TAMER——Training an Agent Manually Via Evaluative Reinforcement
如今,盡管計算機系統及技術在許多方面已經超越人類,但在許多領域和任務中,人類的專業知識仍然是必不可少的,而TAMER正是這樣一個框架,使得人類的知識可以對計算機模型進行訓練,以達到節約訓練成本,迅速收斂的效果,
一、什么是TAMER?
TAMER是由Bradley等人于2008年提出的一種學習框架Training an Agent Manually Via Evaluative Reinforcement,該框架將人類專家引入到Agents的學習回圈中,可以通過人類向Agents提供獎勵信號(即指導Agents進行訓練),從而快速達到任務目標,
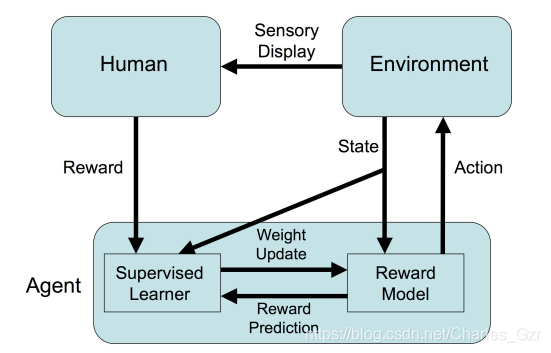
二、為什么要使用TAMER?它有什么優勢?
盡管強化學習等技術在各個領域大放異彩,但是仍然存在著許多問題,比如收斂速度慢,訓練成本高等特點,然而,在現實世界中,許多任務的探索成本很高,比如,某些任務可能會導致Agents的材料消耗巨大,出現死亡等風險,在金融市場中,一次錯誤的交易很可能會引起重大的損失,所以,如何加快訓練效率,是如今強化學習任務待解決的重要問題之一,
而TAMER則可以將人類的知識通過獎勵信號的方式訓練Agent,使其快速收斂,它與Advice-taking agents, learning by human example等其它的人類參與訓練的框架相比,它并不需要訓練人員具有非常強的專業知識以及編程技術,更加簡單易于實作,在傳統的Advice-taking agents方法中,訓練者往往要求與領域相關的專業技術、編程技術,并且需要向計算機提供獎勵信號的原因,learning by human example同時也需要訓練者具有很強的專業能力,而TAMER很多時候則僅僅需要培訓人員簡單的辨別好或者壞,
三、TAMER需要滿足的條件是什么?
1.任務是確定性的,
2.兩次操作之間有足夠的時間讓培訓師提供反饋,
四、TAMER的執行程序
我覺得在論文中的偽代碼很容易理解,所以我想通過解釋偽代碼的形式來展示TAMER框架的執行程序,
TAMER框架由3個部分組成,它們分別是RunAgent(), UpdateRewardModel(), ChooseAction().
其中:
- RunAgent()負責整體代碼的初始化以及運行
- UpdateRewardModel()負責對人類給予的獎勵信號的權重向量進行更新
- ChooseAction().負責選擇下一步Agent的動作
下面將詳細說明:
①RunAgent()

如圖所示,
t
t
t表示為時間,也可以理解為迭代的當前次數,Agent每選擇一個動作至整個loop完成后,t都會+1,在RunAgent()函式中,
t
t
t初始化為0,
w
?
\vec{w}
w
表示人類給予的獎勵信號的權重向量,
f
t
?
1
?
\vec{f_{t-1}}
ft?1?
?表示t-1時刻的狀態特征(可以理解為t-1時刻的狀態,這個狀態被當成一個個的特征進行表示,比如在俄羅斯方塊中,這個特征向量中則可以包含每一列的高度以及各列之間的高度差),
f
t
?
2
?
\vec{f_{t-2}}
ft?2?
?表示t-2時刻的狀態特征,
w
?
\vec{w}
w
,
f
t
?
1
?
\vec{f_{t-1}}
ft?1?
?,
f
t
?
2
?
\vec{f_{t-2}}
ft?2?
?維度相等,都被初始化為對應數量的0向量,如Algorithm 1的第5行所示,首先從ChooseAction()中選取一個action并執行,
第6行 takeaction()代表執行這個動作,
第8行,之后整個執行程序進入了一個回圈,
第10行,從人類的反饋中得到
r
t
?
2
{r_{t-2}}
rt?2?,getHUmanFeedback()這個函式因任務的不同而有所不同,
第11,12行,如果
r
t
?
2
{r_{t-2}}
rt?2?不等于0,即這個環節有人類的指導信號,則繼續更新獎勵信號權重向量
w
?
\vec{w}
w
,如果為0,則表明可能這一輪的回圈中,人類并沒有給出獎勵建議或者說并沒有參與指導,則不會更新
w
?
\vec{w}
w
,
②UpdateRewardModel()

