學習者,它們結合在一起可以做出準確的預測,Boosting是一個序列集成,每個模型都是在修正之前模型錯誤分類的基礎上構建的,換句話說,它接收到前一個模型的錯誤,并試圖通過學習這些錯誤來改進模型,

支持向量機(SVM)
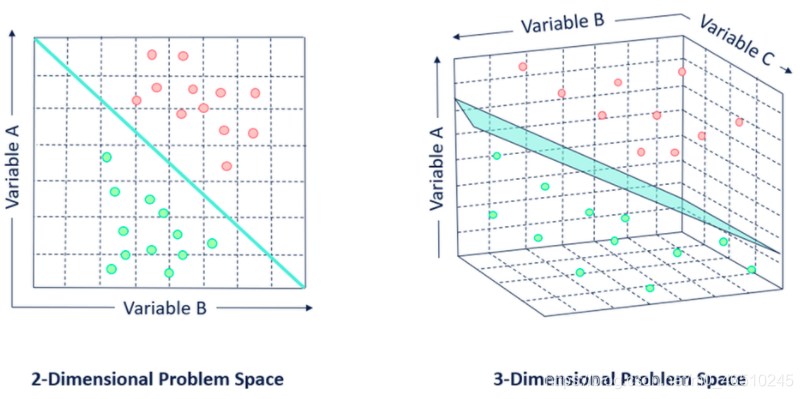
? SVM也是一種監督學習演算法,可用于分類和回歸問題,支持向量機試圖在N維空間(N指特征的數量)中找到一個最優超平面來幫助分類,它利用鉸鏈損失函式,通過最大化類觀測值之間的裕度距離來尋找最優超平面,超平面的維數取決于輸入特征的數量,如果特征個數為N,則超平面的維數為N-1,
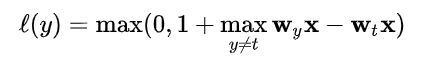
? 感謝您閱讀本文,
作者:Prathamesh Thakar
deephub翻譯組:孟翔杰
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/1444.html
標籤:其他
上一篇:資料產品-資料化產品應用
下一篇:Jmeter常用引數化設定