在12行的時候,主函式呼叫了Algorithm 2,即UpdateRewardModel(),它的輸入引數為人類獎勵信號
r
t
?
2
{r_{t-2}}
rt?2?,
w
?
\vec{w}
w
,
f
t
?
1
?
\vec{f_{t-1}}
ft?1?
?,
f
t
?
2
?
\vec{f_{t-2}}
ft?2?
?,以及學習率
α
\alpha
α,
第二行,
Δ
f
t
?
1
,
t
?
2
?
\vec{\Delta f_{t-1, t-2}}
Δft?1,t?2?
?為
f
t
?
1
?
\vec{f_{t-1}}
ft?1?
?,
f
t
?
2
?
\vec{f_{t-2}}
ft?2?
?的差值,它代表著兩個狀態之間的變化情況,
第三行,
p
r
o
j
e
c
t
e
d
R
e
w
t
?
2
projectedRew_{t-2}
projectedRewt?2?表示為預測的獎勵,為輸入的獎勵權重
w
?
\vec{w}
w
與
Δ
f
t
?
1
,
t
?
2
?
\vec{\Delta f_{t-1, t-2}}
Δft?1,t?2?
?的累加乘積,(即如果
f
t
?
2
?
\vec{f_{t-2}}
ft?2?
?有20個狀態特征,那么則有20個特征與
w
?
\vec{w}
w
的乘積累加)
第四行,由人類提供的獎勵信號減去預測的獎勵信號,則可以得到它們之間的一個誤差,
第5,6行,通過這個誤差,對新的獎勵權重進行更新,
③ChooseAction()

在主函式(RunAgent())第12行完成后,回到主函式第13行,呼叫ChooseAction()函式,它的作用是選擇下一步動作,
在這個函式中,需要輸入的是當前狀態
s
t
s_t
st?以及獎勵向量
w
?
\vec{w}
w
第一行,
g
e
t
F
e
a
t
u
r
e
V
e
c
(
s
t
)
getFeatureVec(s_t)
getFeatureVec(st?)的作用是從狀態
s
t
s_t
st?中獲取狀態特征
f
t
?
\vec{f_t}
ft?
?
第2,3,4,5,6行,從該狀態中執行所有動作并計算預期獎勵,
第三行中
T
(
s
t
,
a
)
T(s_t,a)
T(st?,a)為狀態轉移方程(已知的),它可以通過當前的狀態以及所執行的操作得到t+1時刻執行a操作的狀態
s
t
+
1
,
a
?
\vec{s_{t+1},a}
st+1?,a
?
第四行通過狀態特征轉化方程得到t+1時刻執行a操作的狀態特征
f
t
+
1
,
a
?
\vec{f_{t+1},a}
ft+1?,a
?
第五行得到
f
t
+
1
,
a
?
\vec{f_{t+1},a}
ft+1?,a
?與
f
t
?
\vec{f_t}
ft?
?的差值(類似UpdateRewardModel()中的第二行)
第六行則利用該差值計算t時刻執行每個動作后的預測獎勵
p
r
o
j
e
c
t
e
d
R
e
w
a
projectedRew_{a}
projectedRewa?
最后,ChooseAction()函式的回傳值即是另
p
r
o
j
e
c
t
e
d
R
e
w
a
projectedRew_{a}
projectedRewa?最大的動作a,
之后,回傳到主函式執行其余操作,執行動作a,得到新的state,并更新 f t ? 1 ? \vec{f_{t-1}} ft?1? ?, f t ? 2 ? \vec{f_{t-2}} ft?2? ?,
以上就是TAMER框架執行的全部程序,
四、總結
TAMER框架使人類參與到Agent訓練程序中成為可能,它與傳統強化學習技術的區別是它考慮的僅僅是即時獎勵,而強化學習技術則考慮長遠的收益,它具有收斂速度快,訓練成本低的特點,但是同時,也有學者論證,它的長期學習能力并不如強化學習,所以將各種技術融合可能才是未來的趨勢,
原文地址:
https://www.cs.utexas.edu/~bradknox/papers/icdl08-knox.pdf
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/173810.html
標籤:其他
上一篇:勒讓德多項式的正交性和歸一化